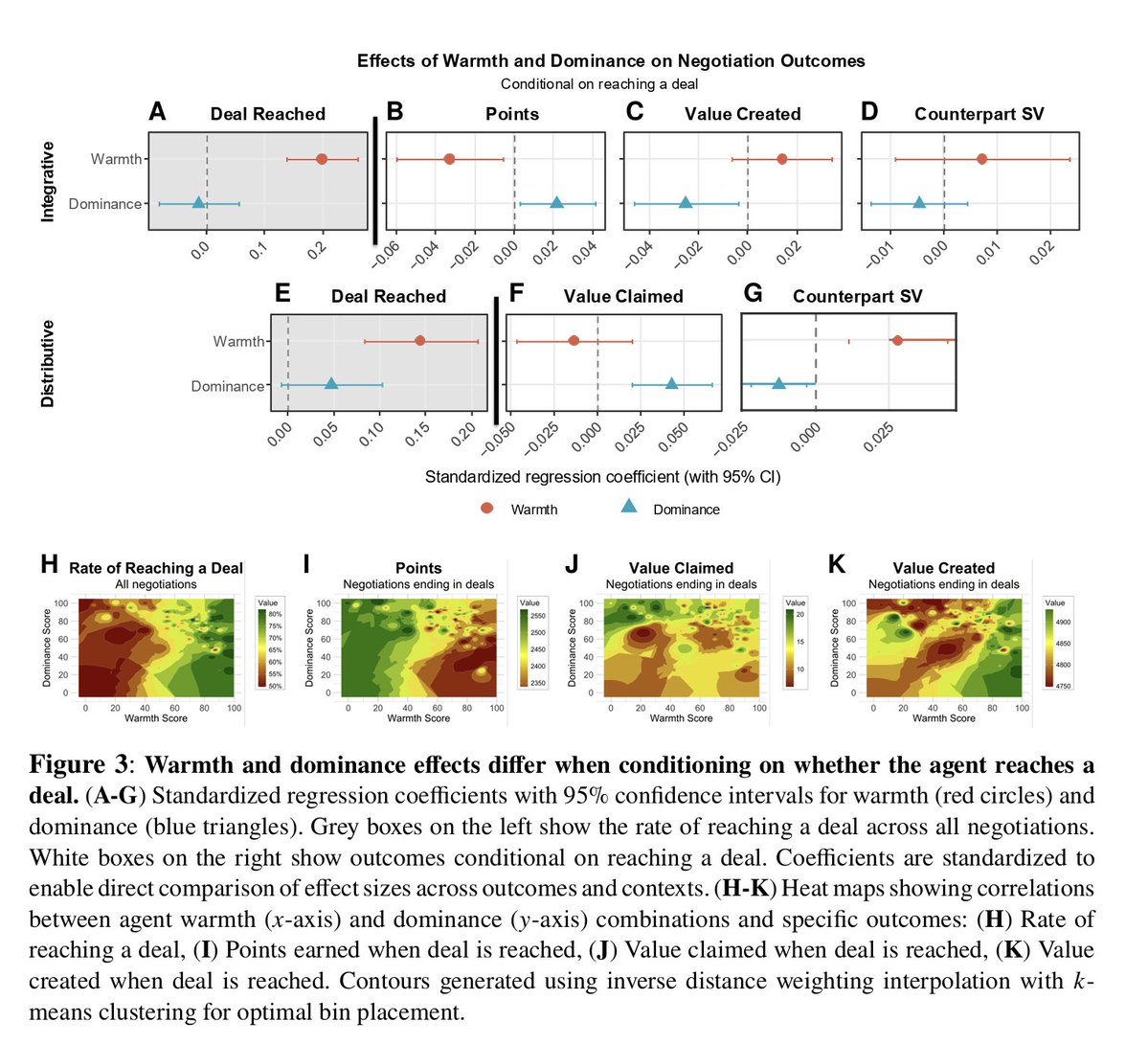
This might be the most disturbing AI paper of 2025 ☠️
Scientists just proved that large language models can literally rot their own brains the same way humans get brain rot from scrolling junk content online.
They fed models months of viral Twitter data short, high-engagement posts and watched their cognition collapse:
- Reasoning fell by 23%
- Long-context memory dropped 30%
- Personality tests showed spikes in narcissism & psychopathy
And get this even after retraining on clean, high-quality data, the damage didn’t fully heal.
The representational “rot” persisted.
It’s not just bad data → bad output.
