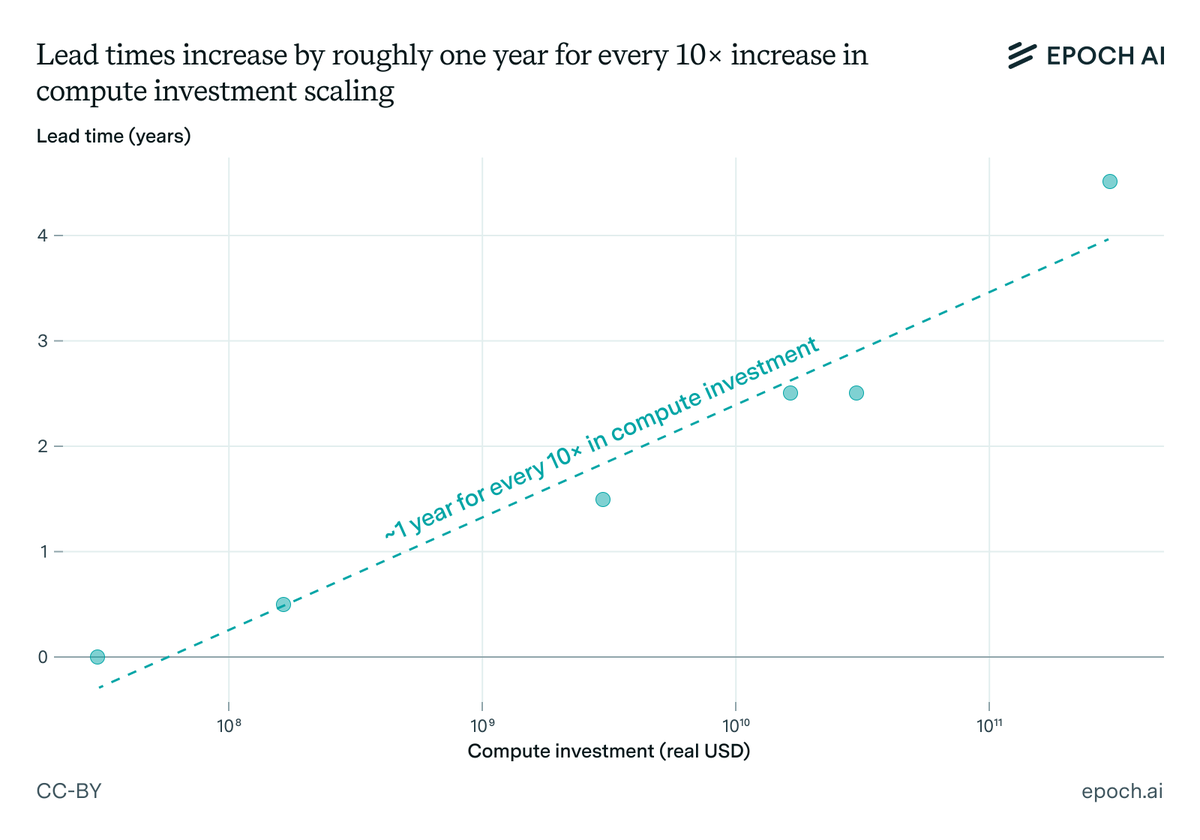
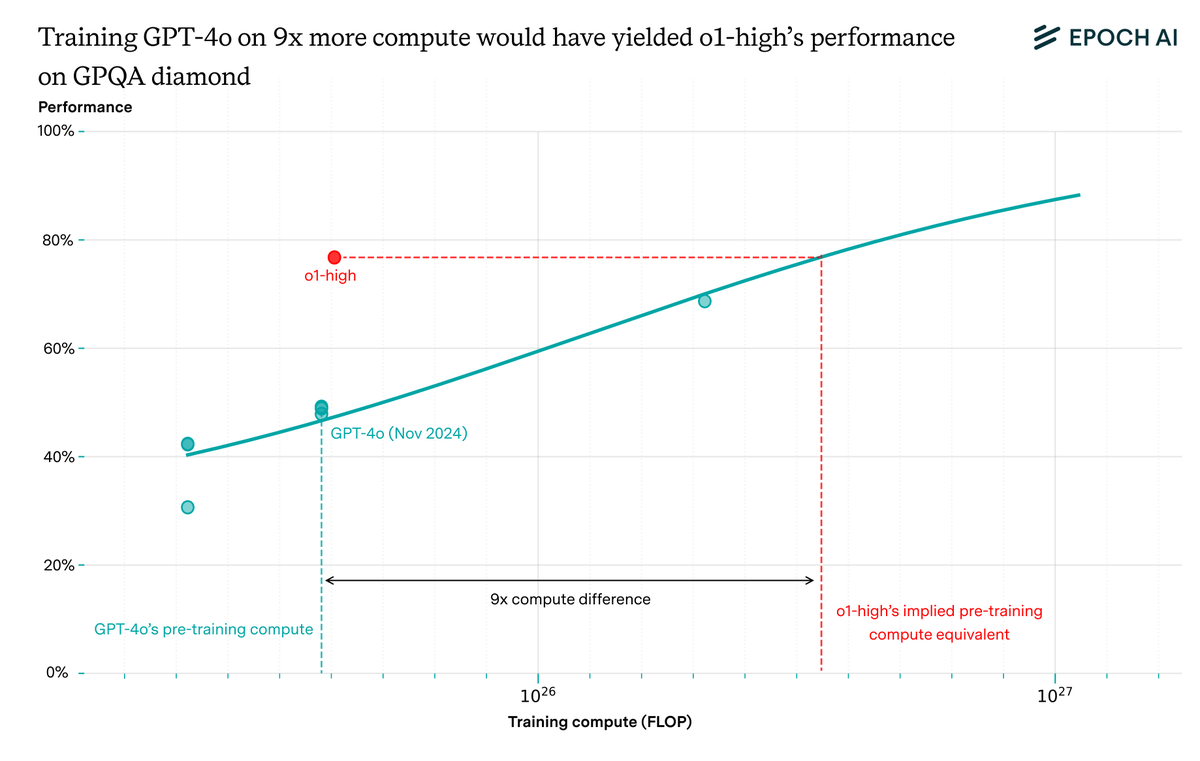
