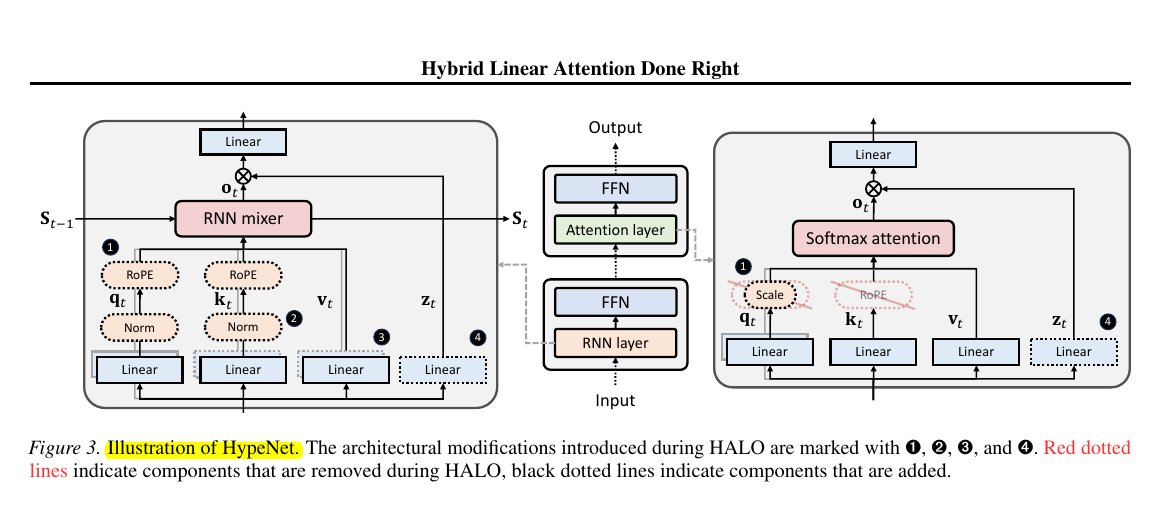
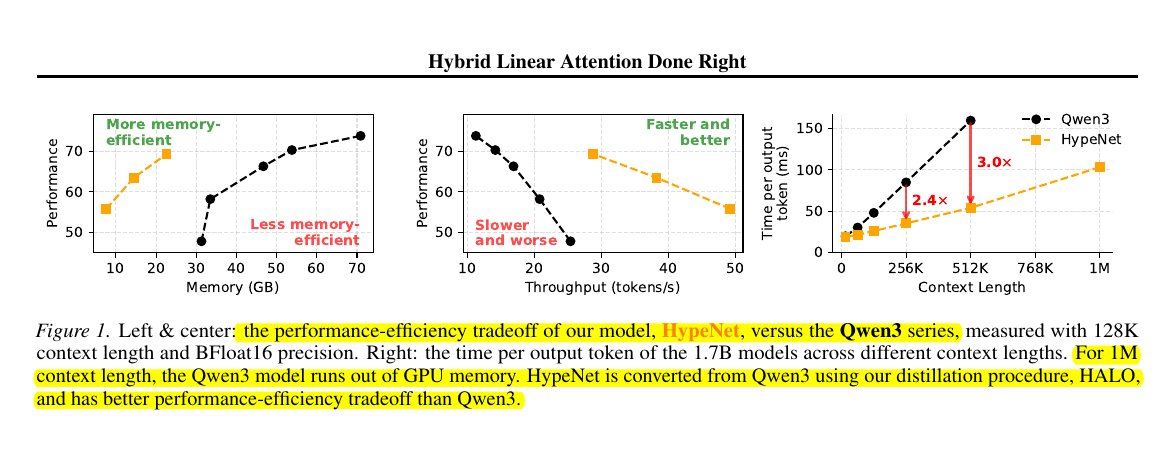
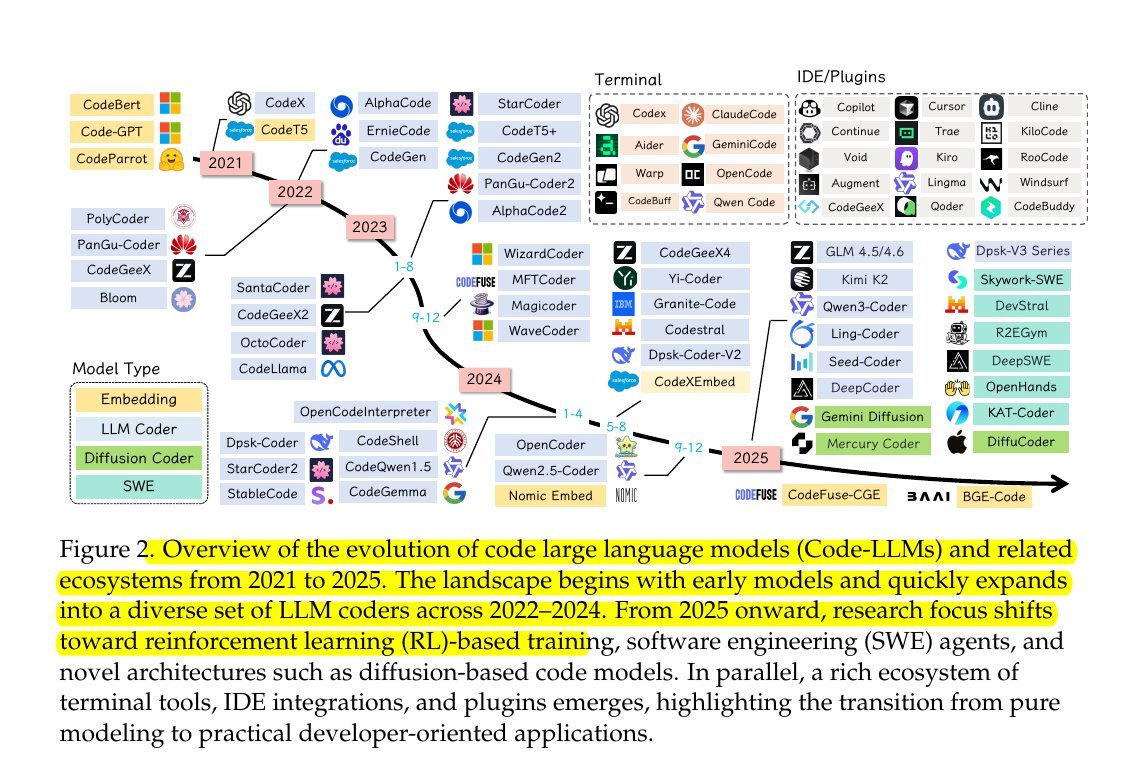
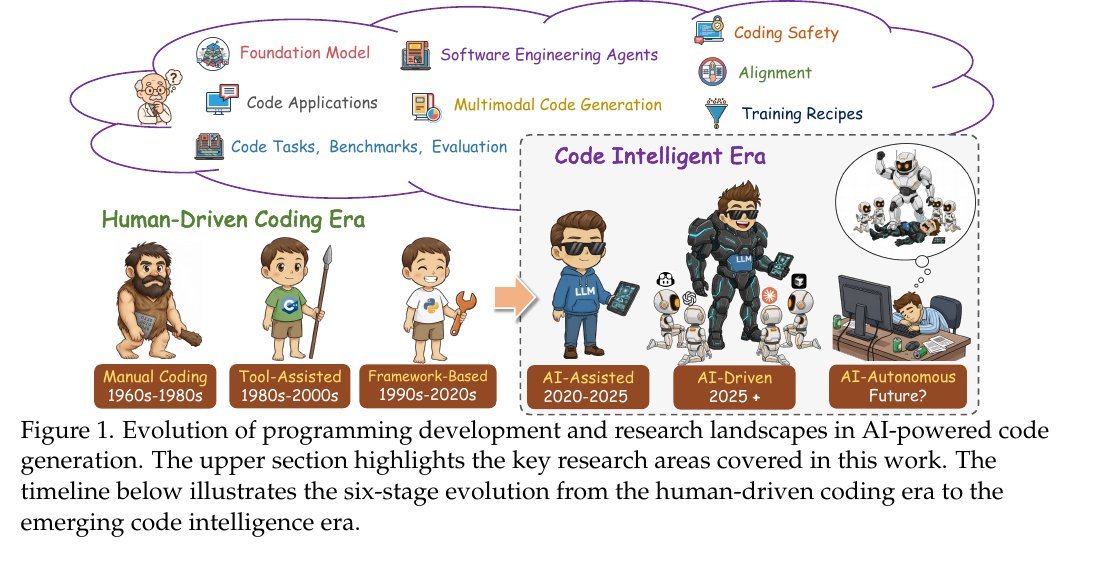
Congrats to @CreaoAI for hitting #1 on Product Hunt (Sept 11) 🚀
just used it myself, and quite smooth experience.
CREAO is an AI Agent that builds full-stack mini-SaaS from one sentence.
One sentence in → frontend + backend + data layer out.
They are building a platform to provide the critical interface for people to build apps where humans and AI agents can collaborate seamlessly.
So its entire infrastructure is engineered with an "AI-native first" philosophy.
🧵1/n.
just used it myself, and quite smooth experience.
CREAO is an AI Agent that builds full-stack mini-SaaS from one sentence.
One sentence in → frontend + backend + data layer out.
They are building a platform to provide the critical interface for people to build apps where humans and AI agents can collaborate seamlessly.
So its entire infrastructure is engineered with an "AI-native first" philosophy.
🧵1/n.
🧵2/n. ⚡ All-in-one build.
CREAO gave me a deployable product — frontend, backend, database together.
#1 on Product Hunt (Sept 11).
CREAO gave me a deployable product — frontend, backend, database together.
#1 on Product Hunt (Sept 11).

🧵3/n. 🔌 I connected real-time APIs via the MCP marketplace.
In my view, this is where AI tooling has to go: not isolation, but live data + integrations.
In my view, this is where AI tooling has to go: not isolation, but live data + integrations.
🧵4/n. 🤖 The built-in Copilot made data handling zero-effort.
I asked it to summarize usage stats — done in one click.
Feels like having a junior data analyst inside every mini-SaaS.
I asked it to summarize usage stats — done in one click.
Feels like having a junior data analyst inside every mini-SaaS.
🧵5/n. 🌍 Share instantly.
I sent my project to peers, and they could try it right away.
Frictionless.
I sent my project to peers, and they could try it right away.
Frictionless.
• • •
Missing some Tweet in this thread? You can try to
force a refresh