Fantastic paper from ByteDance 👏
Shows how to train LLM agents to finish long, multi step tasks by letting them act in real environments with reinforcement learning.
Across 27 tasks, the trained agents rival or beat top proprietary models.
Most agents are trained on single turn data, so they fail when a job needs many decisions with noisy feedback.
AgentGym-RL splits the system into separate parts, the environments, the agent loop, and training, so each can improve on its own.
It supports mainstream algorithms and realistic tasks, and the agent learns by acting, seeing results, and adjusting across different settings.
The key method, ScalingInter-RL, starts with short interactions to master basics, then slowly allows longer runs so the agent can explore and plan.
This staged horizon schedule stabilizes learning, prevents pointless loops, and encourages planning, reflection, and recovery after mistakes.
A 7B model trained with this setup matches or beats much larger open models and competes well with strong commercial ones.
They also find that putting more compute into training and test time interaction, like more steps or samples, often helps more than adding parameters.
Shows how to train LLM agents to finish long, multi step tasks by letting them act in real environments with reinforcement learning.
Across 27 tasks, the trained agents rival or beat top proprietary models.
Most agents are trained on single turn data, so they fail when a job needs many decisions with noisy feedback.
AgentGym-RL splits the system into separate parts, the environments, the agent loop, and training, so each can improve on its own.
It supports mainstream algorithms and realistic tasks, and the agent learns by acting, seeing results, and adjusting across different settings.
The key method, ScalingInter-RL, starts with short interactions to master basics, then slowly allows longer runs so the agent can explore and plan.
This staged horizon schedule stabilizes learning, prevents pointless loops, and encourages planning, reflection, and recovery after mistakes.
A 7B model trained with this setup matches or beats much larger open models and competes well with strong commercial ones.
They also find that putting more compute into training and test time interaction, like more steps or samples, often helps more than adding parameters.

How the AgentGym-RL framework works.
At the center is the LLM agent. It takes an instruction, interacts with an environment for several turns, and then produces actions. Each action changes the environment, and the environment sends feedback back to the agent. This cycle repeats many times.
The environment itself is handled by a server that can simulate different types of tasks. These include web browsing, searching, coding, playing games, doing science tasks, or controlling embodied agents. The environment client manages the interaction and communicates through standard protocols.
Every full cycle of actions and observations is called a trajectory. These trajectories are collected and then used to update the agent’s policy with reinforcement learning algorithms like PPO, GRPO, RLOO, or REINFORCE++.
The framework is modular. The environment, the agent, and the training part are separated. This makes it flexible, easy to extend, and suitable for many types of realistic tasks.
The diagram highlights how the agent learns not by memorizing answers, but by trying actions, getting feedback, and improving its decision making across different domains.
At the center is the LLM agent. It takes an instruction, interacts with an environment for several turns, and then produces actions. Each action changes the environment, and the environment sends feedback back to the agent. This cycle repeats many times.
The environment itself is handled by a server that can simulate different types of tasks. These include web browsing, searching, coding, playing games, doing science tasks, or controlling embodied agents. The environment client manages the interaction and communicates through standard protocols.
Every full cycle of actions and observations is called a trajectory. These trajectories are collected and then used to update the agent’s policy with reinforcement learning algorithms like PPO, GRPO, RLOO, or REINFORCE++.
The framework is modular. The environment, the agent, and the training part are separated. This makes it flexible, easy to extend, and suitable for many types of realistic tasks.
The diagram highlights how the agent learns not by memorizing answers, but by trying actions, getting feedback, and improving its decision making across different domains.

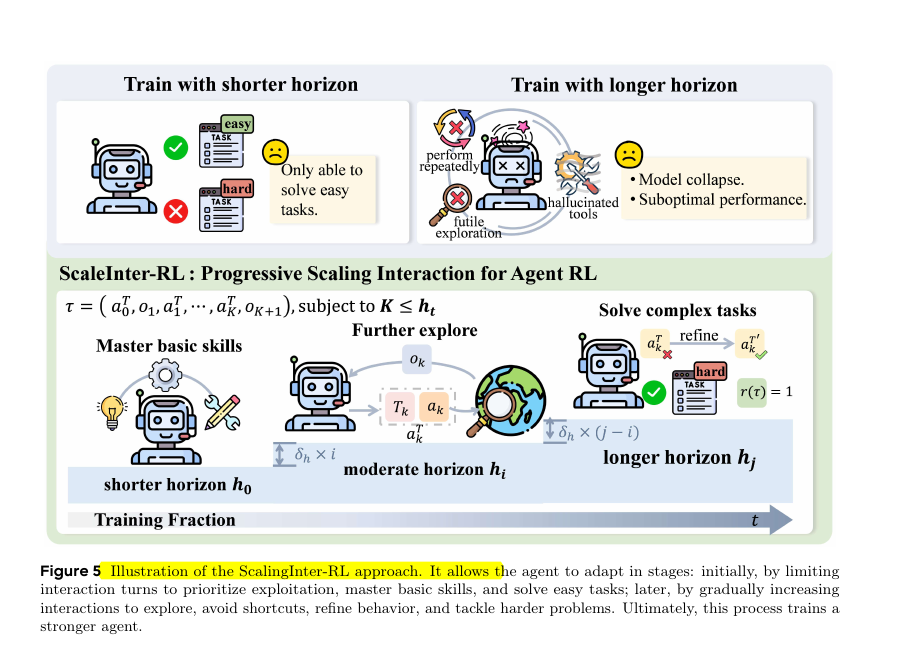
The idea behind ScalingInter-RL, the training method used in the paper.
If an agent is trained with only short interactions, it learns to handle easy tasks but fails on harder ones. If it is trained with very long interactions from the start, it wastes effort, falls into repeated mistakes, or even collapses and performs poorly.
ScalingInter-RL solves this by gradually increasing the number of interaction steps during training. At first, the agent works with short horizons to master the basics and build reliable skills.
Then, the horizon is expanded in stages, letting the agent explore more, refine its behavior, and learn how to recover from errors.
By the final stages, the agent can manage long, complex tasks because it has grown its abilities step by step instead of being overloaded too early. This staged process makes training stable and produces stronger agents.
If an agent is trained with only short interactions, it learns to handle easy tasks but fails on harder ones. If it is trained with very long interactions from the start, it wastes effort, falls into repeated mistakes, or even collapses and performs poorly.
ScalingInter-RL solves this by gradually increasing the number of interaction steps during training. At first, the agent works with short horizons to master the basics and build reliable skills.
Then, the horizon is expanded in stages, letting the agent explore more, refine its behavior, and learn how to recover from errors.
By the final stages, the agent can manage long, complex tasks because it has grown its abilities step by step instead of being overloaded too early. This staged process makes training stable and produces stronger agents.
Paper –
Paper Title: "AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning"arxiv.org/abs/2509.08755
Paper Title: "AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning"arxiv.org/abs/2509.08755
• • •
Missing some Tweet in this thread? You can try to
force a refresh