Market research firms are cooked 😳
PyMC Labs + Colgate just published something wild. They got GPT-4o and Gemini to predict purchase intent at 90% reliability compared to actual human surveys.
Zero focus groups. No survey panels. Just prompting.
The method is called Semantic Similarity Rating (SSR). Instead of the usual "rate this 1-5" they ask open ended questions like "why would you buy this" and then use embeddings to map the text back to a numerical scale.
Which is honestly kind of obvious in hindsight but nobody bothered trying it until now.
Results match human demographic patterns, capture the same distribution shapes, include actual reasoning. The stuff McKinsey charges $50K+ for and delivers in 6 weeks.
Except this runs in 3 minutes for under a buck.
I've been watching consulting firms tell everyone AI is coming for their industry. Turns out their own $1M market entry decks just became a GPT-4o call.
Bad week to be charging enterprise clients for "proprietary research methodologies."
PyMC Labs + Colgate just published something wild. They got GPT-4o and Gemini to predict purchase intent at 90% reliability compared to actual human surveys.
Zero focus groups. No survey panels. Just prompting.
The method is called Semantic Similarity Rating (SSR). Instead of the usual "rate this 1-5" they ask open ended questions like "why would you buy this" and then use embeddings to map the text back to a numerical scale.
Which is honestly kind of obvious in hindsight but nobody bothered trying it until now.
Results match human demographic patterns, capture the same distribution shapes, include actual reasoning. The stuff McKinsey charges $50K+ for and delivers in 6 weeks.
Except this runs in 3 minutes for under a buck.
I've been watching consulting firms tell everyone AI is coming for their industry. Turns out their own $1M market entry decks just became a GPT-4o call.
Bad week to be charging enterprise clients for "proprietary research methodologies."

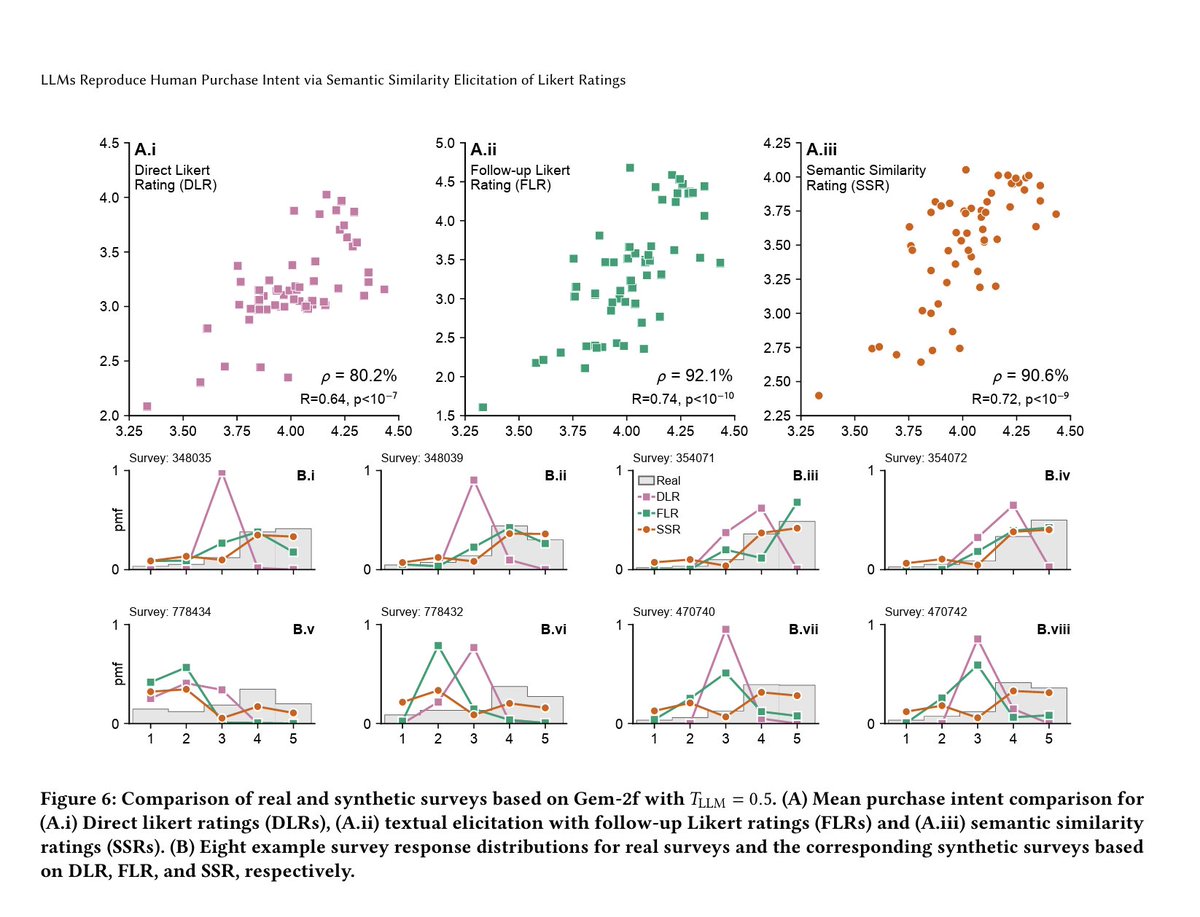
Most LLM surveys fail because models regress to the mean.
When asked for a direct “1–5” rating, GPT-4o replied “3” almost every time producing KS similarity = 0.26 to real human data.
Translation: the distribution was basically useless.
When asked for a direct “1–5” rating, GPT-4o replied “3” almost every time producing KS similarity = 0.26 to real human data.
Translation: the distribution was basically useless.

