

 Qwen-RobotNav:a scalable navigation model built on Qwen3-VL that addresses this through a parameterised interface with two complementary dimensions: task modes that select the navigation behaviour, and controllable observation parameters (token budget, temporal decay, per-camera weights) that govern how visual history is encoded.
Qwen-RobotNav:a scalable navigation model built on Qwen3-VL that addresses this through a parameterised interface with two complementary dimensions: task modes that select the navigation behaviour, and controllable observation parameters (token budget, temporal decay, per-camera weights) that govern how visual history is encoded.

 Average Ranking vs. Environment Scaling
Average Ranking vs. Environment Scaling 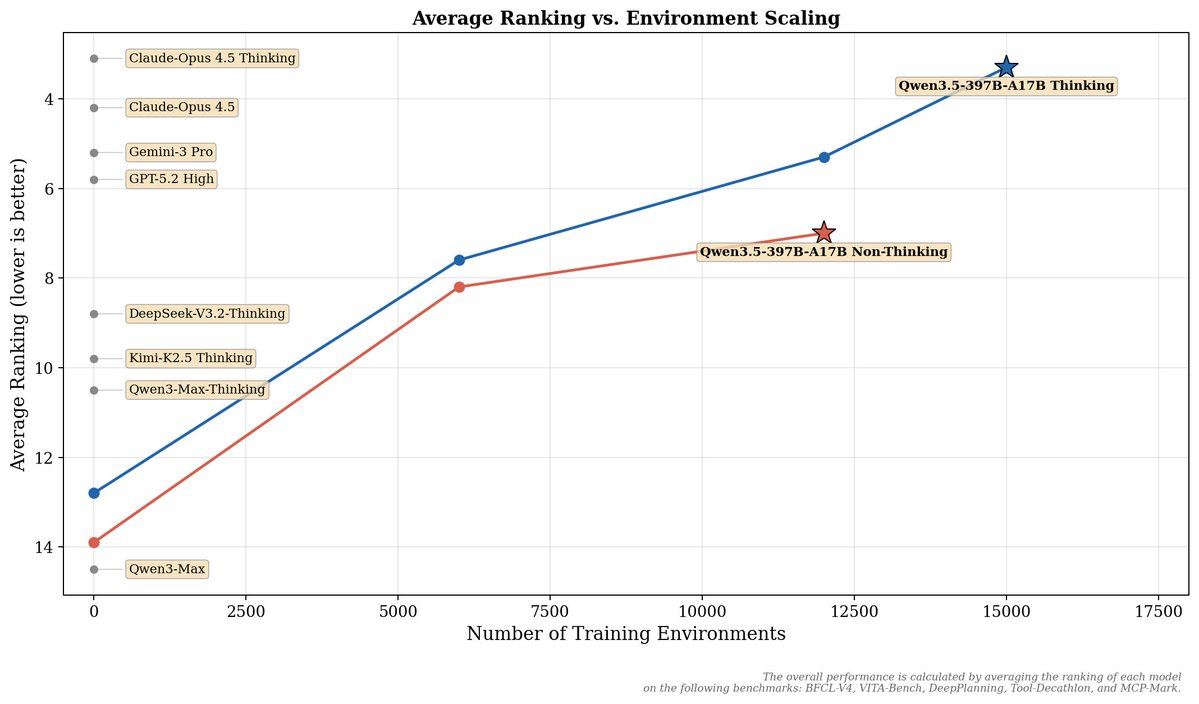