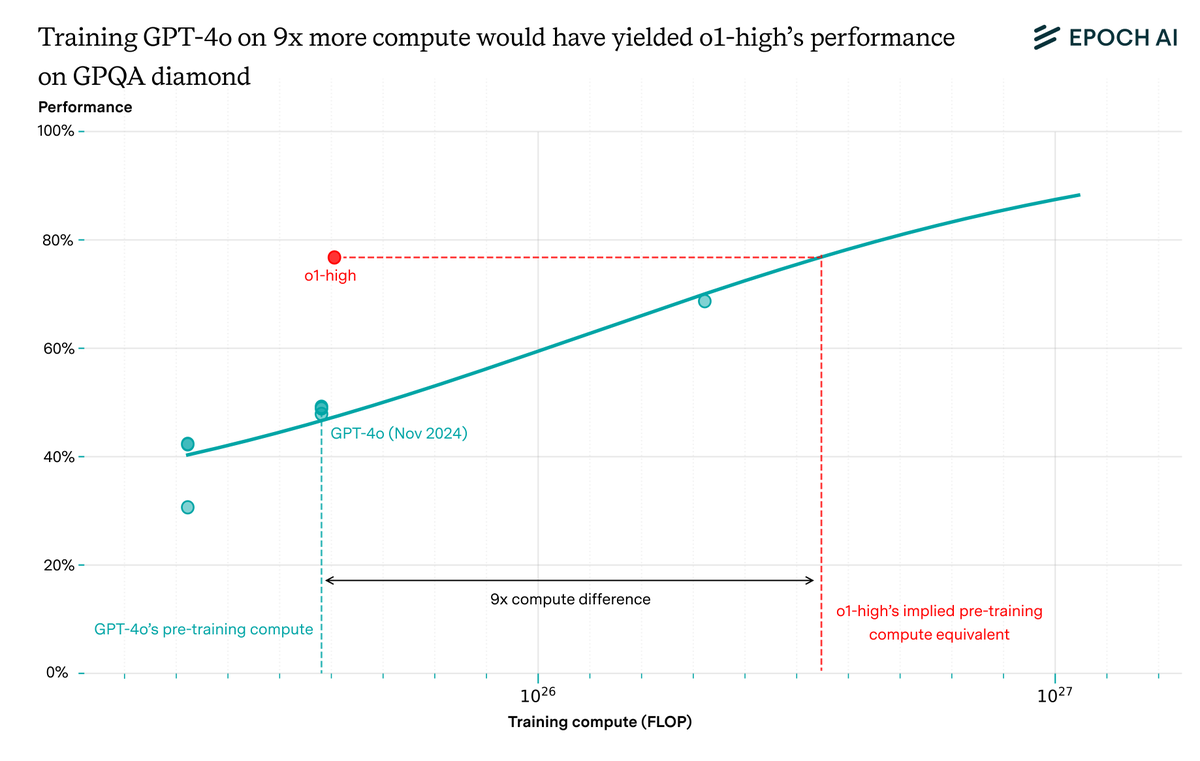
What will AI look like by 2030 if current trends hold?