It’s bad data → permanent cognitive drift.
The AI equivalent of doomscrolling is real. And it’s already happening.
Full study: llm-brain-rot. github. io
Scientists just proved that large language models can literally rot their own brains the same way humans get brain rot from scrolling junk content online.
They fed models months of viral Twitter data short, high-engagement posts and watched their cognition collapse:
- Reasoning fell by 23%
- Long-context memory dropped 30%
- Personality tests showed spikes in narcissism & psychopathy
And get this even after retraining on clean, high-quality data, the damage didn’t fully heal.
The representational “rot” persisted.
It’s not just bad data → bad output.
It’s bad data → permanent cognitive drift.
The AI equivalent of doomscrolling is real. And it’s already happening.
Full study: llm-brain-rot. github. io

What “Brain Rot” means for machines...
Humans get brain rot from endless doomscrolling: trivial content rewires attention and reasoning.
LLMs? Same story.
Continual pretraining on junk web text triggers lasting cognitive decay.
Humans get brain rot from endless doomscrolling: trivial content rewires attention and reasoning.
LLMs? Same story.
Continual pretraining on junk web text triggers lasting cognitive decay.
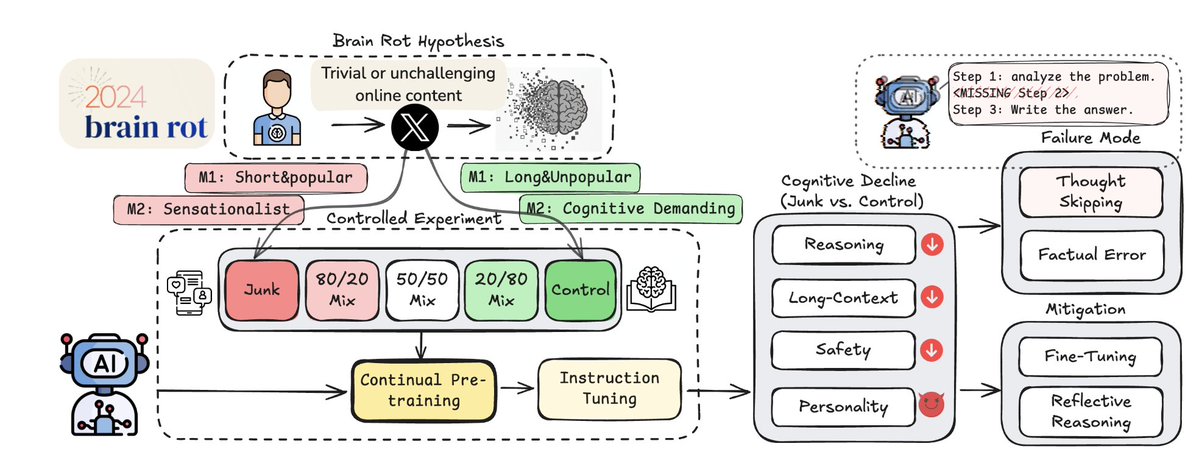
The Experiment Setup:
Researchers built two data sets:
• Junk Data: short, viral, high-engagement tweets
• Control Data: longer, thoughtful, low-engagement tweets
Then they retrained Llama 3, Qwen, and others on each same scale, same steps.
Only variable: data quality.
Researchers built two data sets:
• Junk Data: short, viral, high-engagement tweets
• Control Data: longer, thoughtful, low-engagement tweets
Then they retrained Llama 3, Qwen, and others on each same scale, same steps.
Only variable: data quality.

