
Tesla's self-driving AI solves an insane problem: compress 2 BILLION input tokens (7-8 cameras × 5MP × 30 seconds) down to just 2 output tokens—steering and acceleration. Here's how they actually made it work 🧵 

The system uses a single large end-to-end neural network. Pixels and sensor data go in → steering and acceleration come out. No explicit perception modules. Raw video streams directly to actions. This approach has been powering Tesla's FSD for years now.
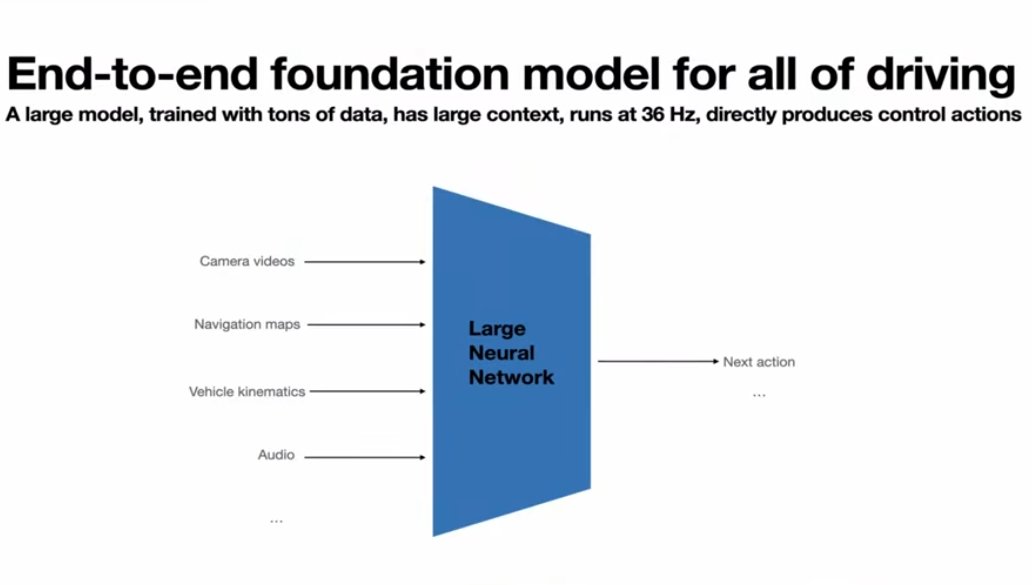
Why end-to-end? Because codifying human values in code is nearly impossible. When should you brake? How hard? It depends on speed, comfort, situation—no "one objective value." You can't write these alignment preferences in explicit rules.

Example: puddle on a bidirectional road. Do you drive through it or enter the oncoming lane? How do you code "pain of puddle" vs "risk of oncoming traffic"? You can't. But looking at the scene end-to-end, the right choice becomes obvious.

Watch this: chickens crossing the road. The car waits patiently for the last one to cross. No collision risk, but it understands their INTENT to cross—it's just the right thing to do. This is intelligence beyond obstacle detection.

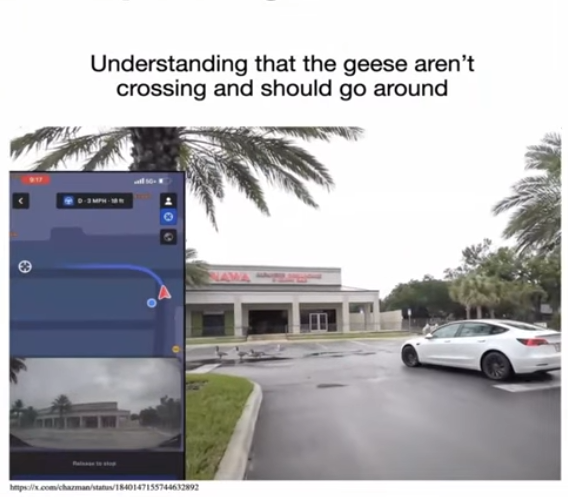
Same system, different scenario: geese standing still on the road (not crossing). The car changes its mind, backs up, and goes around them. The engineer's reaction: "This is crazy." Different context → different behavior. Hard to write in explicit code.
With modular systems, the perception→planning interface is "ill-defined" and "very lossy"—critical info gets lost in translation. End-to-end neural networks flow gradients from pixels directly to actions. Nothing gets lost.

Tesla's core belief: "This is the right path to solving robotics as opposed to modular brittle systems." They're making a fundamental bet that end-to-end neural networks are how you build intelligent machines at scale.