Our new report zooms in on two things: (1) whether scaling continues (compute, data, power, capital), and (2) the capabilities this enables—especially for scientific R&D.
Our new report zooms in on two things: (1) whether scaling continues (compute, data, power, capital), and (2) the capabilities this enables—especially for scientific R&D.

We forecast that by 2030:
- Training clusters would cost hundreds of billions of dollars
- Compute scaling is probably not "hitting a wall"
- Synthetic & multimodal data may be needed to ease bottlenecks
- Power demands will increase but be manageable in principle
- Training clusters would cost hundreds of billions of dollars
- Compute scaling is probably not "hitting a wall"
- Synthetic & multimodal data may be needed to ease bottlenecks
- Power demands will increase but be manageable in principle




Given that we expect scaling to continue, what does this mean for the resulting AI capabilities?
We focus on scientific R&D—a stated priority for leading labs—and assess both benchmarks and real-world use, allowing us to forecast the kinds of tasks AI will be able to automate.
We focus on scientific R&D—a stated priority for leading labs—and assess both benchmarks and real-world use, allowing us to forecast the kinds of tasks AI will be able to automate.
Despite benchmarks’ weaknesses (e.g., contamination and overfitting), progress has tracked real-world improvements, and usage already supports productivity gains. People already spend billions to use AI for coding, writing, and research.
AI may be a transformative tool well before it can work autonomously.
We explore future capabilities across four domains:
- Software engineering
- Mathematics
- Biology
- Weather prediction
We explore future capabilities across four domains:
- Software engineering
- Mathematics
- Biology
- Weather prediction
AI is already transforming software engineering through code assistants and question-answering. On current trends, 2030 AI will autonomously fix issues, implement features, and solve hours-long defined problems.
