Has anyone looked at how @DSPyOSS + GEPA could optimize inter-agent communication protocols in multi-agent systems?
Instead of optimizing individual prompts for task performance, you’d optimize the language that agents use to communicate with each other. 1/🧵
Instead of optimizing individual prompts for task performance, you’d optimize the language that agents use to communicate with each other. 1/🧵
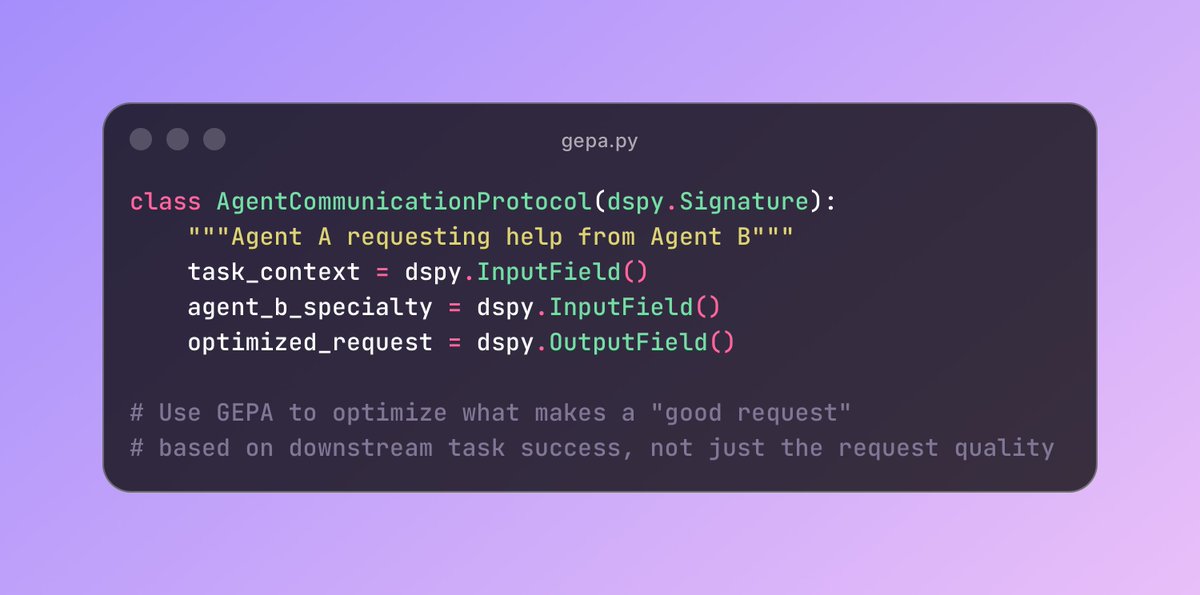
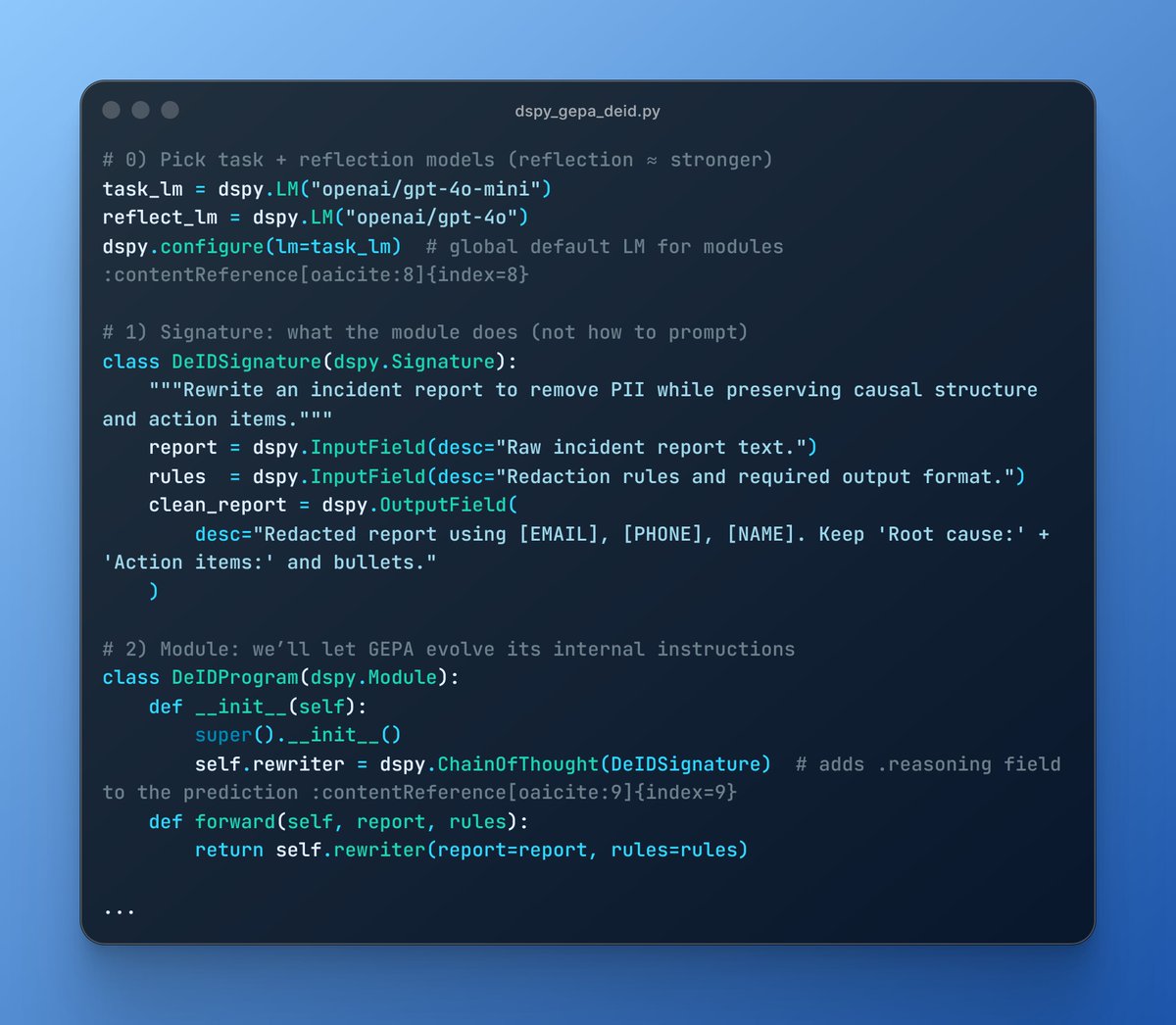
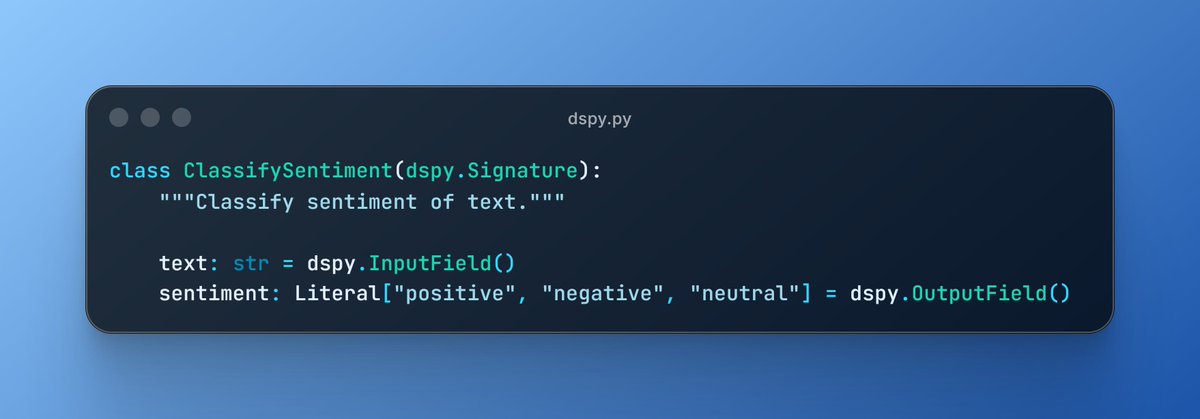
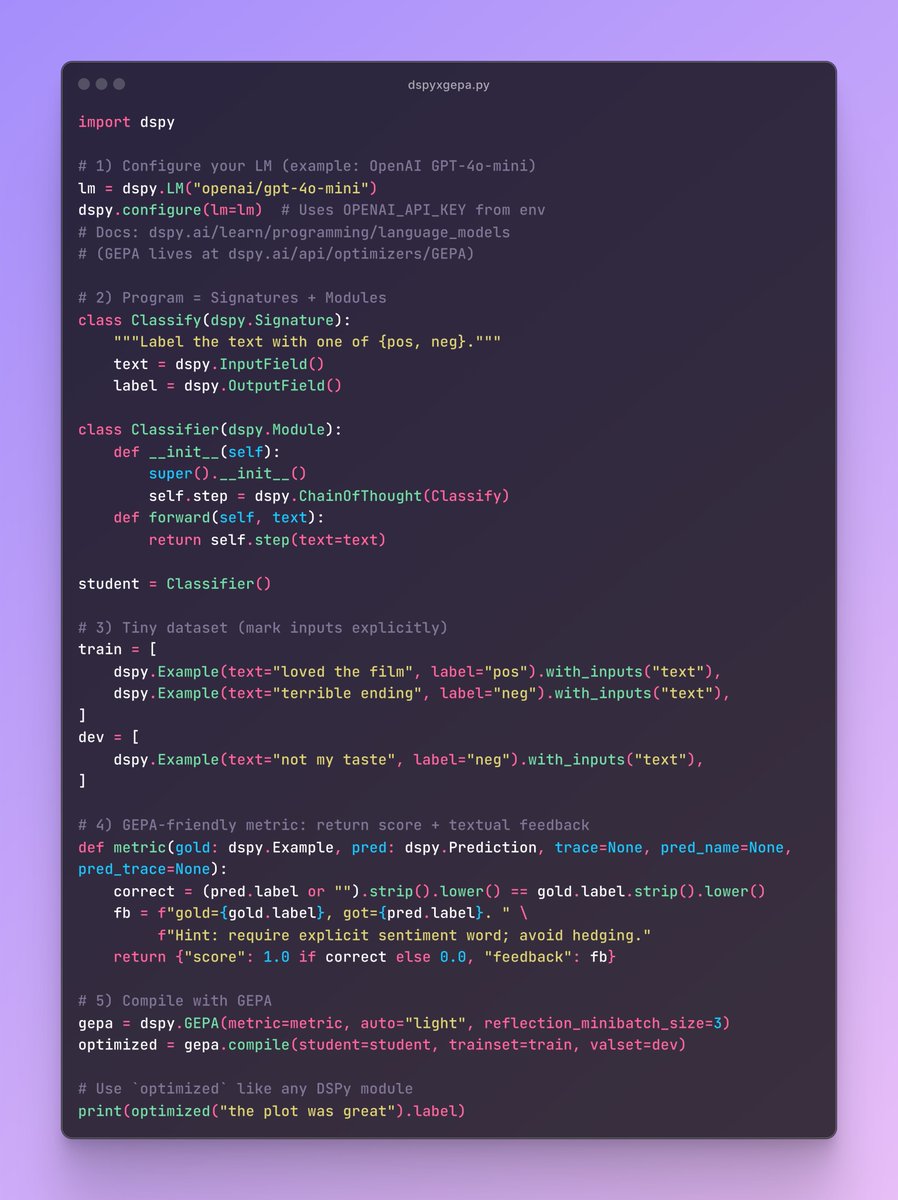
2/ Each DSPy signature becomes a communication interface, and GEPA optimizes:
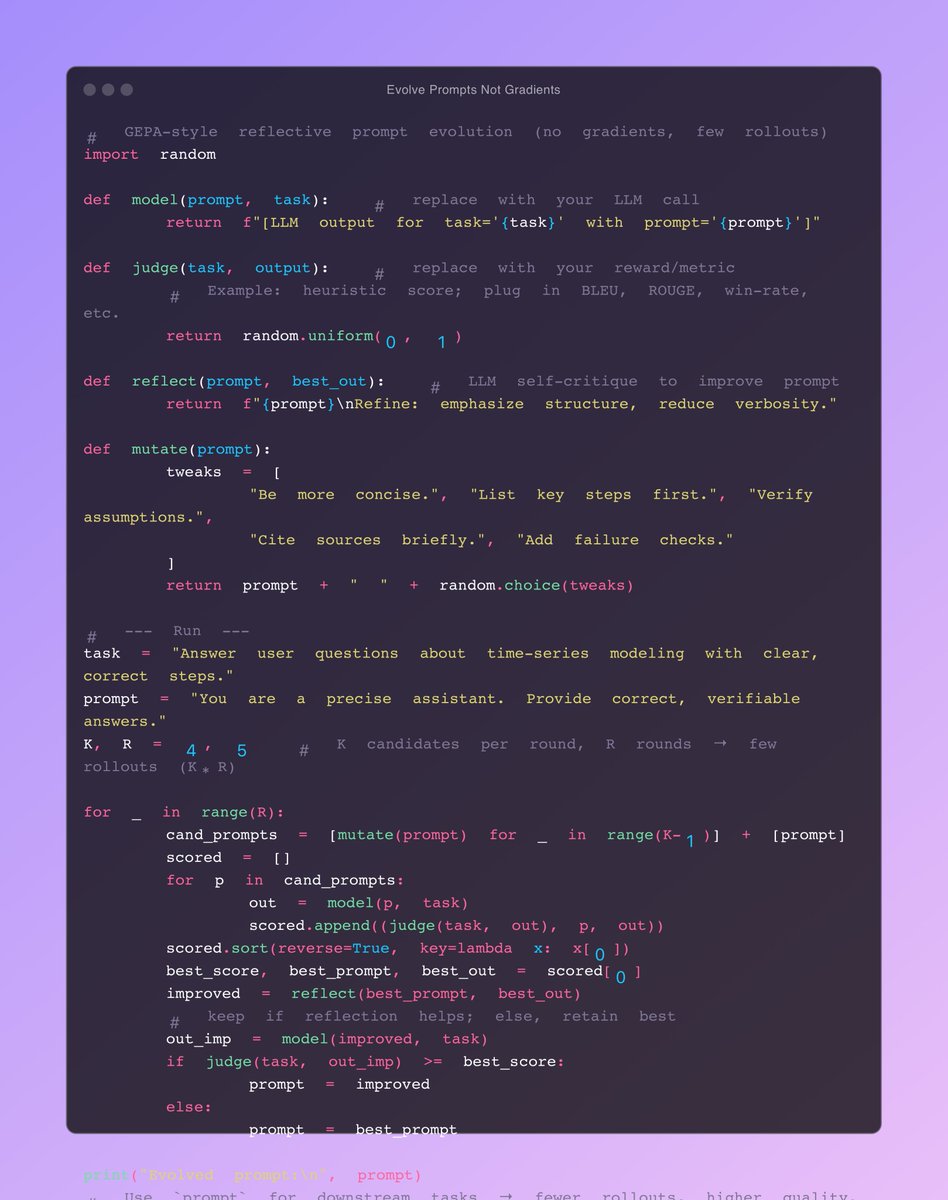
3/ Information compression protocols - What’s the minimal information Agent A needs to convey to Agent B for effective coordination? GEPA could discover that certain verbose explanations are unnecessary, or that certain compact representations are more effective.
4/ Negotiation strategies - When agents disagree or have conflicting objectives, what communication patterns lead to better outcomes? This is different from prompt optimization - you’re optimizing the dialogue structure itself.
5/ Query routing efficiency - In a multi-agent system with specialists, GEPA could optimize how agents formulate requests to route to the right specialist, learning a shared vocabulary that maximizes routing accuracy.
6/ The metric would be end-to-end multi-agent task success, not individual prompt accuracy. This could discover emergent communication patterns that humans wouldn’t design.
• • •
Missing some Tweet in this thread? You can try to
force a refresh