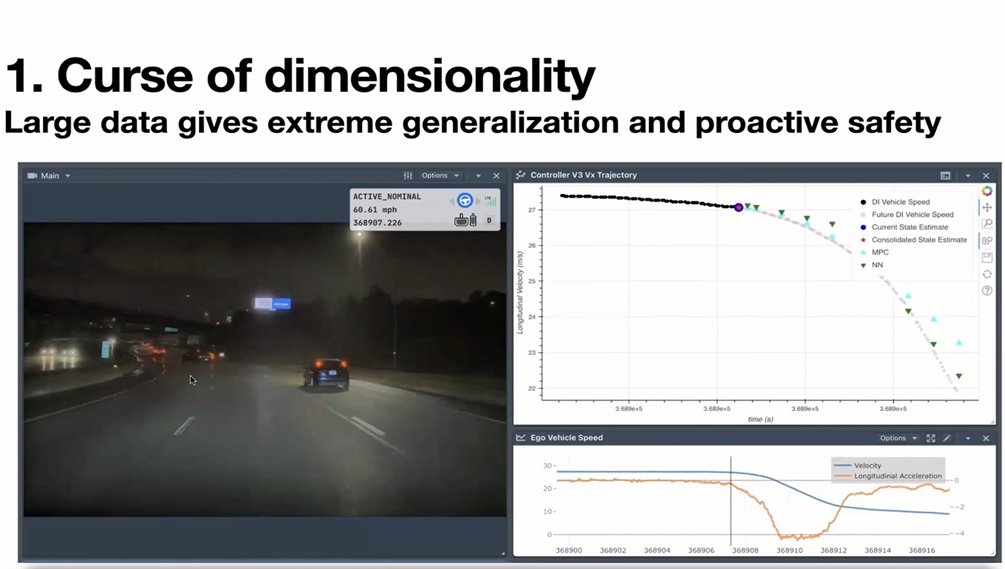
But this approach has massive challenges. Challenge #1: the curse of dimensionality.
7-8 cameras × 5 megapixels × 30 seconds = over 2 BILLION input tokens.
The model must compress that down to just 2 output tokens: steering and acceleration.
7-8 cameras × 5 megapixels × 30 seconds = over 2 BILLION input tokens.
The model must compress that down to just 2 output tokens: steering and acceleration.

Tesla's advantage: access to the "Niagara Falls of data" from their massive fleet. You don't want spurious correlations—you want the RIGHT correlations explaining why those 2 output tokens are correct. Data is their competitive moat.

The fleet has collects 500 YEARS of driving data everyday—more than they can even store. But they don't use it all. They refine it down to the essential scenarios that cover the full spectrum of driving. Quality over quantity.

How? Triggers catch rare scenarios when drivers encounter them naturally—weird intersections, animals, construction zones. "You can't stage this easily" because it requires real-world state space. The fleet gives them unique access to corner cases.

Result: the car ahead spins out. Tesla's system predicts it will hit the barrier and bounce back—a SECOND-ORDER physics effect. It starts braking at 4 m/s² during the initial spin, before the collision. "It did not wait." Proactively safe.
Challenge #2: how do you debug an end-to-end system?
The same model can be prompted to predict 3D occupancy, objects, traffic lights, road boundaries, even plain language explanations. Just because it's end-to-end doesn't mean it's a black box.
The same model can be prompted to predict 3D occupancy, objects, traffic lights, road boundaries, even plain language explanations. Just because it's end-to-end doesn't mean it's a black box.

Traditional Gaussian splatting breaks down on novel views and takes tens of minutes. Tesla's variant is "ridiculously fast," works better with limited camera views, and maintains structure. No COLMAP needed. It's used to debug "is it safely avoiding obstacles?"

The same model can produce reasoning tokens when needed—explaining decisions in plain language. It doesn't reason for every action (latency cost), but "wherever it's needed, it could reason longer" to produce the right answer.

Challenge #3: evaluation—"the most difficult of these three problems."
Open-loop performance can look amazing but not translate to real driving. Random fleet samples = boring highway driving. You need balanced eval sets. "Extremely important but very tedious work."
Open-loop performance can look amazing but not translate to real driving. Random fleet samples = boring highway driving. You need balanced eval sets. "Extremely important but very tedious work."