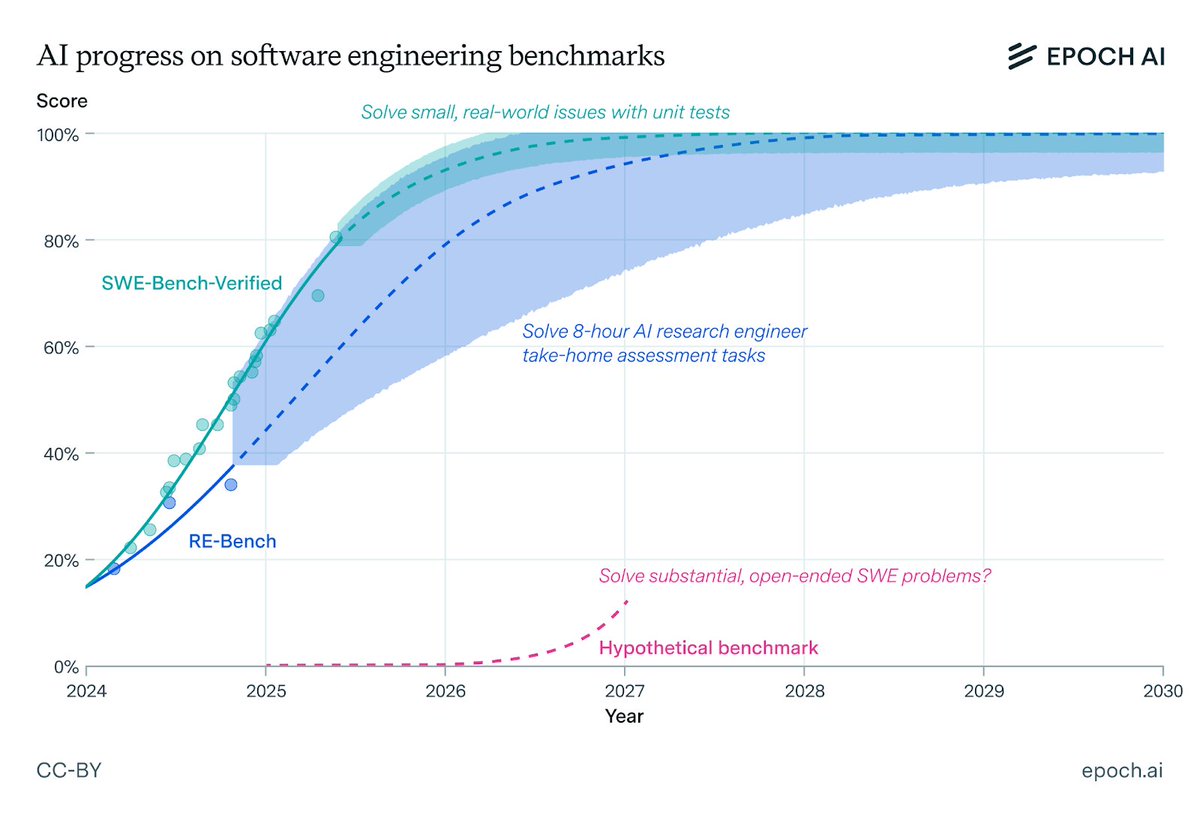
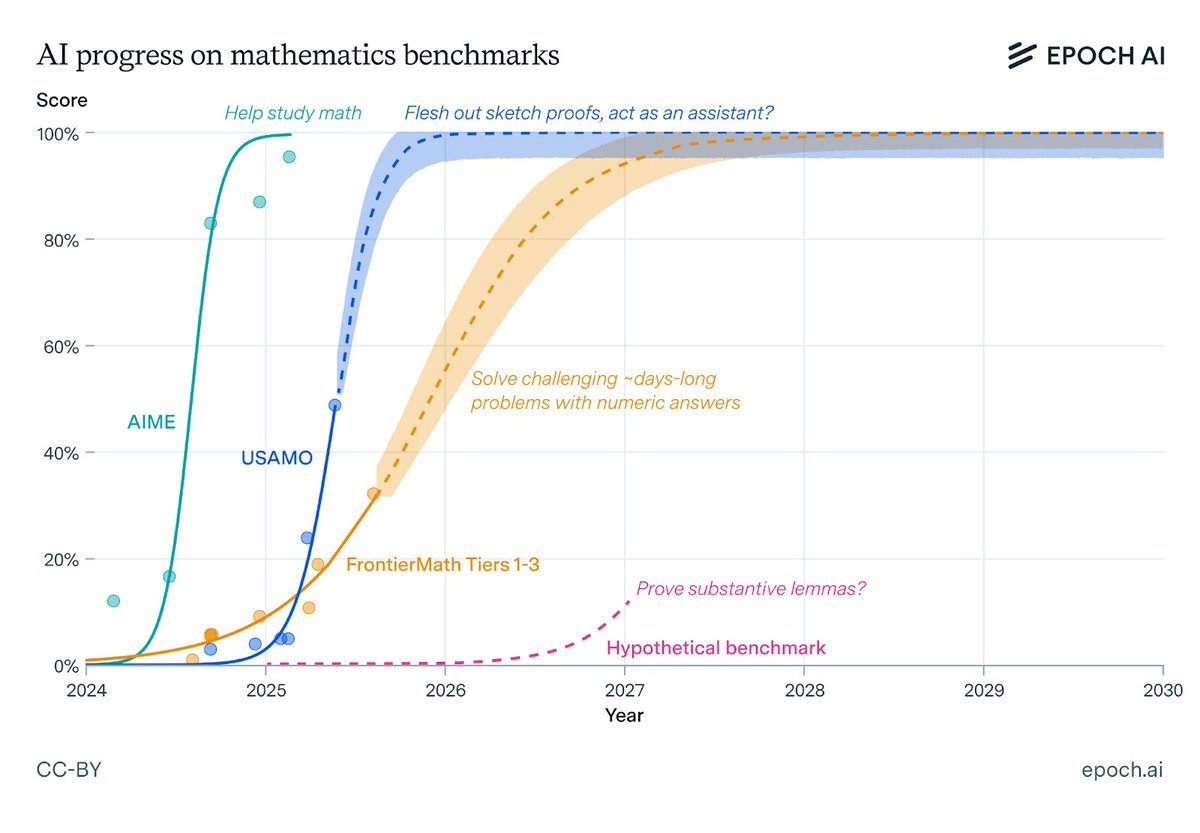
AI for mathematics may soon act as a research assistant, fleshing out proof sketches or intuitions. Mathematicians already offer examples of AI being helpful in their work, mostly for studying.
