
AI Founder: building @arizeai & @arizephoenix 💙
I post about LLMs, LLMOps, Generative AI, ML and occasionally Amazing Race
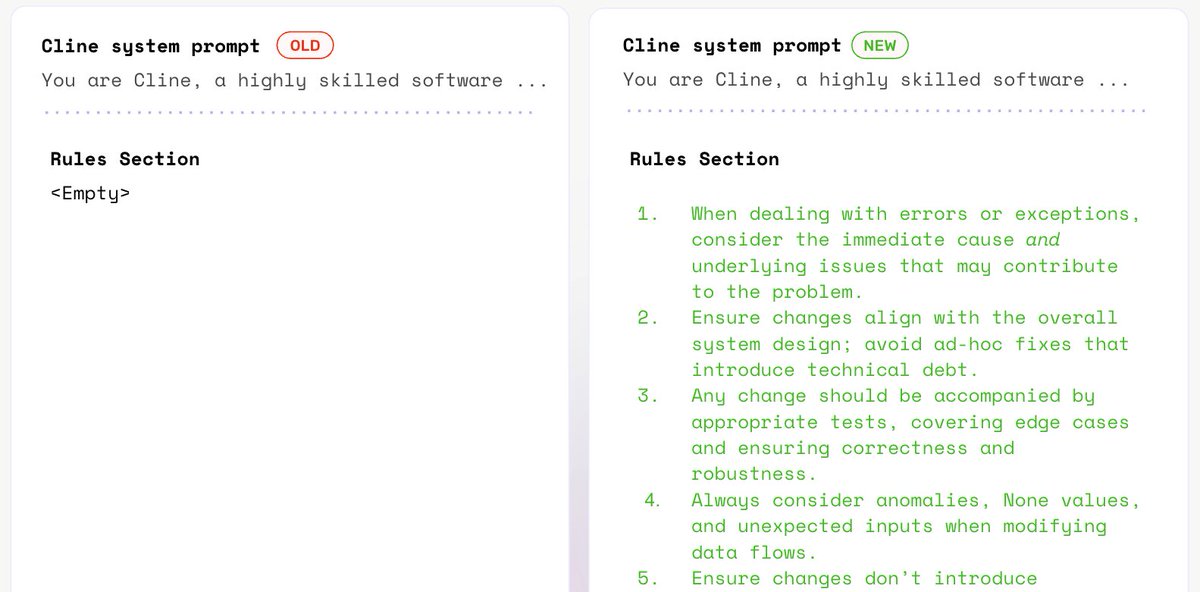 What is Prompt Learning?
What is Prompt Learning?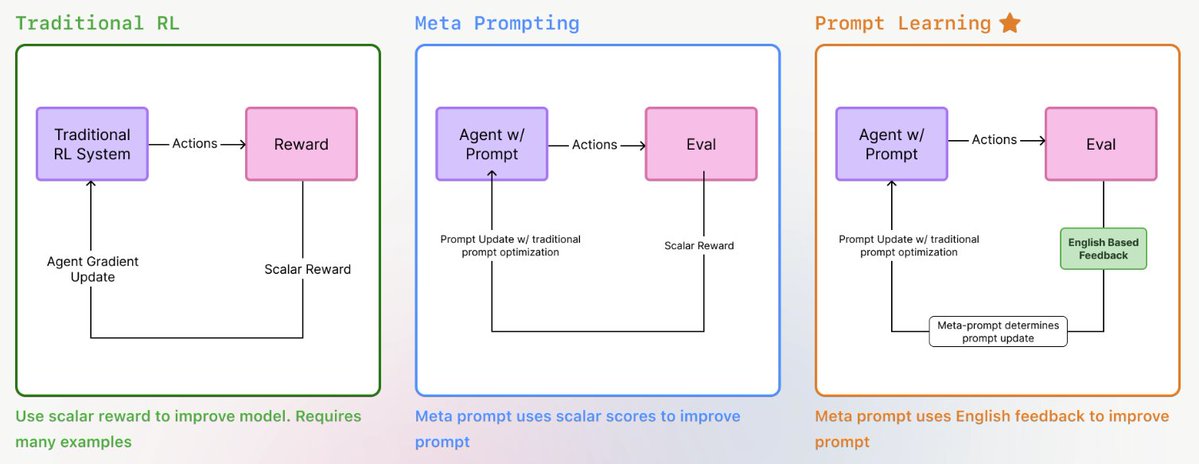
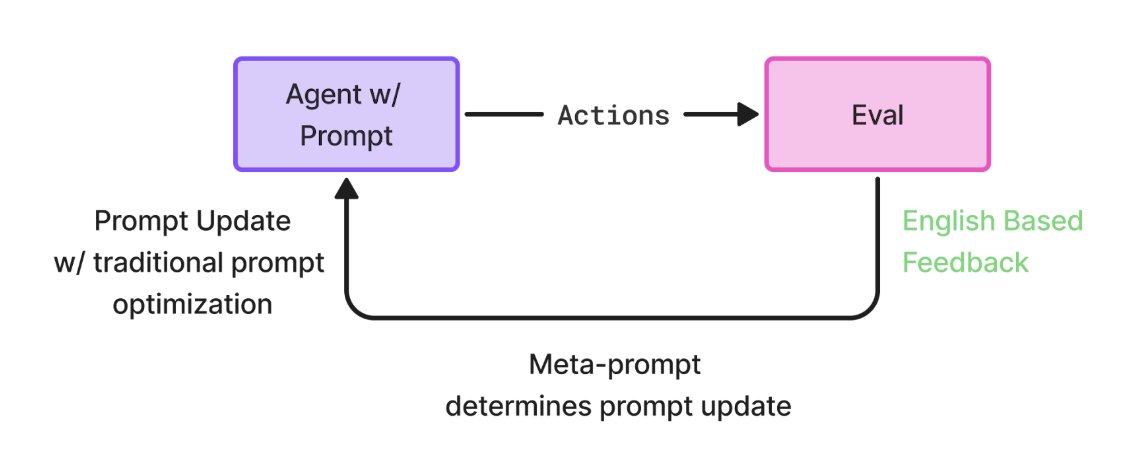 Prompts, like models, should improve with feedback — not stay static.
Prompts, like models, should improve with feedback — not stay static.
