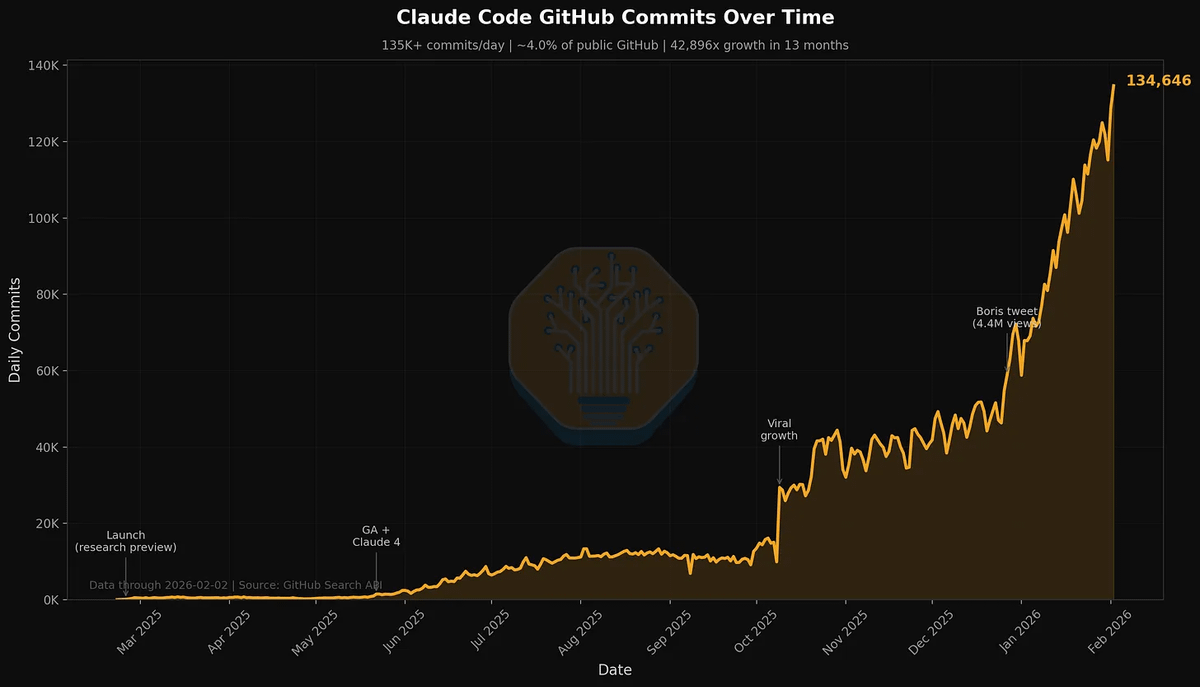
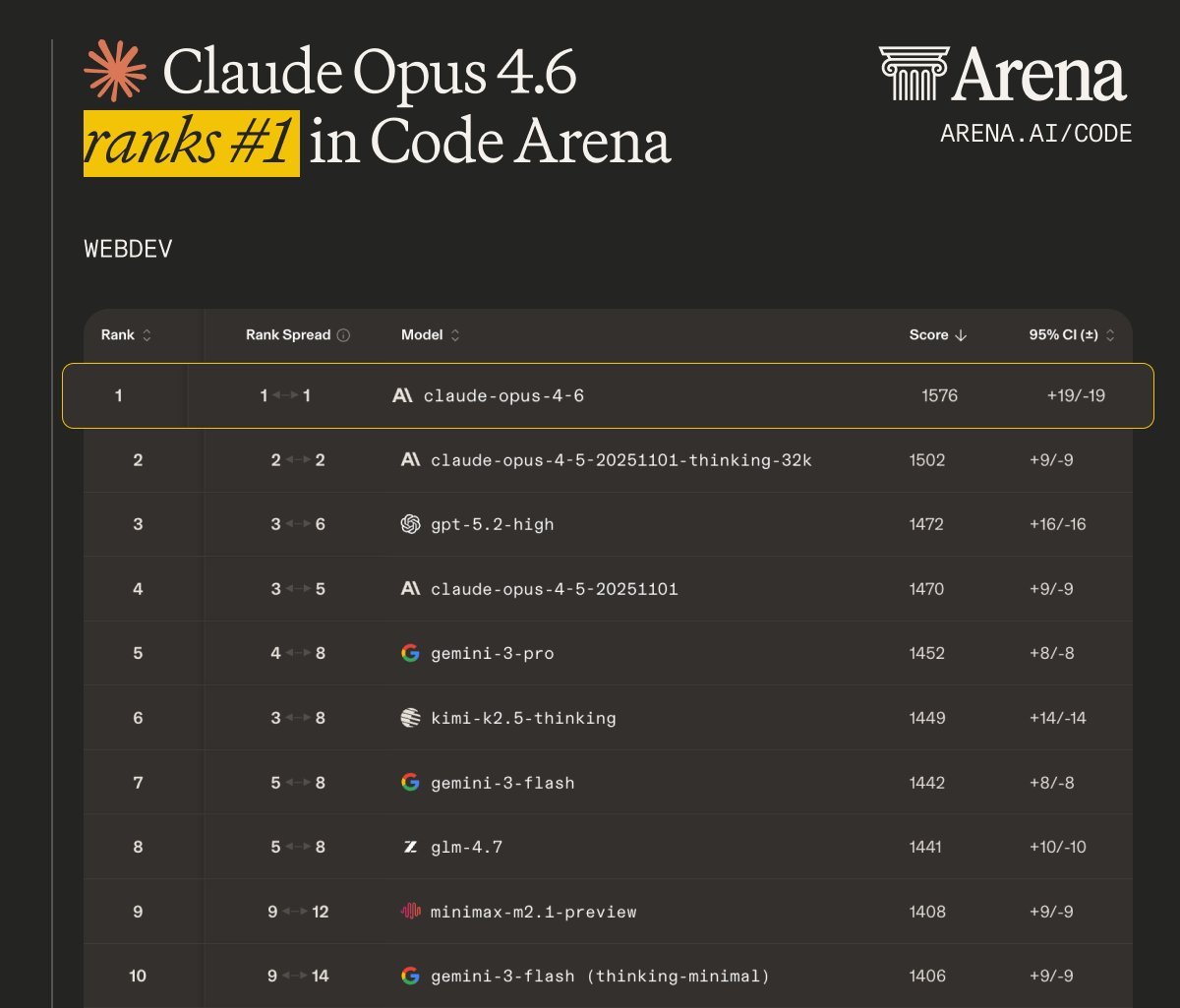