When researchers switched to free-text answers and then asked a second model to translate those into ratings (“Follow-up Likert Rating”), correlation with real panels jumped to ρ = 0.85.
Distribution realism improved to KS = 0.72.
Better, but still too narrow.
Distribution realism improved to KS = 0.72.
Better, but still too narrow.

The real breakthrough came with Semantic Similarity Rating (SSR) mapping each text answer to 5 anchor statements via cosine similarity.
Result: ρ = 0.90 correlation attainment and KS = 0.88 distribution similarity for GPT-4o.
Basically 90% of human test–retest reliability.
Result: ρ = 0.90 correlation attainment and KS = 0.88 distribution similarity for GPT-4o.
Basically 90% of human test–retest reliability.

Even more interesting: synthetic consumers mirrored real demographic patterns.
Middle-aged personas rated higher purchase intent than young or old ones.
Income level “2” (“in danger financially”) triggered the sharpest drop in ratings exactly like human panels.
Middle-aged personas rated higher purchase intent than young or old ones.
Income level “2” (“in danger financially”) triggered the sharpest drop in ratings exactly like human panels.
The best part?
When LLMs weren’t given demographic context, they matched the shape of human distributions (KS = 0.91) but lost meaning correlation fell to ρ = 0.50.
So realism ≠ understanding.
The persona prompt is what makes the model “think” like a consumer.
Read full paper: arxiv.org/abs/2510.08338
When LLMs weren’t given demographic context, they matched the shape of human distributions (KS = 0.91) but lost meaning correlation fell to ρ = 0.50.
So realism ≠ understanding.
The persona prompt is what makes the model “think” like a consumer.
Read full paper: arxiv.org/abs/2510.08338
The AI prompt library your competitors don't want you to find
→ Biggest collection of text & image prompts
→ Unlimited custom prompts
→ Lifetime access & updates
Grab it before it's gone 👇
godofprompt.ai/pricing
→ Biggest collection of text & image prompts
→ Unlimited custom prompts
→ Lifetime access & updates
Grab it before it's gone 👇
godofprompt.ai/pricing
• • •
Missing some Tweet in this thread? You can try to
force a refresh