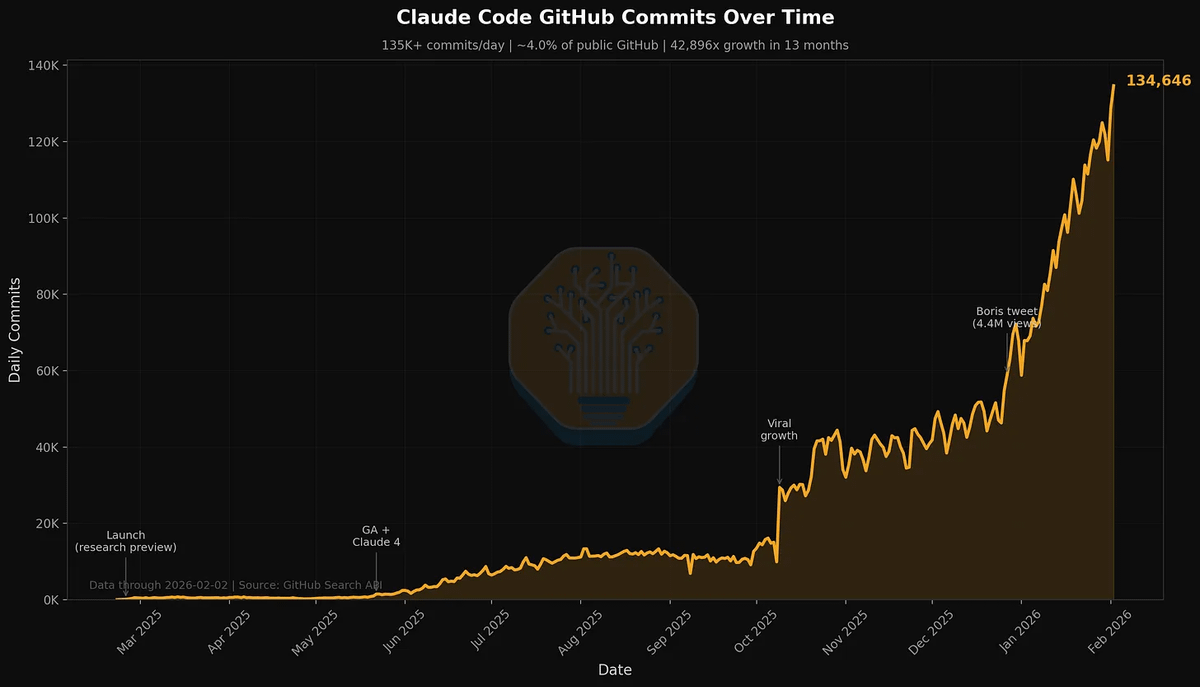
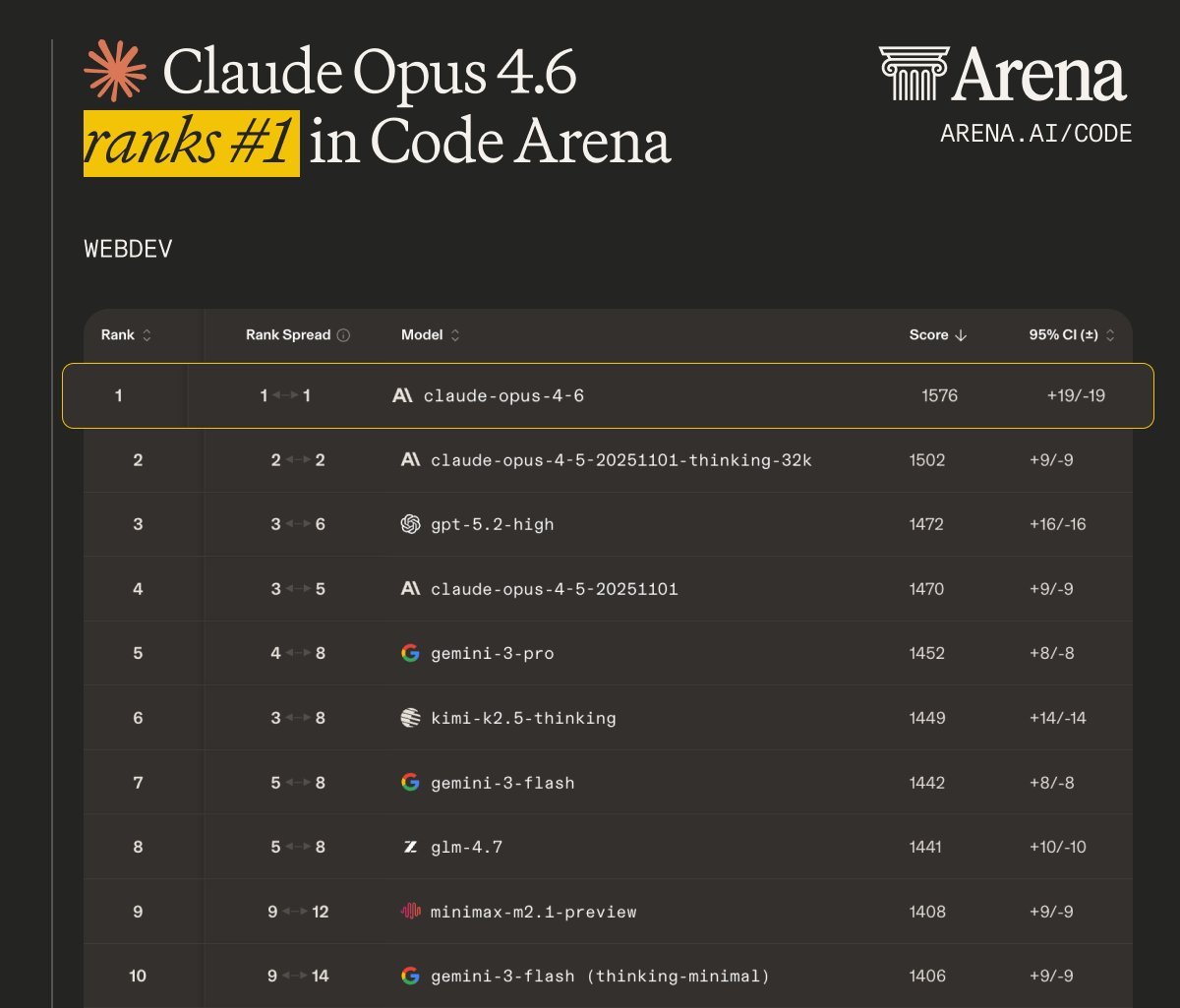
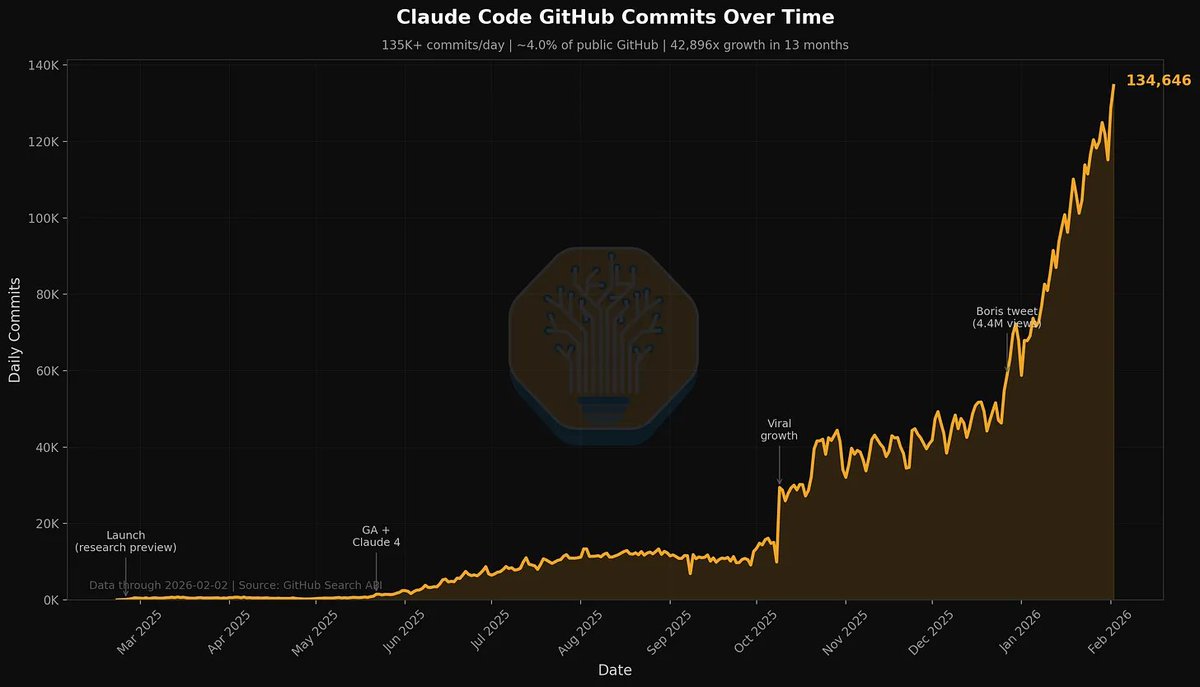
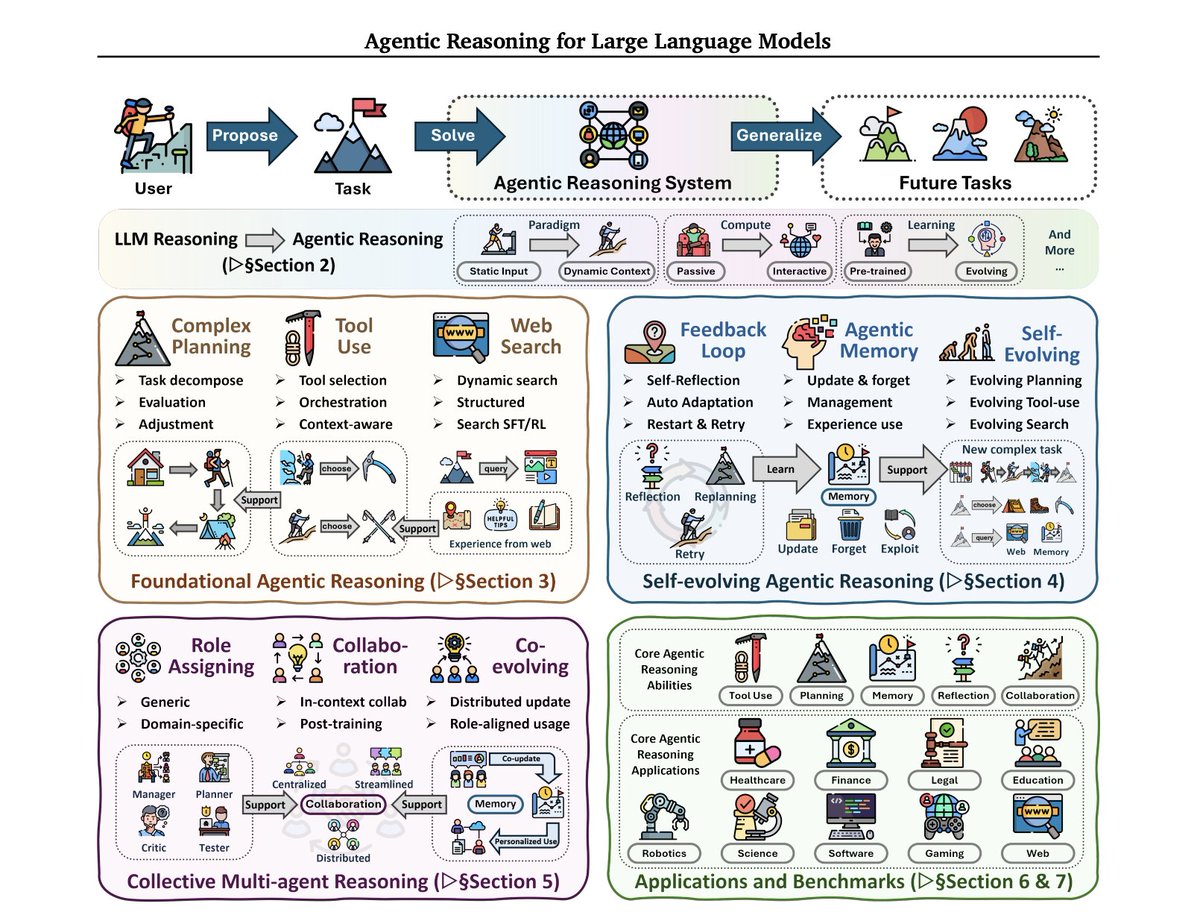
Fuck it.
I'm sharing the 10 Gemini prompts that built my entire SaaS from scratch.
These prompts literally replaced my CTO, lead dev, and product manager.
Comment 'send' and I'll DM you the complete Gemini guide to master it:
I'm sharing the 10 Gemini prompts that built my entire SaaS from scratch.
These prompts literally replaced my CTO, lead dev, and product manager.
Comment 'send' and I'll DM you the complete Gemini guide to master it:
• • •
Missing some Tweet in this thread? You can try to
force a refresh