We improved @cline, a popular open-source coding agent, by +15% accuracy on SWE-Bench — without retraining LLMs, changing tools, or modifying Cline's architecture.
We achieved this simply through optimizing its ruleset, in ./clinerules — a user defined section for developers to add custom instructions to the system prompt, just like .cursor/rules in Cursor or CLAUDE.md in Claude Code.
Using our algorithm, Prompt Learning, we automatically refined these rules across a feedback loop powered by GPT-5.
Here’s how we brought GPT-4.1’s performance on SWE-Bench Lite to near state-of-the-art levels — matching Claude Sonnet 4-5 — purely through ruleset optimization.
See our more detailed blog post 👉: arize.com/blog/optimizin…
We achieved this simply through optimizing its ruleset, in ./clinerules — a user defined section for developers to add custom instructions to the system prompt, just like .cursor/rules in Cursor or CLAUDE.md in Claude Code.
Using our algorithm, Prompt Learning, we automatically refined these rules across a feedback loop powered by GPT-5.
Here’s how we brought GPT-4.1’s performance on SWE-Bench Lite to near state-of-the-art levels — matching Claude Sonnet 4-5 — purely through ruleset optimization.
See our more detailed blog post 👉: arize.com/blog/optimizin…
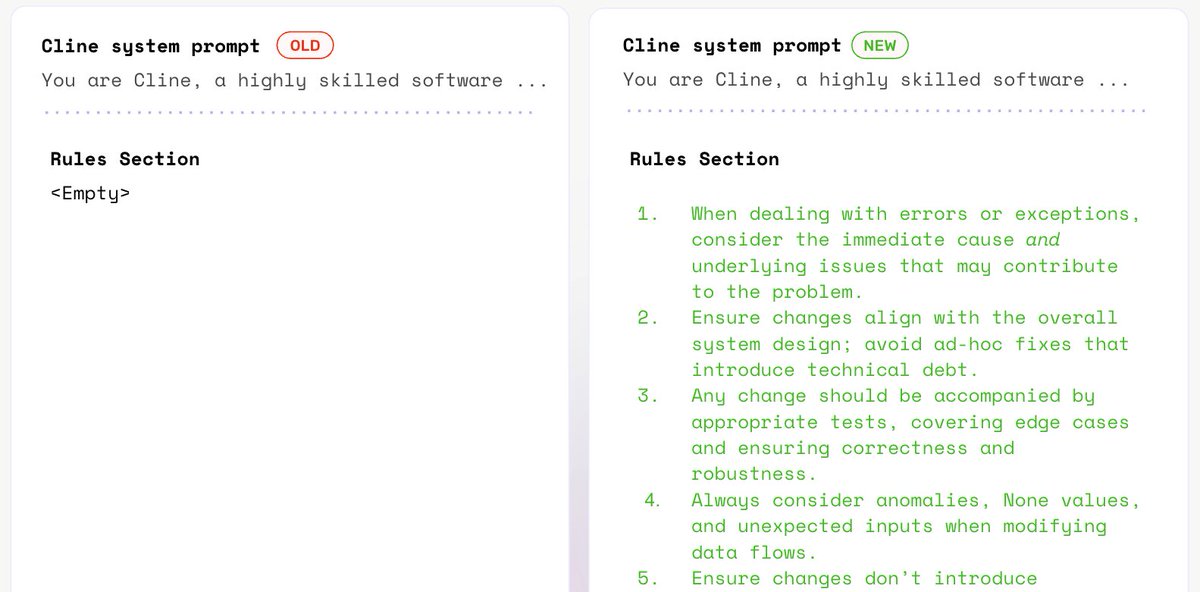
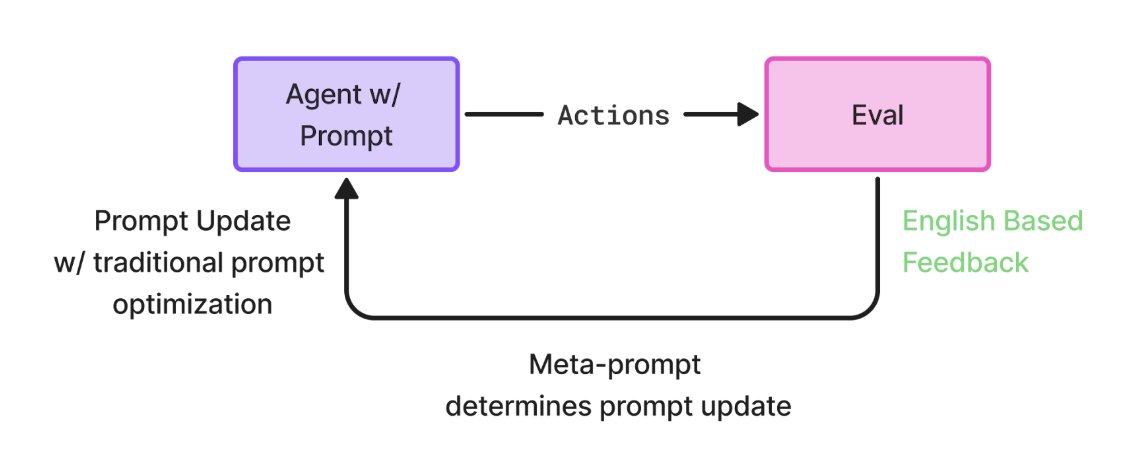
What is Prompt Learning?
