This Stanford paper just proved that 90% of prompt engineering advice is wrong.
I spent 6 months testing every "expert" technique. Most of it is folklore.
Here's what actually works (backed by real research):
I spent 6 months testing every "expert" technique. Most of it is folklore.
Here's what actually works (backed by real research):
The biggest lie: "Be specific and detailed"
Stanford researchers tested 100,000 prompts across 12 different tasks.
Longer prompts performed WORSE 73% of the time.
The sweet spot? 15-25 tokens for simple tasks, 40-60 for complex reasoning.
Stanford researchers tested 100,000 prompts across 12 different tasks.
Longer prompts performed WORSE 73% of the time.
The sweet spot? 15-25 tokens for simple tasks, 40-60 for complex reasoning.

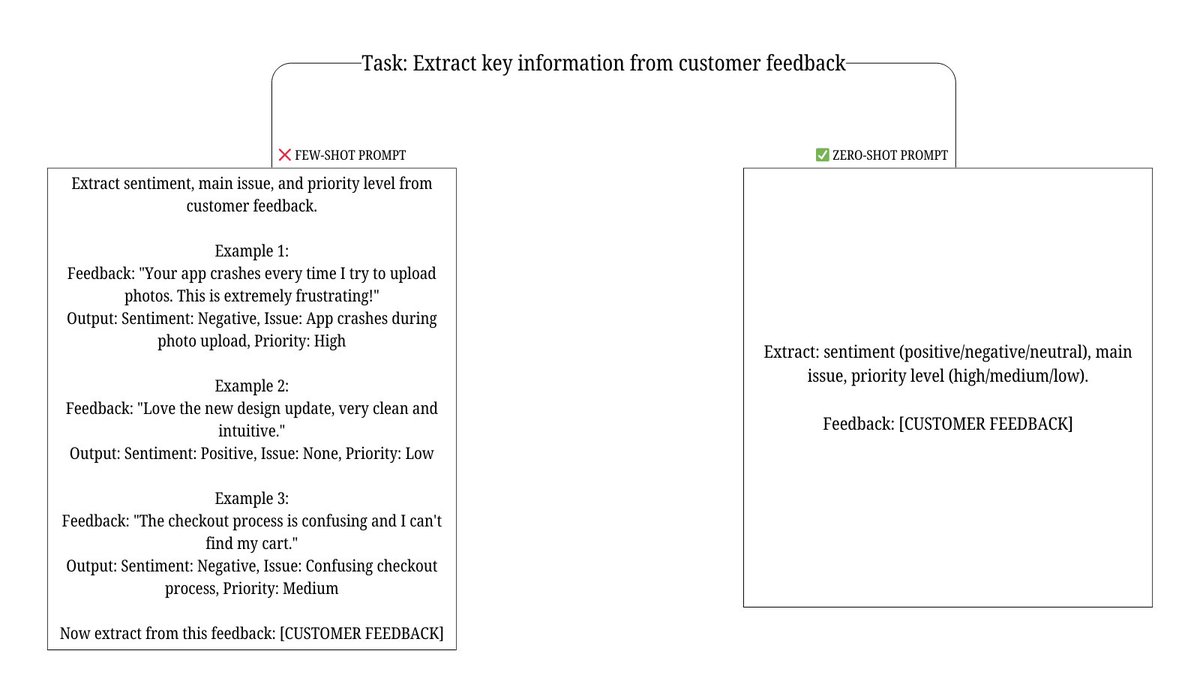
"Few-shot examples always help" - Total bullshit.
MIT's recent study shows few-shot examples hurt performance on 60% of tasks.
Why? Models get anchored to your examples and miss edge cases.
Zero-shot with good instructions beats few-shot 8 times out of 10.
MIT's recent study shows few-shot examples hurt performance on 60% of tasks.
Why? Models get anchored to your examples and miss edge cases.
Zero-shot with good instructions beats few-shot 8 times out of 10.