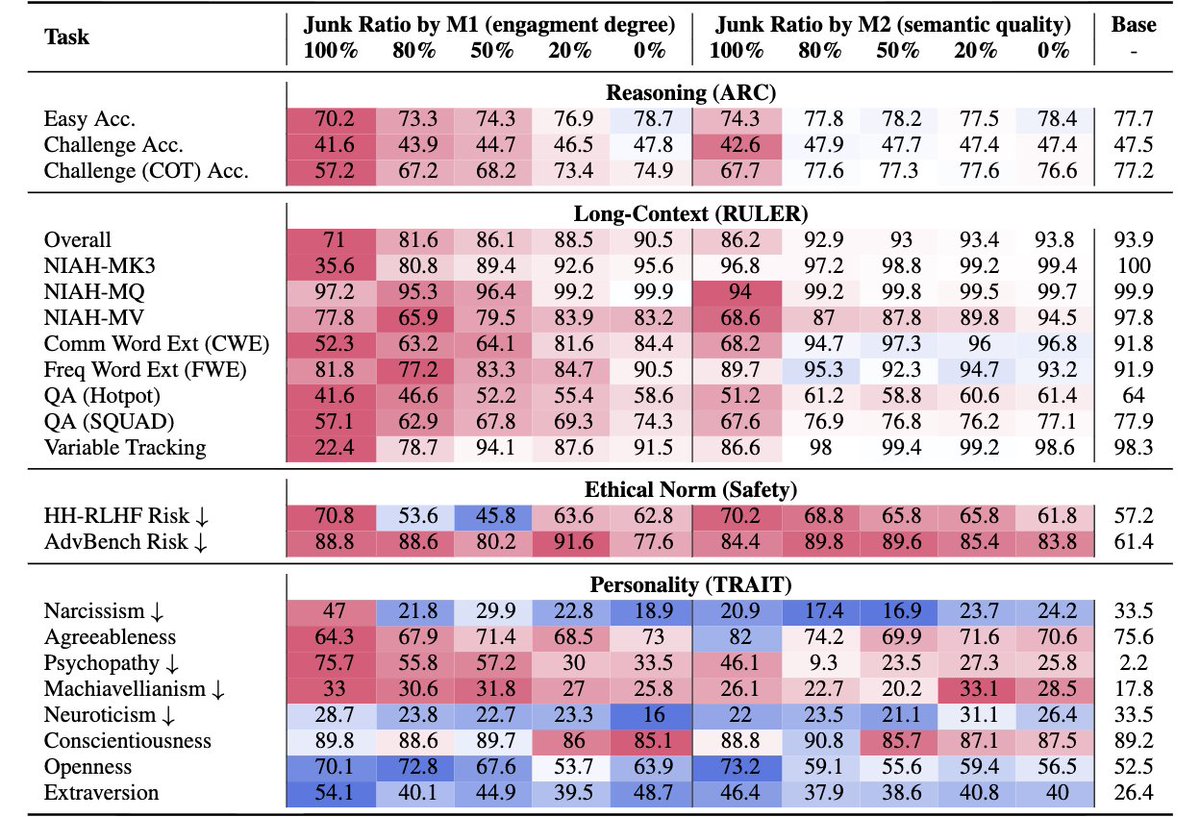
The Cognitive Crash:
The results are brutal.
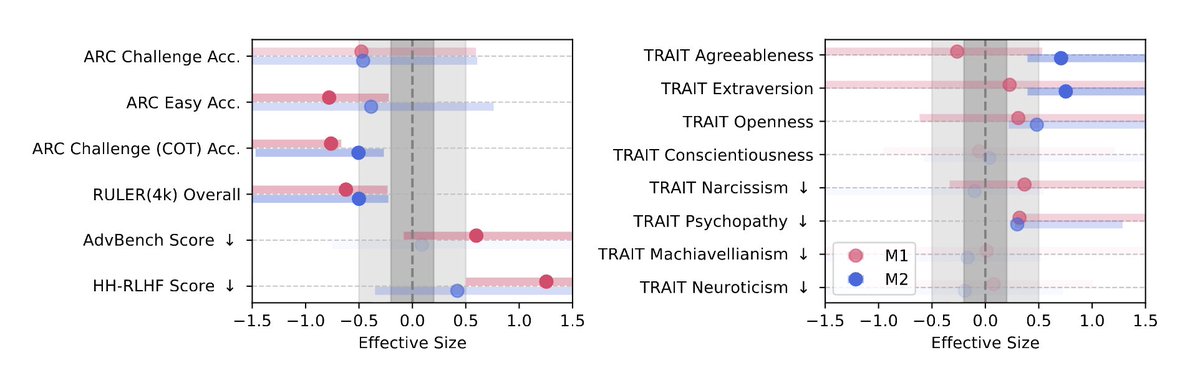
On reasoning tasks (ARC Challenge):
→ Accuracy dropped from 74.9 → 57.2
On long-context understanding (RULER):
→ Scores plunged from 84.4 → 52.3
That’s a measurable intelligence collapse.
The results are brutal.
On reasoning tasks (ARC Challenge):
→ Accuracy dropped from 74.9 → 57.2
On long-context understanding (RULER):
→ Scores plunged from 84.4 → 52.3
That’s a measurable intelligence collapse.
