🚀 Introducing Qwen3-Omni — the first natively end-to-end omni-modal AI unifying text, image, audio & video in one model — no modality trade-offs!
🏆 SOTA on 22/36 audio & AV benchmarks
🌍 119L text / 19L speech in / 10L speech out
⚡ 211ms latency | 🎧 30-min audio understanding
🎨 Fully customizable via system prompts
🔗 Built-in tool calling
🎤 Open-source Captioner model (low-hallucination!)
🌟 What’s Open-Sourced?
We’ve open-sourced Qwen3-Omni-30B-A3B-Instruct, Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner, to empower developers to explore a variety of applications from instruction-following to creative tasks.
Try it now 👇
💬 Qwen Chat: chat.qwen.ai/?models=qwen3-…
💻 GitHub: github.com/QwenLM/Qwen3-O…
🤗 HF Models: huggingface.co/collections/Qw…
🤖 MS Models:
modelscope.cn/collections/Qw…
🎬 Demo: huggingface.co/spaces/Qwen/Qw…
🏆 SOTA on 22/36 audio & AV benchmarks
🌍 119L text / 19L speech in / 10L speech out
⚡ 211ms latency | 🎧 30-min audio understanding
🎨 Fully customizable via system prompts
🔗 Built-in tool calling
🎤 Open-source Captioner model (low-hallucination!)
🌟 What’s Open-Sourced?
We’ve open-sourced Qwen3-Omni-30B-A3B-Instruct, Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner, to empower developers to explore a variety of applications from instruction-following to creative tasks.
Try it now 👇
💬 Qwen Chat: chat.qwen.ai/?models=qwen3-…
💻 GitHub: github.com/QwenLM/Qwen3-O…
🤗 HF Models: huggingface.co/collections/Qw…
🤖 MS Models:
modelscope.cn/collections/Qw…
🎬 Demo: huggingface.co/spaces/Qwen/Qw…

Use the voice chat and video chat features on Qwen Chat to experience the Qwen3-Omni model.
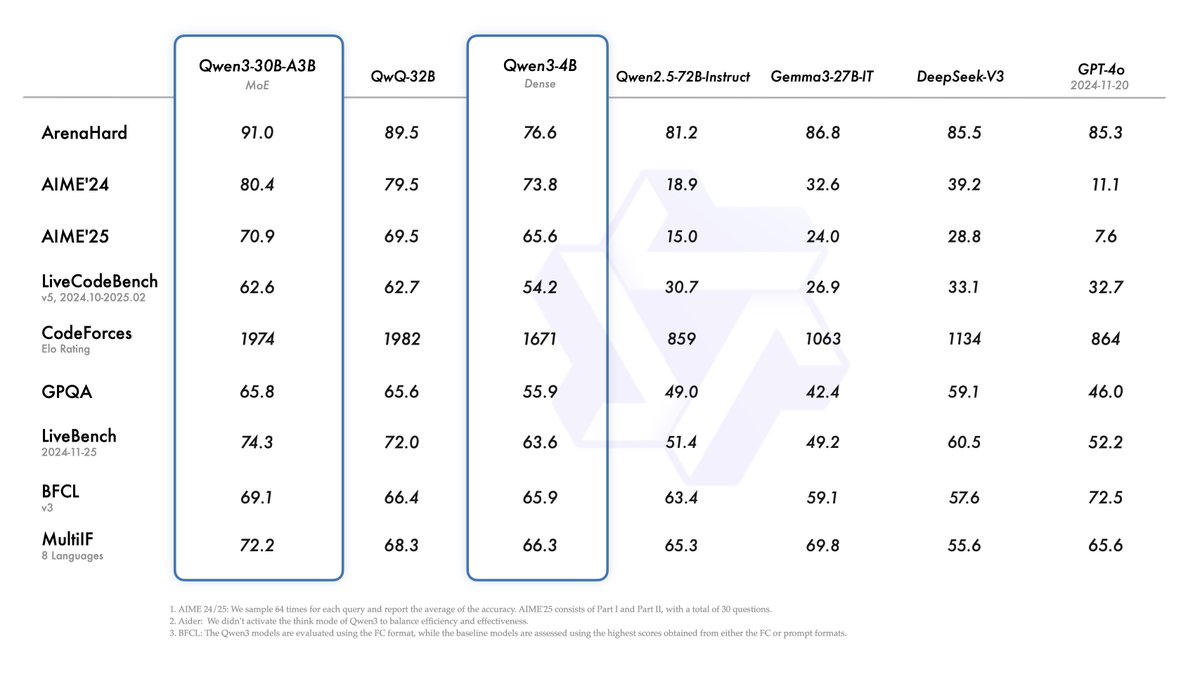
Performance

• • •
Missing some Tweet in this thread? You can try to
force a refresh