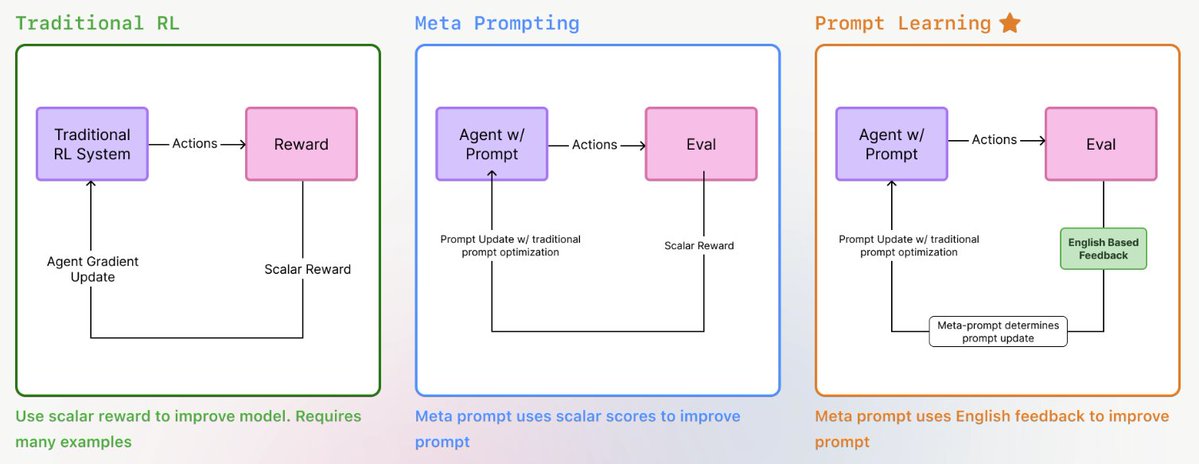
It’s an optimization algorithm for prompts.
Inspired by RL, it follows an action → evaluation → improvement loop — but instead of gradients, it uses Meta Prompting: feeding a prompt into an LLM and asking it to make it better.
We use LLM-generated feedback explaining why outputs were right or wrong, giving the optimizer richer signal to refine future prompts.
📈 Result: measurable gains in accuracy, zero retraining.
Use it in Arize AX or the Prompt Learning SDK.
It’s an optimization algorithm for prompts.
Inspired by RL, it follows an action → evaluation → improvement loop — but instead of gradients, it uses Meta Prompting: feeding a prompt into an LLM and asking it to make it better.
We use LLM-generated feedback explaining why outputs were right or wrong, giving the optimizer richer signal to refine future prompts.
📈 Result: measurable gains in accuracy, zero retraining.
Use it in Arize AX or the Prompt Learning SDK.
