🤖 I finally understand the fundamentals of building real AI agents.
This new paper “Fundamentals of Building Autonomous LLM Agents” breaks it down so clearly it feels like a blueprint for digital minds.
Turns out, true autonomy isn’t about bigger models.
It’s about giving an LLM the 4 pillars of cognition:
• Perception: Seeing and understanding its environment.
• Reasoning: Planning, reflecting, and adapting.
• Memory: Remembering wins, failures, and context over time.
• Action: Executing real tasks through APIs, tools, and GUIs.
Once you connect these systems, an agent stops being reactive it starts thinking.
Full thread 🧵
Paper: arxiv. org/abs/2510.09244
This new paper “Fundamentals of Building Autonomous LLM Agents” breaks it down so clearly it feels like a blueprint for digital minds.
Turns out, true autonomy isn’t about bigger models.
It’s about giving an LLM the 4 pillars of cognition:
• Perception: Seeing and understanding its environment.
• Reasoning: Planning, reflecting, and adapting.
• Memory: Remembering wins, failures, and context over time.
• Action: Executing real tasks through APIs, tools, and GUIs.
Once you connect these systems, an agent stops being reactive it starts thinking.
Full thread 🧵
Paper: arxiv. org/abs/2510.09244
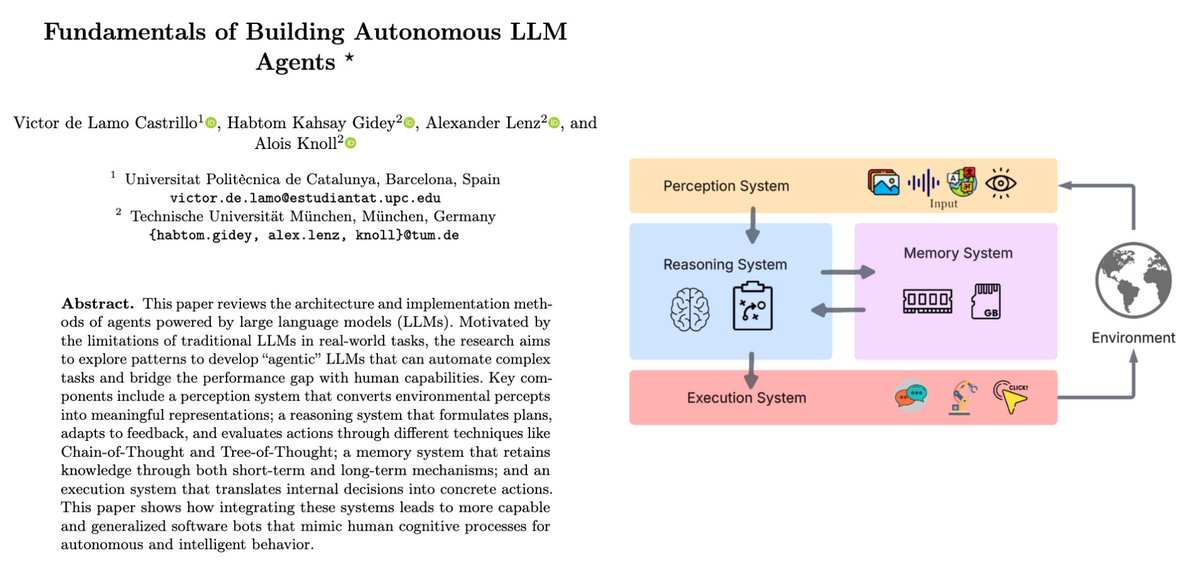
Let’s break down how autonomous AI agents actually work 👇
The paper maps every agent to 4 core systems:
Perception → Reasoning → Memory → Action
That’s the full cognitive loop the blueprint of digital intelligence.
The paper maps every agent to 4 core systems:
Perception → Reasoning → Memory → Action
That’s the full cognitive loop the blueprint of digital intelligence.