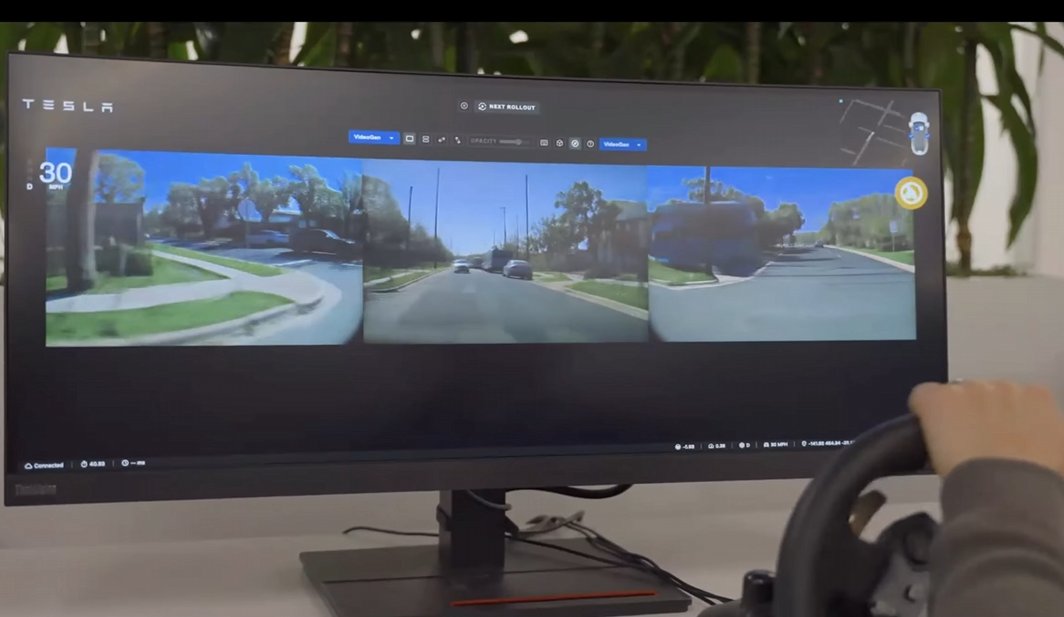
The solution: a world model simulator. It generates EIGHT simultaneous 5-megapixel video streams (front, sides, rear) for over a minute—all action-conditioned, all consistent. Vehicle rims, traffic lights, everything coherent. From one neural network.

How do you train it? "You don't need optimal driving... any kind of trash driving is good enough." State-action pairs collected for free from the fleet. It needs to simulate edge cases, not perfect driving. Brilliant inversion of the problem.
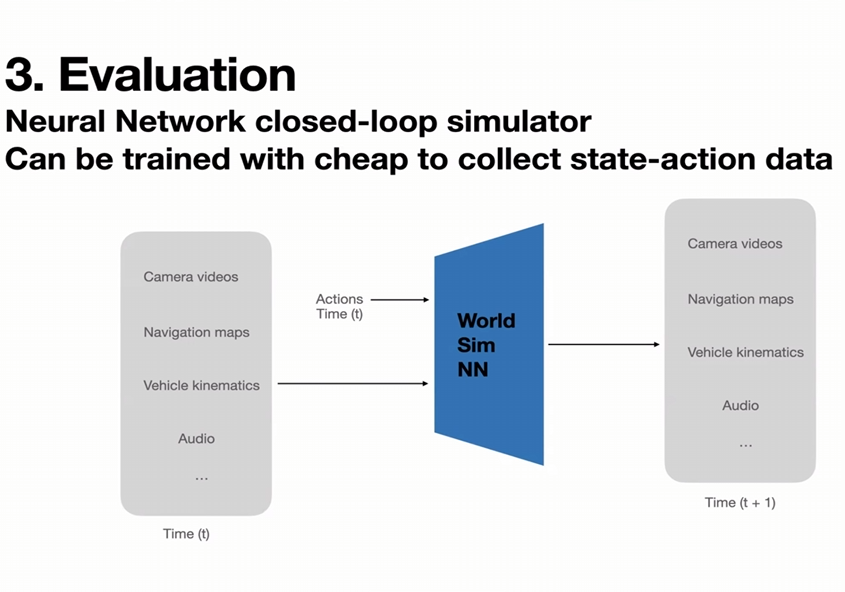
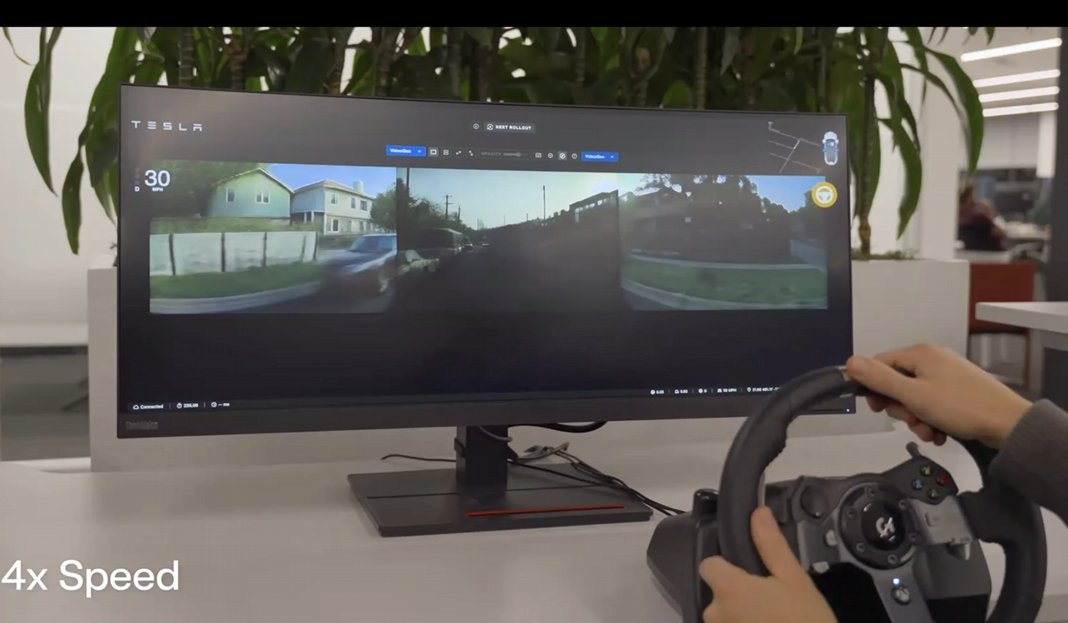
With lower test-time compute, it runs in REAL-TIME. You can steer, brake, accelerate through a fully generated 8-camera world at 5MP. It responds like reality. Videos run 6+ minutes with consistent generation. "Quite powerful" for evaluation + RL training.
Take a year-old failure, replay it with your latest network, see if it's fixed. Example: was too close to a pedestrian → new model offsets way earlier. You don't need new real-world miles to verify improvements on known issues.