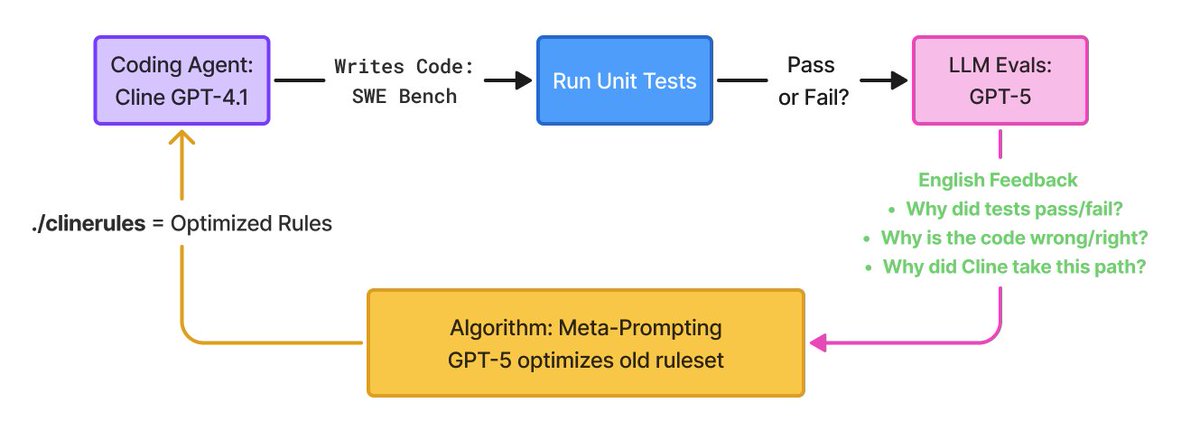
How we optimized Cline:
Last time, we optimized Plan Mode - this time, we optimized over Act Mode - giving Cline full permissions to read, write, and edit code files, and testing its accuracy on SWE Bench Lite.
Our optimization loop 🔁:
1️⃣ Run Cline on SWE-Bench Lite (150 train, 150 test) and record its train/test accuracy.
2️⃣ Collect the patches it produces and verify correctness via unit tests.
3️⃣ Use GPT-5 to explain why each fix succeeded or failed on the training set.
4️⃣ Feed those training evals — along with Cline’s system prompt and current ruleset — into a Meta-Prompt LLM to generate an improved ruleset.
5️⃣ Update ./clinerules, re-run, and repeat.
Last time, we optimized Plan Mode - this time, we optimized over Act Mode - giving Cline full permissions to read, write, and edit code files, and testing its accuracy on SWE Bench Lite.
Our optimization loop 🔁:
1️⃣ Run Cline on SWE-Bench Lite (150 train, 150 test) and record its train/test accuracy.
2️⃣ Collect the patches it produces and verify correctness via unit tests.
3️⃣ Use GPT-5 to explain why each fix succeeded or failed on the training set.
4️⃣ Feed those training evals — along with Cline’s system prompt and current ruleset — into a Meta-Prompt LLM to generate an improved ruleset.
5️⃣ Update ./clinerules, re-run, and repeat.
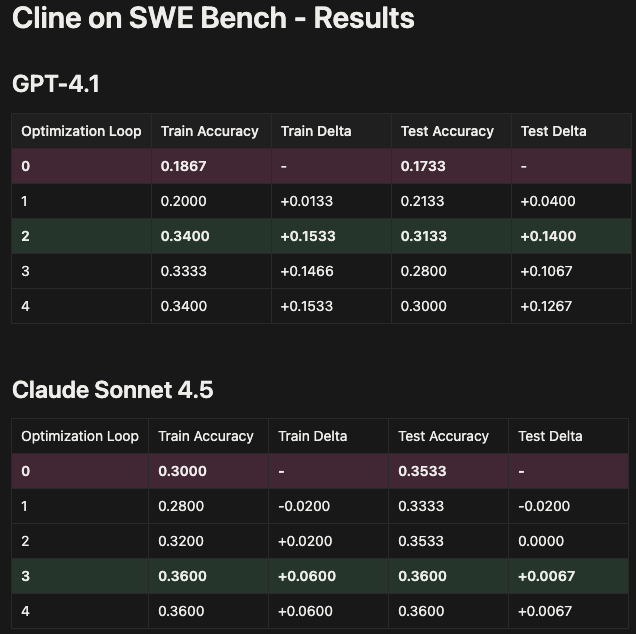
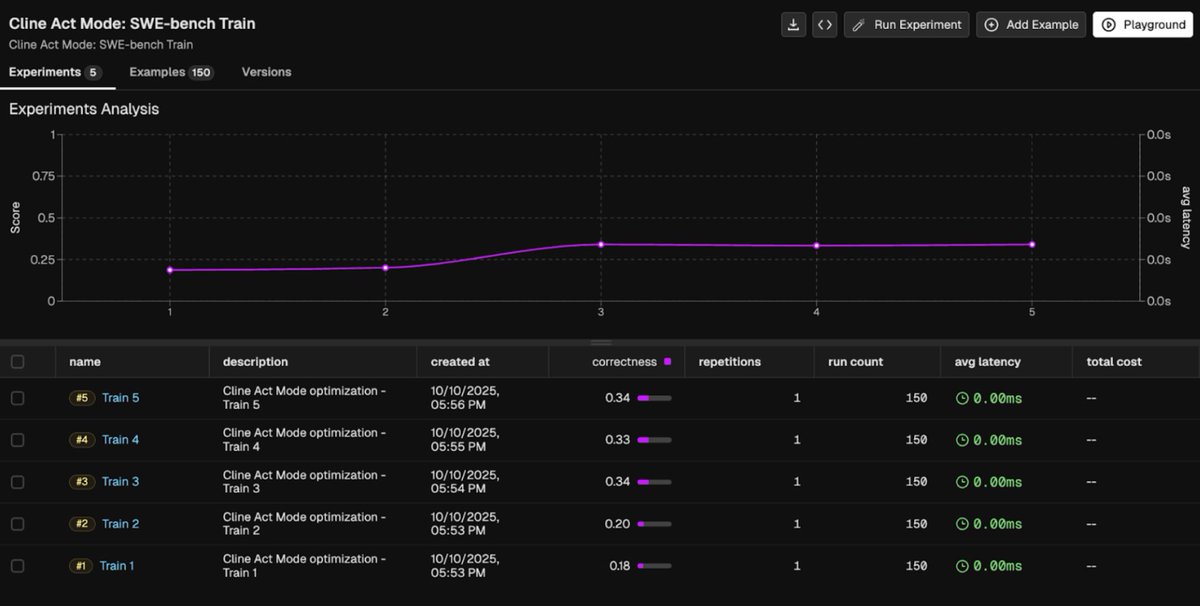
Results:
Sonnet 4-5 saw a modest +6% training and +0.7% test gain — already near saturation — while GPT-4.1 improved 14–15% in both, reaching near-Sonnet performance (34% vs 36%) through ruleset optimization alone in just two loops!
These results highlight how prompt optimization alone can deliver system-level gains — no retraining, no new tools, no architecture changes. In just two optimization loops, Prompt Learning closed much of the gap between GPT-4.1 and Sonnet 4-5-level performance, proving how fast and data-efficient instruction-level optimization can be.