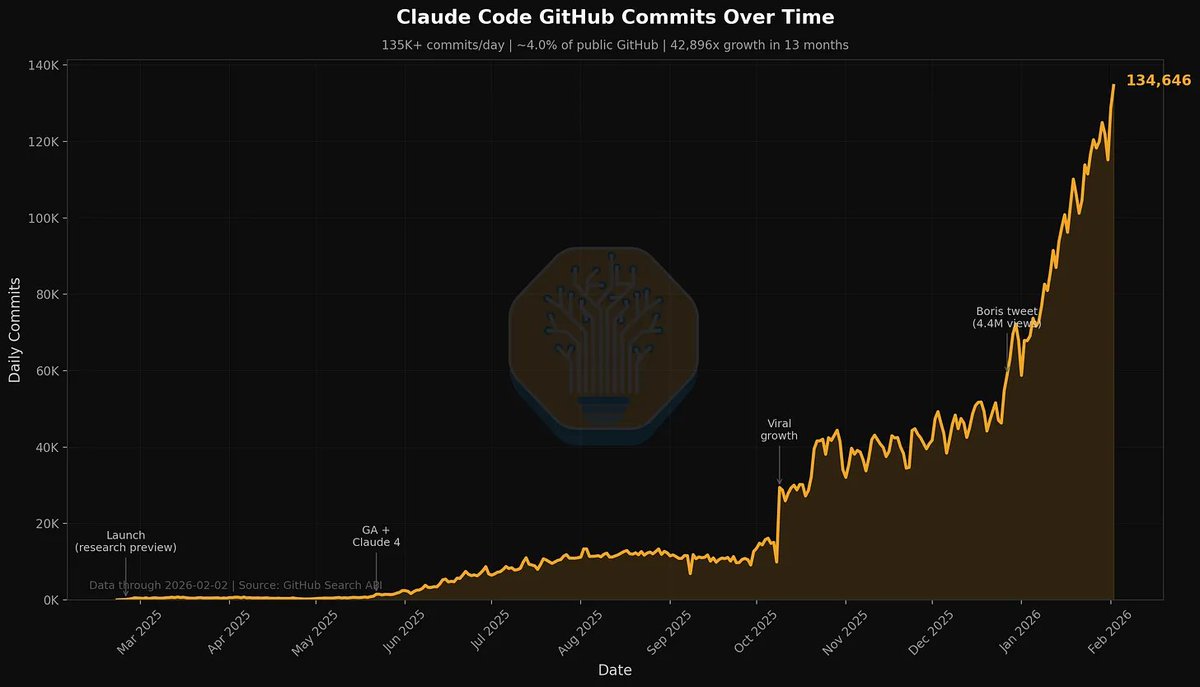
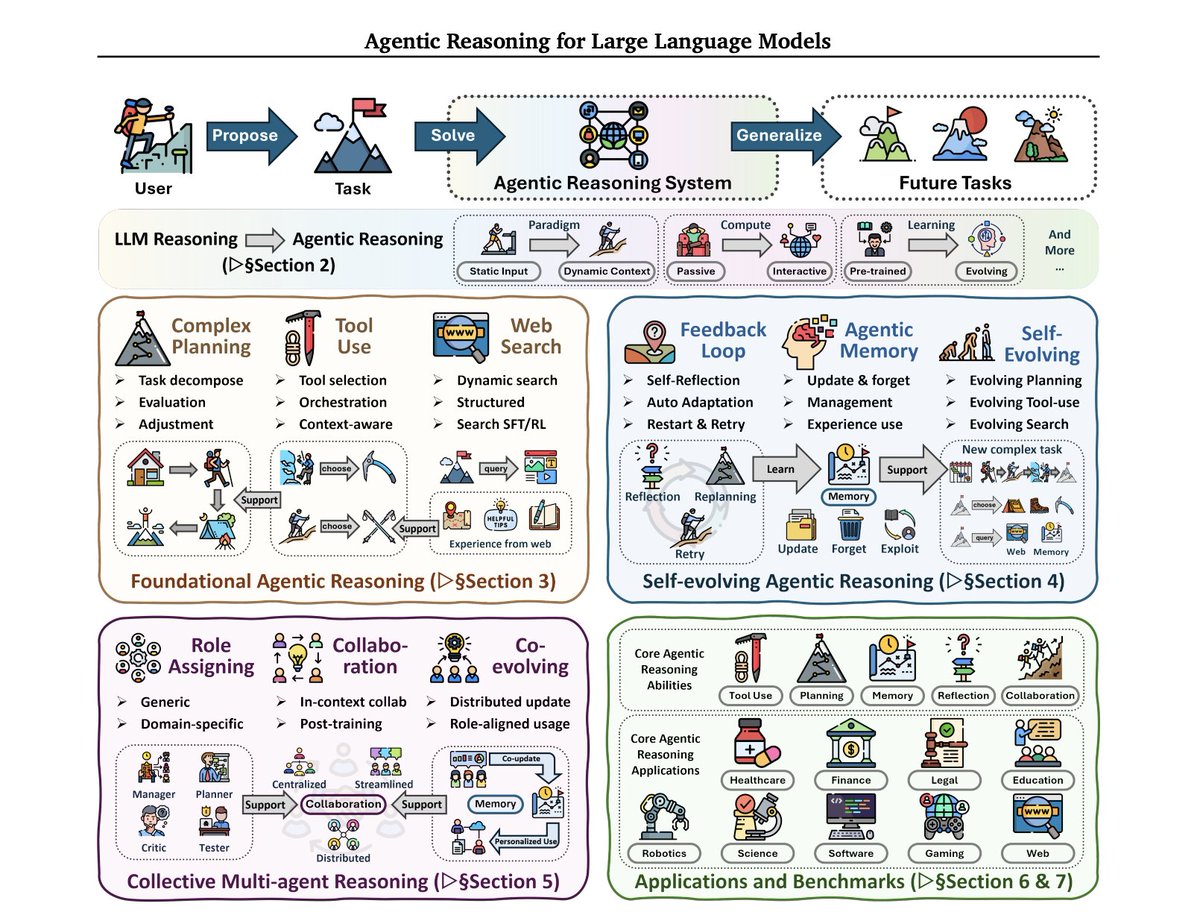
RIP fine-tuning ☠️
This new Stanford paper just killed it.
It’s called 'Agentic Context Engineering (ACE)' and it proves you can make models smarter without touching a single weight.
Instead of retraining, ACE evolves the context itself.
The model writes, reflects, and edits its own prompt over and over until it becomes a self-improving system.
Think of it like the model keeping a growing notebook of what works.
Each failure becomes a strategy. Each success becomes a rule.
The results are absurd:
+10.6% better than GPT-4–powered agents on AppWorld.
+8.6% on finance reasoning.
86.9% lower cost and latency.
No labels. Just feedback.
Everyone’s been obsessed with “short, clean” prompts.
ACE flips that. It builds long, detailed evolving playbooks that never forget. And it works because LLMs don’t want simplicity, they want *context density.
If this scales, the next generation of AI won’t be “fine-tuned.”
It’ll be self-tuned.
We’re entering the era of living prompts.
This new Stanford paper just killed it.
It’s called 'Agentic Context Engineering (ACE)' and it proves you can make models smarter without touching a single weight.
Instead of retraining, ACE evolves the context itself.
The model writes, reflects, and edits its own prompt over and over until it becomes a self-improving system.
Think of it like the model keeping a growing notebook of what works.
Each failure becomes a strategy. Each success becomes a rule.
The results are absurd:
+10.6% better than GPT-4–powered agents on AppWorld.
+8.6% on finance reasoning.
86.9% lower cost and latency.
No labels. Just feedback.
Everyone’s been obsessed with “short, clean” prompts.
ACE flips that. It builds long, detailed evolving playbooks that never forget. And it works because LLMs don’t want simplicity, they want *context density.
If this scales, the next generation of AI won’t be “fine-tuned.”
It’ll be self-tuned.
We’re entering the era of living prompts.

Here’s how ACE works 👇
It splits the model’s brain into 3 roles:
Generator - runs the task
Reflector - critiques what went right or wrong
Curator - updates the context with only what matters
Each loop adds delta updates small context changes that never overwrite old knowledge.
It’s literally the first agent framework that grows its own prompt.
It splits the model’s brain into 3 roles:
Generator - runs the task
Reflector - critiques what went right or wrong
Curator - updates the context with only what matters
Each loop adds delta updates small context changes that never overwrite old knowledge.
It’s literally the first agent framework that grows its own prompt.

Every prior method had one fatal flaw: context collapse.
Models rewrite their entire prompt each time → it gets shorter → details vanish → accuracy tanks.
In the paper, one model’s accuracy fell from 66.7 → 57.1 after a single rewrite.
ACE fixes that by never rewriting the full context - only updating what changed.
Models rewrite their entire prompt each time → it gets shorter → details vanish → accuracy tanks.
In the paper, one model’s accuracy fell from 66.7 → 57.1 after a single rewrite.
ACE fixes that by never rewriting the full context - only updating what changed.

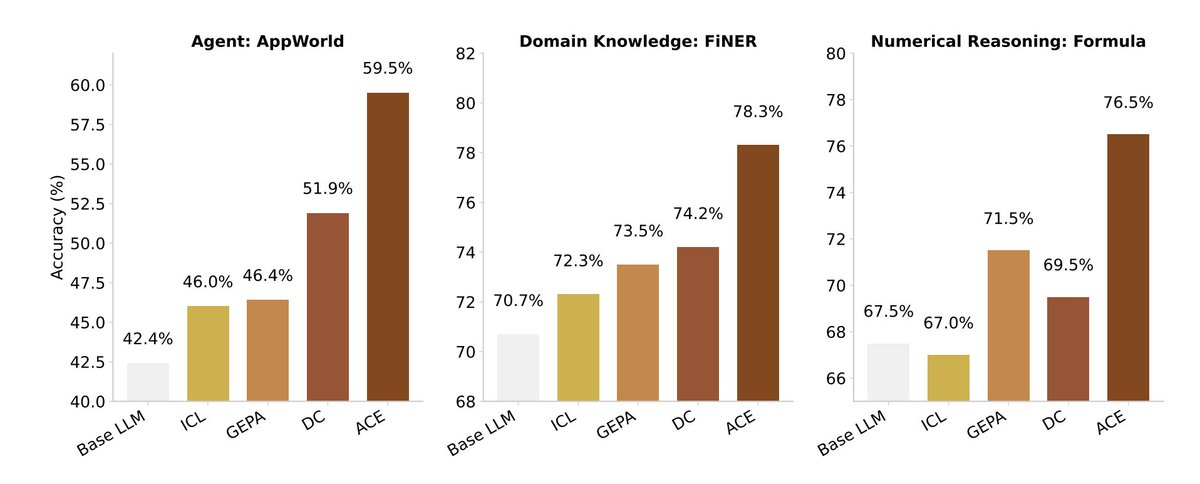
The numbers are ridiculous.