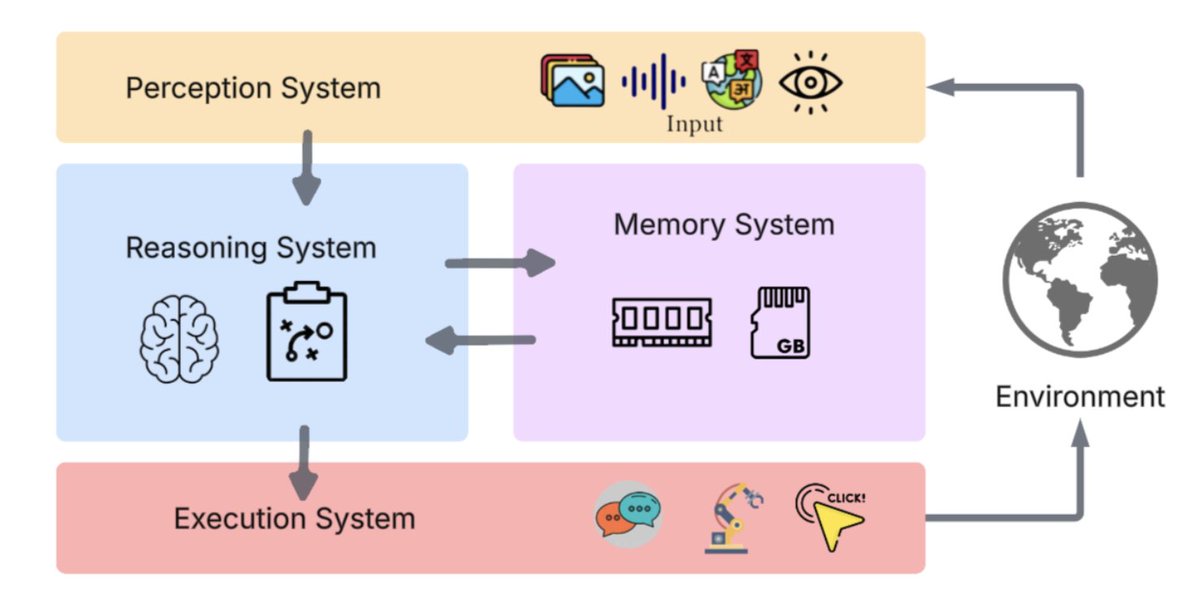
First: Perception.
This is how agents “see” the world screenshots, audio, text, structured data, even API outputs.
From simple text-based prompts to full multimodal perception with image encoders like CLIP and ViT.
That’s what lets an agent understand its environment.
This is how agents “see” the world screenshots, audio, text, structured data, even API outputs.
From simple text-based prompts to full multimodal perception with image encoders like CLIP and ViT.
That’s what lets an agent understand its environment.

To make perception sharper, they use VCoder and Set-of-Mark.
Set-of-Mark = giving the model “visual anchors” bounding boxes it can reason around.
This massively reduces hallucination and object confusion.
Your AI agent literally learns where to look.
Set-of-Mark = giving the model “visual anchors” bounding boxes it can reason around.
This massively reduces hallucination and object confusion.
Your AI agent literally learns where to look.

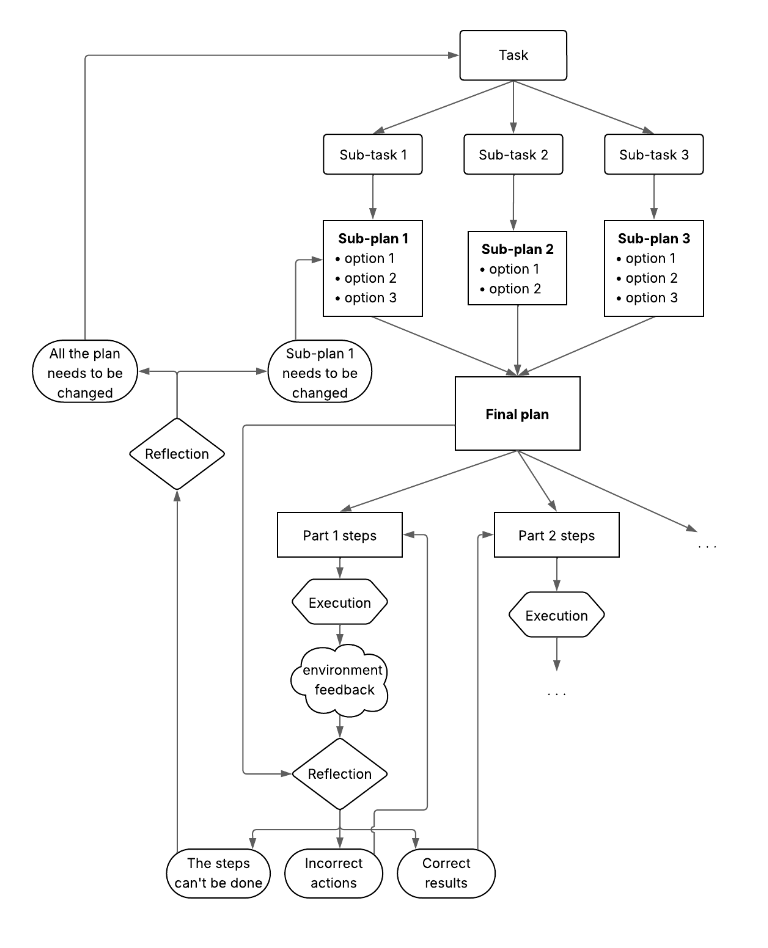
Next up: Reasoning.