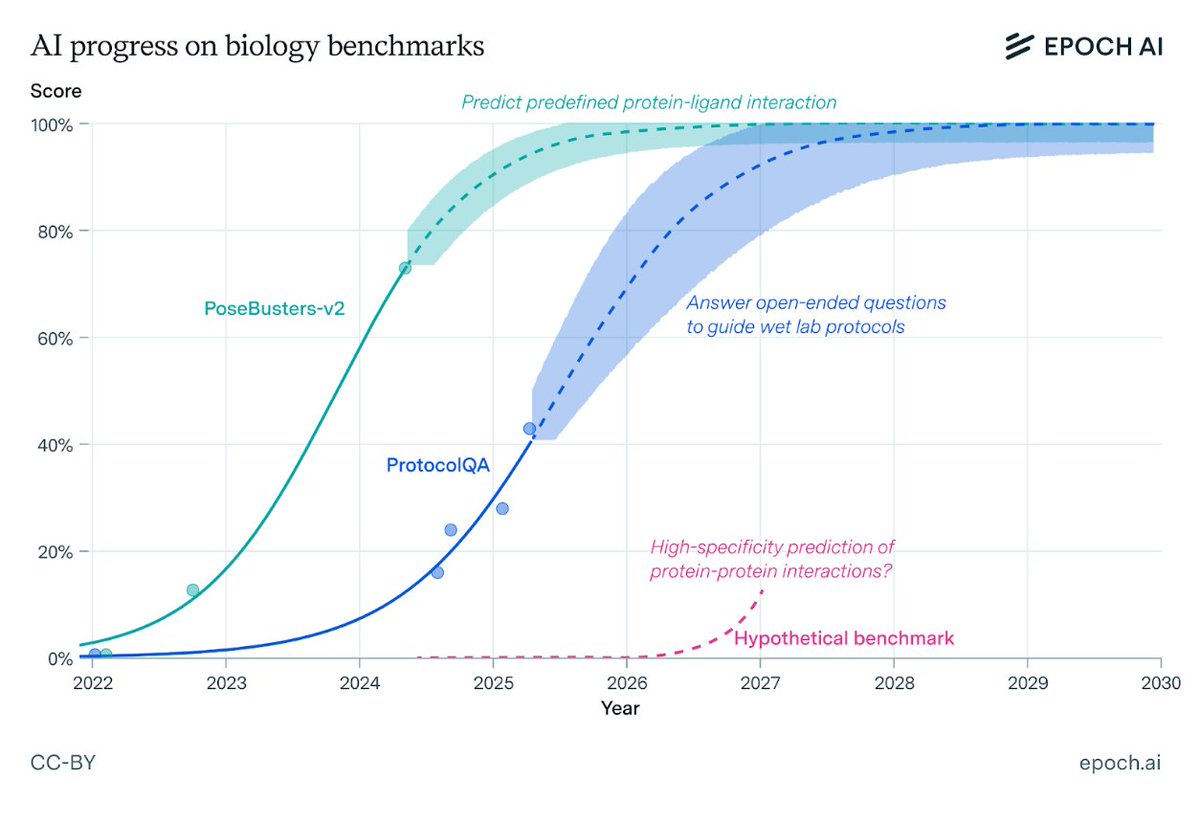
Tools like AlphaFold are already revolutionising biology, and will expand to predict more properties for more complex structures. AI assistants for desk research are at an early stage, but offer great promise.