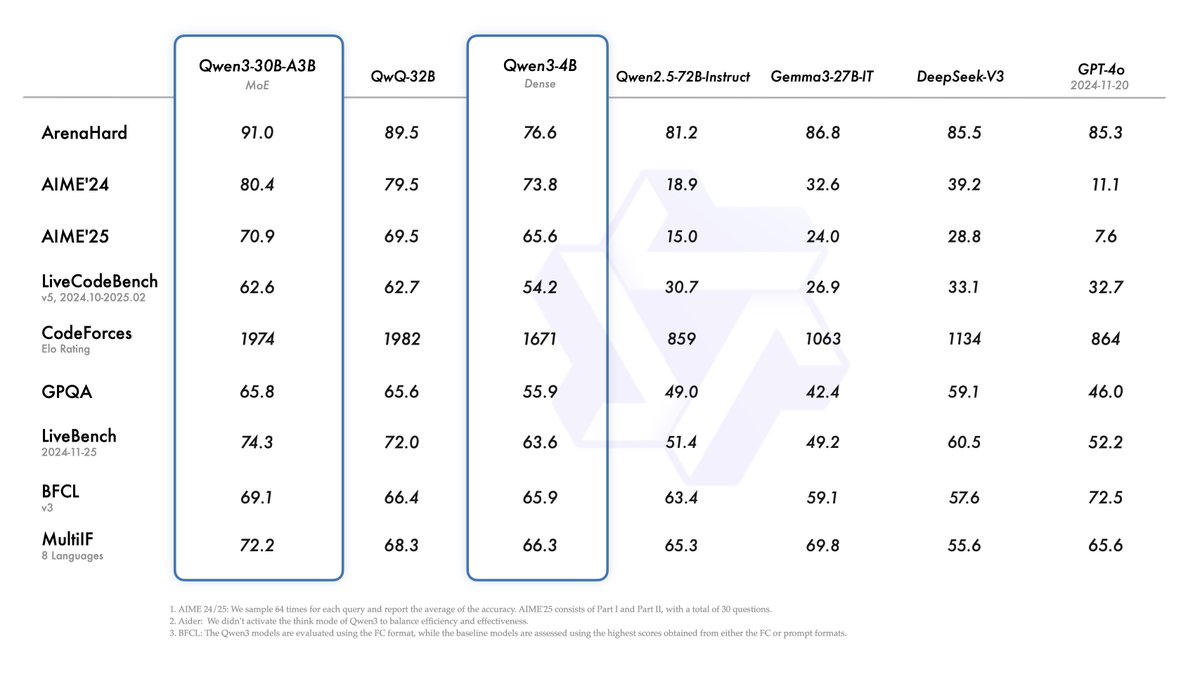
 Performance of Qwen3-VL-30B-A3B-Thinking
Performance of Qwen3-VL-30B-A3B-Thinking 
 Use the voice chat and video chat features on Qwen Chat to experience the Qwen3-Omni model.
Use the voice chat and video chat features on Qwen Chat to experience the Qwen3-Omni model.
 Pretraining Efficiency & Inference Speed
Pretraining Efficiency & Inference Speed 

 Make an interesting animate
Make an interesting animate

 Qwen3 exhibits scalable and smooth performance improvements that are directly correlated with the computational reasoning budget allocated. This design enables users to configure task-specific budgets with greater ease, achieving a more optimal balance between cost efficiency and inference quality.
Qwen3 exhibits scalable and smooth performance improvements that are directly correlated with the computational reasoning budget allocated. This design enables users to configure task-specific budgets with greater ease, achieving a more optimal balance between cost efficiency and inference quality.
 1 Computer use
1 Computer use
 Results of base language models. We are confident in the quality of our base models and we expect the next version of Qwen will be much better with our improved post-training methods.
Results of base language models. We are confident in the quality of our base models and we expect the next version of Qwen will be much better with our improved post-training methods. 
 QVQ achieves significant performance improvements in multiple benchmarks compared with Qwen2-VL-72B-Instruct.
QVQ achieves significant performance improvements in multiple benchmarks compared with Qwen2-VL-72B-Instruct. 
 We first conducted experiments on the 1M-token Passkey Retrieval task. The results show that Qwen2.5-Turbo can perfectly capture all hidden numbers in the 1M tokens of irrelevant text, demonstrating the model’s ability to capture detailed information in ultra-long contexts.
We first conducted experiments on the 1M-token Passkey Retrieval task. The results show that Qwen2.5-Turbo can perfectly capture all hidden numbers in the 1M tokens of irrelevant text, demonstrating the model’s ability to capture detailed information in ultra-long contexts. 
 Super excited to launch our models together with one of our best friends, Ollama! Today, the Qwen capybara codes together with Ollama! @ollama
Super excited to launch our models together with one of our best friends, Ollama! Today, the Qwen capybara codes together with Ollama! @ollama 
 Qwen is pre-training
Qwen is pre-training 
 Qwen2.5-72B-Instruct against the opensource models!
Qwen2.5-72B-Instruct against the opensource models! 