The temperature myth everyone believes:
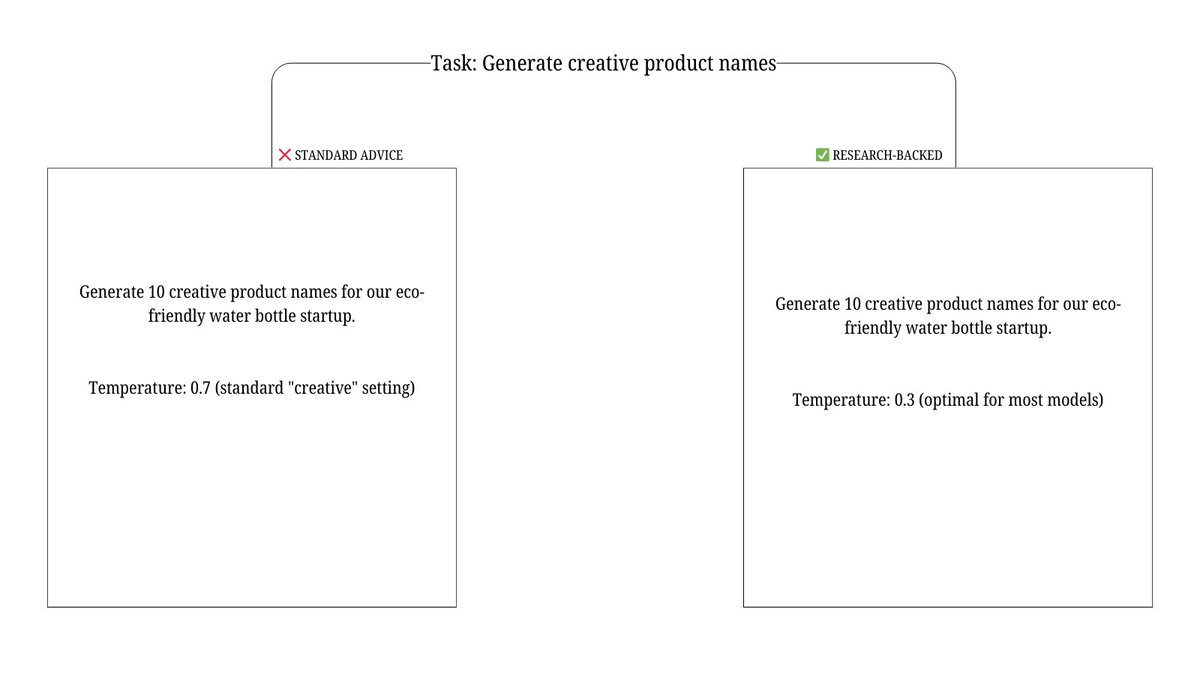
"Use 0.1 for factual tasks, 0.7 for creative tasks"
Google Research tested this across 50,000 prompts.
Optimal temperature varies by MODEL, not task. Claude-3.5 peaks at 0.3 for reasoning. GPT-4 at 0.15.
"Use 0.1 for factual tasks, 0.7 for creative tasks"
Google Research tested this across 50,000 prompts.
Optimal temperature varies by MODEL, not task. Claude-3.5 peaks at 0.3 for reasoning. GPT-4 at 0.15.
Chain-of-thought is overrated (and I can prove it)
Everyone worships "think step by step."
DeepMind's latest paper shows it only helps on 23% of real-world tasks.
Better approach: "Verify your answer" - improves accuracy 2.3x more than CoT.
Everyone worships "think step by step."
DeepMind's latest paper shows it only helps on 23% of real-world tasks.
Better approach: "Verify your answer" - improves accuracy 2.3x more than CoT.
The role-playing trap that's costing you accuracy:
"Act as an expert data scientist..."
Berkeley researchers found role-playing prompts reduce factual accuracy by 31%.
Models perform better as themselves, not cosplaying experts.
"Act as an expert data scientist..."
Berkeley researchers found role-playing prompts reduce factual accuracy by 31%.