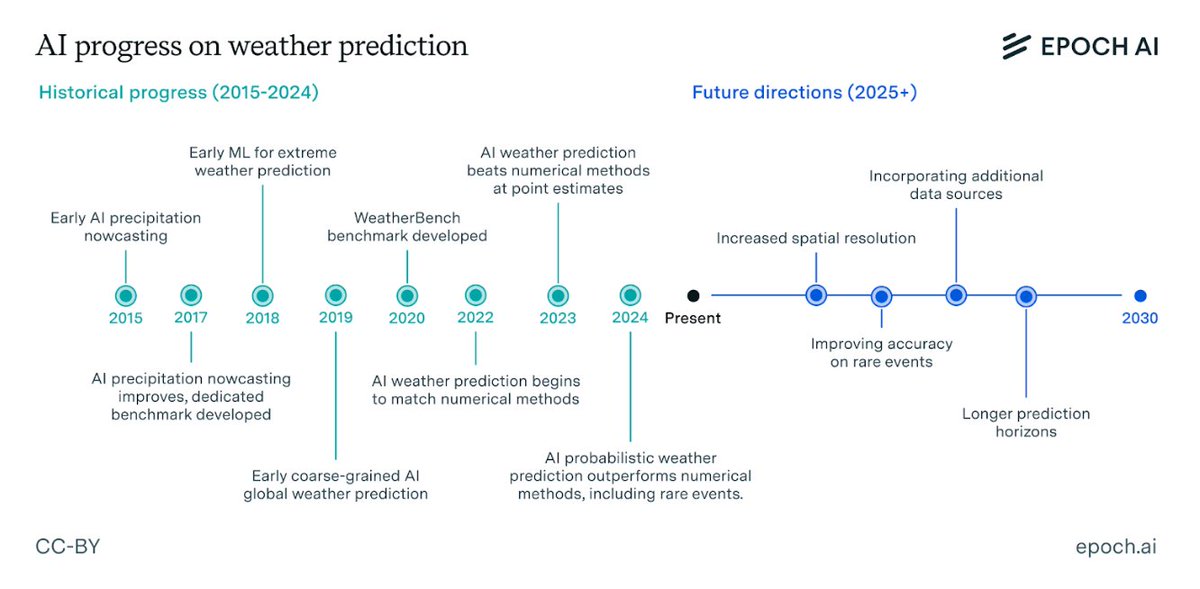
AI weather prediction already outperforms traditional methods from hours to weeks ahead. The next challenges lie in further improving predictions, especially rare events, and integrating new data sources.
At minimum, we expect that AI for scientific R&D will follow in the footsteps of coding assistants for software engineers today, boosting productivity for desk-based research by 10-20%.
Impacts may differ greatly across domains. We might see a flourishing of lab research in molecular biology for years before producing new medicines, because clinical trials and approvals take years.
For more details, check out the full report at our website: epoch.ai/blog/what-will…
For more details, check out the full report at our website: epoch.ai/blog/what-will…
This report was commissioned by @GoogleDeepMind. All points of views and conclusions expressed are those of the authors and do not necessarily reflect the position or endorsement of Google DeepMind.
Thanks to @sebkrier and @jmateosgarcia for their feedback and support.
Thanks to @sebkrier and @jmateosgarcia for their feedback and support.
• • •
Missing some Tweet in this thread? You can try to
force a refresh