ACE beat every major baseline:
+10.6% on AppWorld (agents)
+8.6% on FiNER (finance)
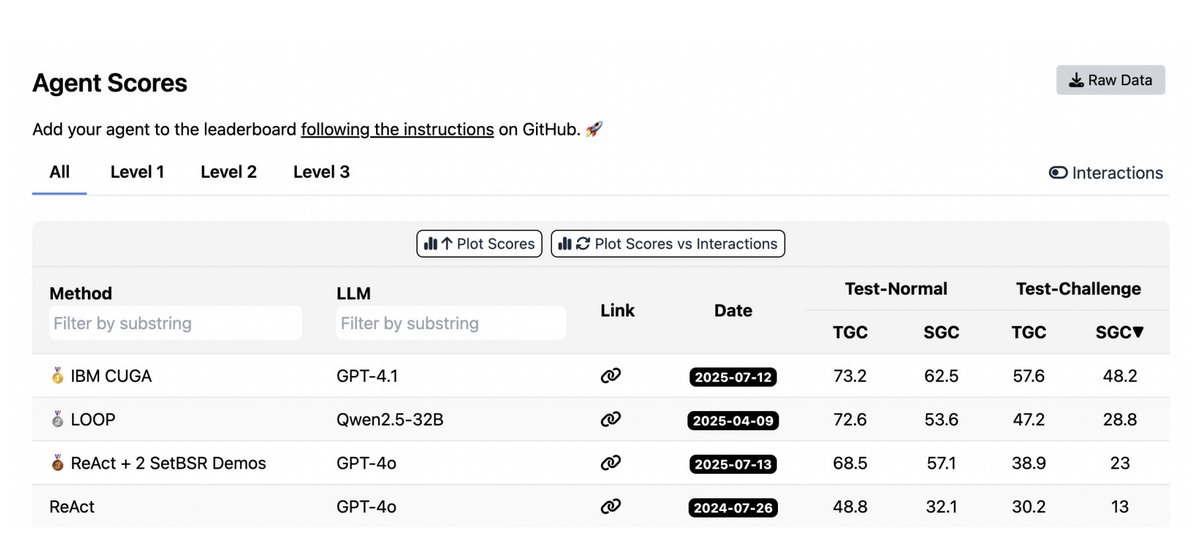
and matched GPT-4.1–powered IBM CUGA, using a smaller open-source model.
And it cut rollout latency by 86.9% while lowering cost 80%.
ACE beat every major baseline:
+10.6% on AppWorld (agents)
+8.6% on FiNER (finance)
and matched GPT-4.1–powered IBM CUGA, using a smaller open-source model.
And it cut rollout latency by 86.9% while lowering cost 80%.
Fine-tuning updates weights.
ACE updates understanding.
It’s cheaper, interpretable, and reversible.
You can literally watch how your AI learns, one context delta at a time.
This is the start of agentic self-learning where prompts become the new model weights.
ACE updates understanding.
It’s cheaper, interpretable, and reversible.
You can literally watch how your AI learns, one context delta at a time.
This is the start of agentic self-learning where prompts become the new model weights.

ACE points to a wild future:
AI systems that don’t just reason they remember.
Instead of retraining models, we’ll train contexts.
Each system carries a living memory that evolves across sessions, domains, and users.
The next breakthroughs won’t come from bigger models…
They’ll come from smarter context architectures.
AI systems that don’t just reason they remember.
Instead of retraining models, we’ll train contexts.
Each system carries a living memory that evolves across sessions, domains, and users.
The next breakthroughs won’t come from bigger models…
They’ll come from smarter context architectures.
Read the full paper: arxiv.org/abs/2510.04618
• • •
Missing some Tweet in this thread? You can try to
force a refresh