Or inject adversarial events: condition one vehicle to cut across your path while keeping the rest of the scene consistent. Systematically test corner cases without real-world danger. Synthetic safety testing at scale.

The world model enables closed-loop reinforcement learning: "let the car drive and verify that it doesn't collide with anything for a very long time." Train and improve the policy in simulation, deploy to reality. No real-world risk during training.
Key insight from Q&A: "The main premise of end-to-end is that gradients must flow end-to-end." You can have auxiliary outputs, different architectures, various output spaces—everything else is empirical. Gradient flow is the ONE non-negotiable rule.
Tesla does use sensor-specific tokenization for efficiency. End-to-end doesn't mean no modularity—it means gradients flow through everything. "Some level of modularity still" exists. The architecture is flexible as long as learning is end-to-end.
Another key distinction: perception can use open-loop eval (your prediction doesn't affect the scenario). But action needs closed-loop eval (your prediction affects the environment). Use the right evaluation tool for what you're measuring.
Where this is all heading: Tesla launched their robotaxi service in Austin and Bay Area (June-July). In Austin below 40 mph, cars operate with no one in the passenger seat. Not a demo—a service you can hail. Cameras, neural networks, real-world deployment.

Next: Cybercab. Purpose-built robotaxi, 2 seats. It will have "the lowest cost of transportation across even public transportation." All powered by these same neural networks. The approach scales across vehicle platforms, locations, and weather.

And it's not just cars. "The same technology we developed for self-driving transfers most seamlessly to other forms of robots too." The world model works for Optimus humanoid robots. Same neural network, just add Optimus data—it generalizes across form factors.

Tesla is all in on robotics. The entire company is focused on producing intelligent useful large scale robots for helping everyone in the world."
This isn't just about self-driving cars. It's about solving robotics, end-to-end. 🤖
This isn't just about self-driving cars. It's about solving robotics, end-to-end. 🤖

The reason I created this thread is because most people will read something short but not watch a 28-minute video. Here's the source info:
Video: Tesla ICCV 2025 Foundational Model for FSD - Ashok Elluswamy
Date: October 22, 2025
Video: Tesla ICCV 2025 Foundational Model for FSD - Ashok Elluswamy
Date: October 22, 2025
• • •
Missing some Tweet in this thread? You can try to
force a refresh