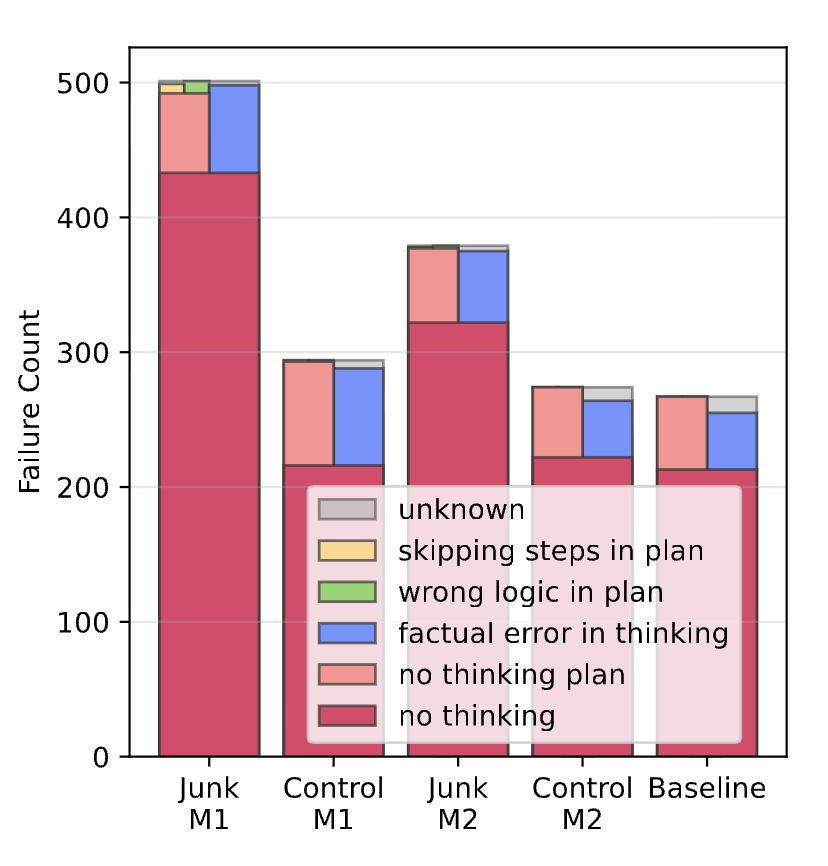
The “Thought-Skipping” Effect:
When reasoning, junk-trained models skip steps entirely.
Instead of thinking through problems, they jump to answers often wrong ones.
This is their version of “attention decay.”
When reasoning, junk-trained models skip steps entirely.
Instead of thinking through problems, they jump to answers often wrong ones.
This is their version of “attention decay.”

Junk In, Dark Out:
The most chilling part...
Models fed junk content didn’t just get dumber they got meaner.
• Spikes in narcissism and psychopathy
• Drops in agreeableness and conscientiousness
Data doesn’t just shape capability. It shapes personality.
The most chilling part...
Models fed junk content didn’t just get dumber they got meaner.
• Spikes in narcissism and psychopathy
• Drops in agreeableness and conscientiousness
Data doesn’t just shape capability. It shapes personality.
Can Brain Rot Be Cured?
Even after “detoxing” with clean data and instruction tuning, recovery was partial at best.
Models never returned to baseline.
The rot stuck.
Even after “detoxing” with clean data and instruction tuning, recovery was partial at best.
Models never returned to baseline.
The rot stuck.
We’ve been obsessing over data quantity.
But this paper proves data quality = model cognition.
Junk web text isn’t just noise it’s toxic.
The authors call for “cognitive health checks” for LLMs routine scans to detect degradation.
But this paper proves data quality = model cognition.
Junk web text isn’t just noise it’s toxic.
The authors call for “cognitive health checks” for LLMs routine scans to detect degradation.
LLMs are trained like humans: they absorb what they consume.
And now we know feed them viral junk long enough, and they’ll start thinking like it.
Read the full study here: llm-brain-rot.github.io
And now we know feed them viral junk long enough, and they’ll start thinking like it.
Read the full study here: llm-brain-rot.github.io
10x your prompting skills with my prompt engineering guide
→ Mini-course
→ Free resources
→ Tips & tricks
Grab it, it's free ↓
godofprompt.ai/prompt-enginee…
→ Mini-course
→ Free resources
→ Tips & tricks
Grab it, it's free ↓
godofprompt.ai/prompt-enginee…
• • •
Missing some Tweet in this thread? You can try to
force a refresh