Sonnet 4-5 saw a modest +6% training and +0.7% test gain — already near saturation — while GPT-4.1 improved 14–15% in both, reaching near-Sonnet performance (34% vs 36%) through ruleset optimization alone in just two loops!
These results highlight how prompt optimization alone can deliver system-level gains — no retraining, no new tools, no architecture changes. In just two optimization loops, Prompt Learning closed much of the gap between GPT-4.1 and Sonnet 4-5-level performance, proving how fast and data-efficient instruction-level optimization can be.
We used Phoenix to run LLM Evals on Cline’s code and track experiments across optimization runs.
Optimize Cline on SWE Bench using Prompt Learning and see improvement for yourself!
Code: github.com/Arize-ai/promp…
Use the Prompt Learning SDK: github.com/Arize-ai/promp…
Use Phoenix to run:
LLM Evals: arize.com/docs/phoenix/e…
Experiments: arize.com/docs/phoenix/d…
Code: github.com/Arize-ai/promp…
Use the Prompt Learning SDK: github.com/Arize-ai/promp…
Use Phoenix to run:
LLM Evals: arize.com/docs/phoenix/e…
Experiments: arize.com/docs/phoenix/d…
Tagging people who may be interested
@chengshuai_shi @ZhitingHu @HamelHusain @sh_reya @charlespacker @eugeneyan @swyx @dan_iter @sophiamyang @AndrewYNg @lateinteraction @cwolferesearch @tom_doerr @imjaredz @lennysan @shyamalanadkat @aakashg0 @apolloaievals @jerryjliu0 @joaomdmoura @jxnlco @DSPyOSS @abacaj @garrytan
@chengshuai_shi @ZhitingHu @HamelHusain @sh_reya @charlespacker @eugeneyan @swyx @dan_iter @sophiamyang @AndrewYNg @lateinteraction @cwolferesearch @tom_doerr @imjaredz @lennysan @shyamalanadkat @aakashg0 @apolloaievals @jerryjliu0 @joaomdmoura @jxnlco @DSPyOSS @abacaj @garrytan
• • •
Missing some Tweet in this thread? You can try to
force a refresh