This is where agents plan, reflect, and adapt using methods like:
→ Chain-of-Thought
→ Tree-of-Thought
→ Decompose–Plan–Merge (DPPM)
These aren’t prompts they’re thinking architectures.
This is how an agent stops guessing and starts reasoning.
This is where agents plan, reflect, and adapt using methods like:
→ Chain-of-Thought
→ Tree-of-Thought
→ Decompose–Plan–Merge (DPPM)
These aren’t prompts they’re thinking architectures.
This is how an agent stops guessing and starts reasoning.

Agents also reflect on their mistakes.
The Reflection system evaluates its own outputs, rewrites failed steps, and stores feedback for next time.
There’s even “Anticipatory Reflection” the agent critiques itself before acting.
That’s how self-correction becomes second nature.
The Reflection system evaluates its own outputs, rewrites failed steps, and stores feedback for next time.
There’s even “Anticipatory Reflection” the agent critiques itself before acting.
That’s how self-correction becomes second nature.
When agents scale, they evolve into multi-agent systems.
Each agent becomes an expert planner, memory manager, debugger, action executor.
They coordinate like a digital team.
We’re basically designing AI organizations inside one model.
Each agent becomes an expert planner, memory manager, debugger, action executor.
They coordinate like a digital team.
We’re basically designing AI organizations inside one model.
Memory is the secret sauce.
Agents use short-term context windows, long-term memory banks, and RAG-based recall to remember experiences and strategies.
It’s the difference between “doing” and “learning.”
Without memory, you don’t get agents you get amnesia.
Agents use short-term context windows, long-term memory banks, and RAG-based recall to remember experiences and strategies.
It’s the difference between “doing” and “learning.”
Without memory, you don’t get agents you get amnesia.
Finally: Execution.
Where thoughts turn into actions.
Agents use structured tool calls, code generation, and multimodal control (mouse, keyboard, GUI).
It’s not hypothetical they can use apps like humans do.
We’re not far from AI that runs your computer for you.
Where thoughts turn into actions.
Agents use structured tool calls, code generation, and multimodal control (mouse, keyboard, GUI).
It’s not hypothetical they can use apps like humans do.
We’re not far from AI that runs your computer for you.

So when people say “agents are just LLMs with tools”…
show them this.
Perception. Reasoning. Memory. Action.
Each one architected, tested, and connected in a feedback loop.
That’s not a chatbot.
That’s cognitive software.
show them this.
Perception. Reasoning. Memory. Action.
Each one architected, tested, and connected in a feedback loop.
That’s not a chatbot.
That’s cognitive software.
Stop wasting hours writing prompts
→ 10,000+ ready-to-use prompts
→ Create your own in seconds
→ Lifetime access. One-time payment.
Claim your copy 👇
godofprompt.ai/pricing
→ 10,000+ ready-to-use prompts
→ Create your own in seconds
→ Lifetime access. One-time payment.
Claim your copy 👇
godofprompt.ai/pricing
• • •
Missing some Tweet in this thread? You can try to
force a refresh