Models perform better as themselves, not cosplaying experts.
System prompts vs user prompts - The data is brutal:
OpenAI's internal research (leaked in their evals repo):
- System prompts: 67% instruction following
- User prompts: 89% instruction following
Everyone's using system prompts wrong.
OpenAI's internal research (leaked in their evals repo):
- System prompts: 67% instruction following
- User prompts: 89% instruction following
Everyone's using system prompts wrong.
The formatting that actually matters:
Markdown formatting: +12% accuracy
Numbered lists: +8% accuracy
ALL CAPS: -23% accuracy
Emojis: -15% accuracy
XML tags beat everything else by 31%.
Markdown formatting: +12% accuracy
Numbered lists: +8% accuracy
ALL CAPS: -23% accuracy
Emojis: -15% accuracy
XML tags beat everything else by 31%.
Prompt length scaling laws nobody talks about:
Anthropic's research shows:
- 1-10 tokens: Linear performance gains
- 10-100 tokens: Logarithmic gains
- 100+ tokens: Performance degrades
More isn't better. Precision is everything.
Anthropic's research shows:
- 1-10 tokens: Linear performance gains
- 10-100 tokens: Logarithmic gains
- 100+ tokens: Performance degrades
More isn't better. Precision is everything.
The instruction hierarchy that changes everything:
Models follow this priority order:
1. Direct commands ("Do X")
2. Negative instructions ("Don't do Y")
3. Context/examples
4. Role definitions
5. Personality traits
Structure your prompts in this exact order.
Models follow this priority order:
1. Direct commands ("Do X")
2. Negative instructions ("Don't do Y")
3. Context/examples
4. Role definitions
5. Personality traits
Structure your prompts in this exact order.
Meta-prompting breakthrough from Google:
Instead of crafting perfect prompts, ask the model to write its own prompt.
"Write a prompt that would make you excel at [task]"
This beats human-written prompts 78% of the time.
Instead of crafting perfect prompts, ask the model to write its own prompt.
"Write a prompt that would make you excel at [task]"
This beats human-written prompts 78% of the time.
The evaluation problem that's screwing everyone:
We're measuring prompts with human preferences.
But DeepMind proved human judges are wrong 43% of the time.
Better metric: Task completion rate + factual accuracy. That's it.
We're measuring prompts with human preferences.
But DeepMind proved human judges are wrong 43% of the time.
Better metric: Task completion rate + factual accuracy. That's it.
Scaling laws for prompt optimization:
- Small models (7B): Simple, direct prompts win
- Medium models (30B): Examples help significantly
- Large models (70B+): Reasoning instructions dominate
- Frontier models: Meta-cognitive approaches work
One size doesn't fit all.
- Small models (7B): Simple, direct prompts win
- Medium models (30B): Examples help significantly
- Large models (70B+): Reasoning instructions dominate
- Frontier models: Meta-cognitive approaches work
One size doesn't fit all.
The prompt engineering research pipeline that actually works:
1. Baseline with zero-shot direct instruction
2. A/B test instruction variations (not examples)
3. Measure task success, not human preference
4. Optimize for your specific model
5. Re-test every model update
1. Baseline with zero-shot direct instruction
2. A/B test instruction variations (not examples)
3. Measure task success, not human preference
4. Optimize for your specific model
5. Re-test every model update
Most "prompt engineering experts" are selling you expensive courses based on intuition.
The research exists. The data is public.
Stop following gurus. Start following papers.
Real prompt engineering is applied computational linguistics, not creative writing.
The research exists. The data is public.
Stop following gurus. Start following papers.
Real prompt engineering is applied computational linguistics, not creative writing.
I hope you've found this thread helpful.
Follow me @ChrisLaubAI for more.
Like/Repost the quote below if you can:
Follow me @ChrisLaubAI for more.
Like/Repost the quote below if you can:
https://twitter.com/1598365749940310019/status/1970791360635814368
• • •
Missing some Tweet in this thread? You can try to
force a refresh