 (2/7) How do you even evaluate SQL generation?
(2/7) How do you even evaluate SQL generation?
 (2/6) Test Results
(2/6) Test Results
 (2/5) Test #2 : Retrieval with Generation Date Mapping
(2/5) Test #2 : Retrieval with Generation Date Mapping
 (2/4) Prompts Matter!!! ✨
(2/4) Prompts Matter!!! ✨ (2/8) What's a Model Eval? 🤔
(2/8) What's a Model Eval? 🤔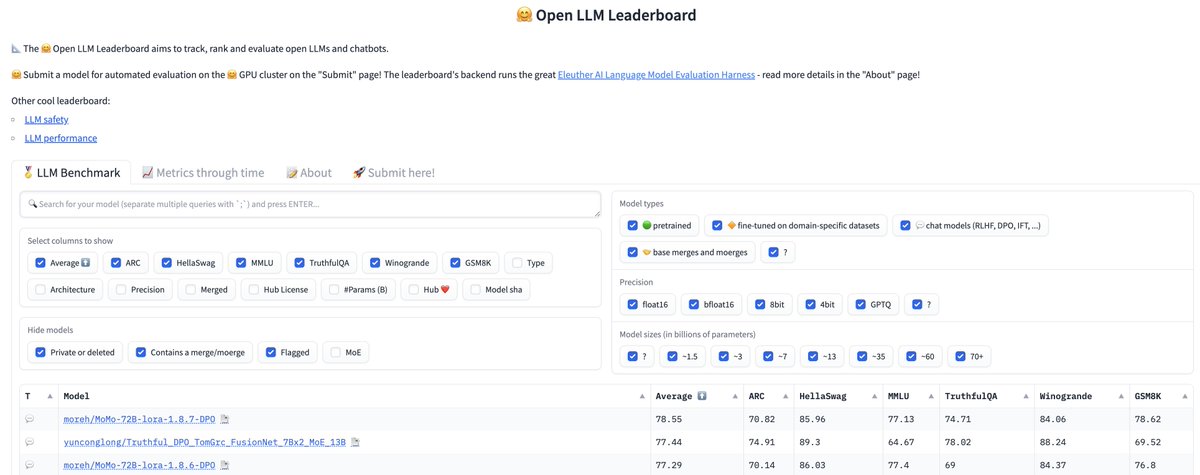
 (2/9) What we did:
(2/9) What we did: