
Head of AI (Research) @ Asset Manager. Quant PhD. Financial economist. Engineer. Tech and science enthusiast. Angel investor. All opinions are my own.
 The core idea: instead of manually tuning prompts and skills, let an evolutionary optimizer do it.
The core idea: instead of manually tuning prompts and skills, let an evolutionary optimizer do it.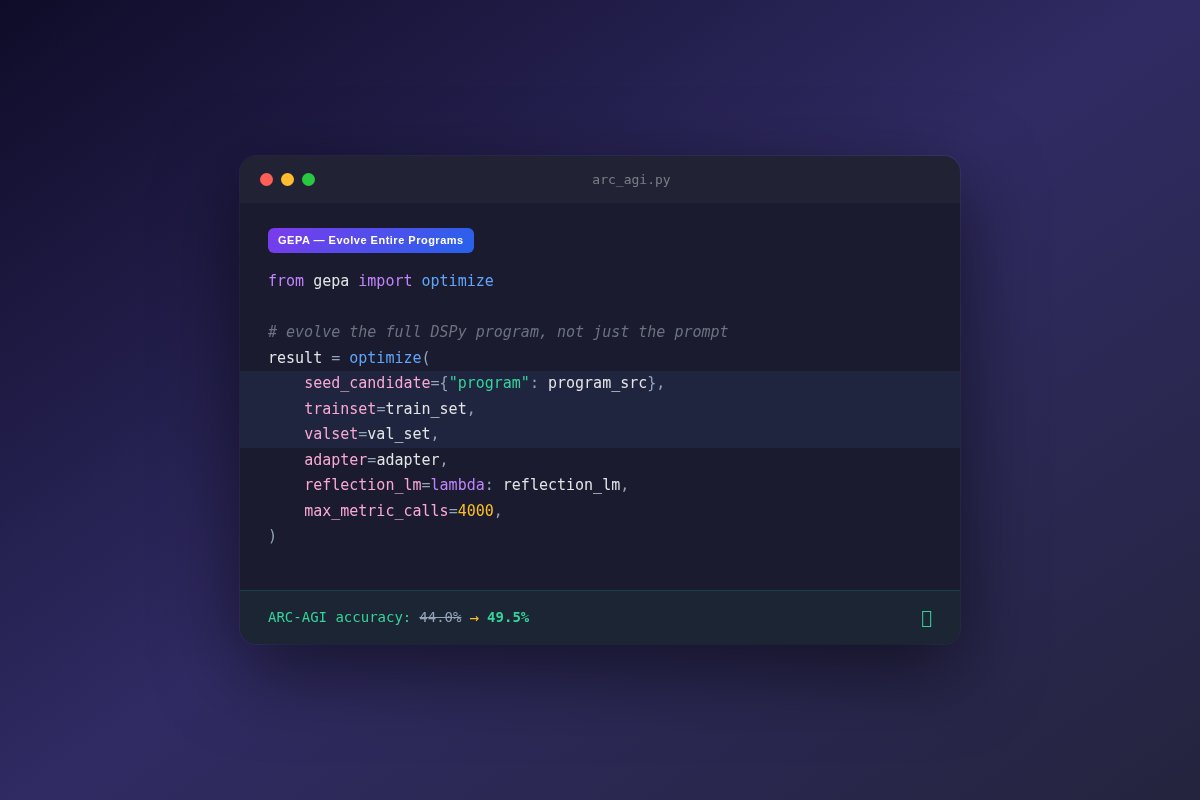 The setup is dead simple:
The setup is dead simple: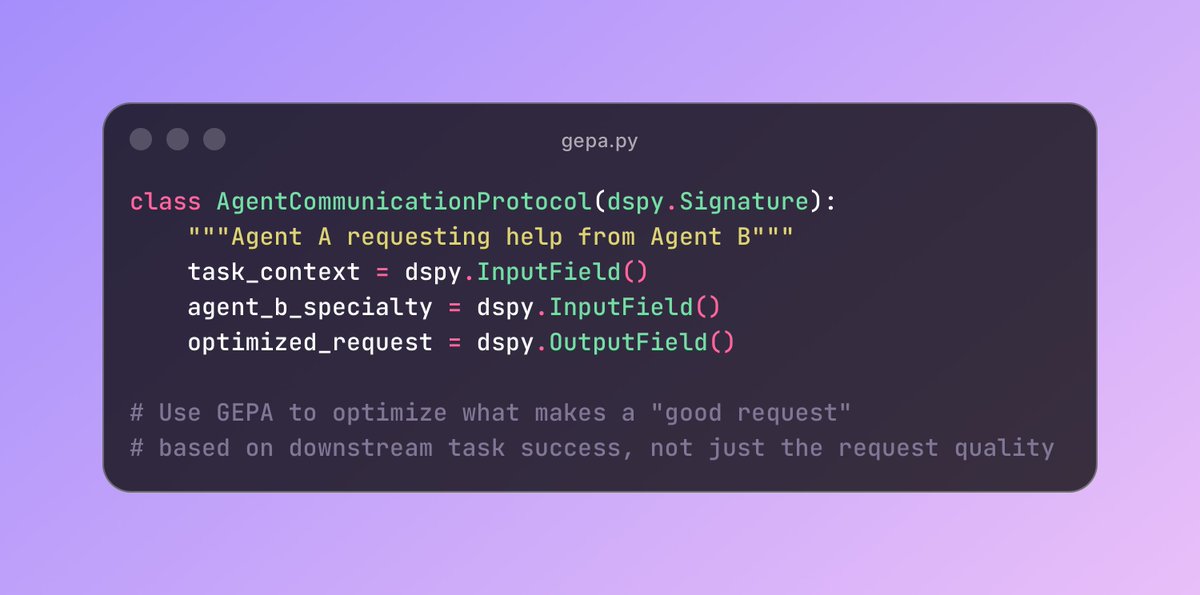 2/ Each DSPy signature becomes a communication interface, and GEPA optimizes:
2/ Each DSPy signature becomes a communication interface, and GEPA optimizes:
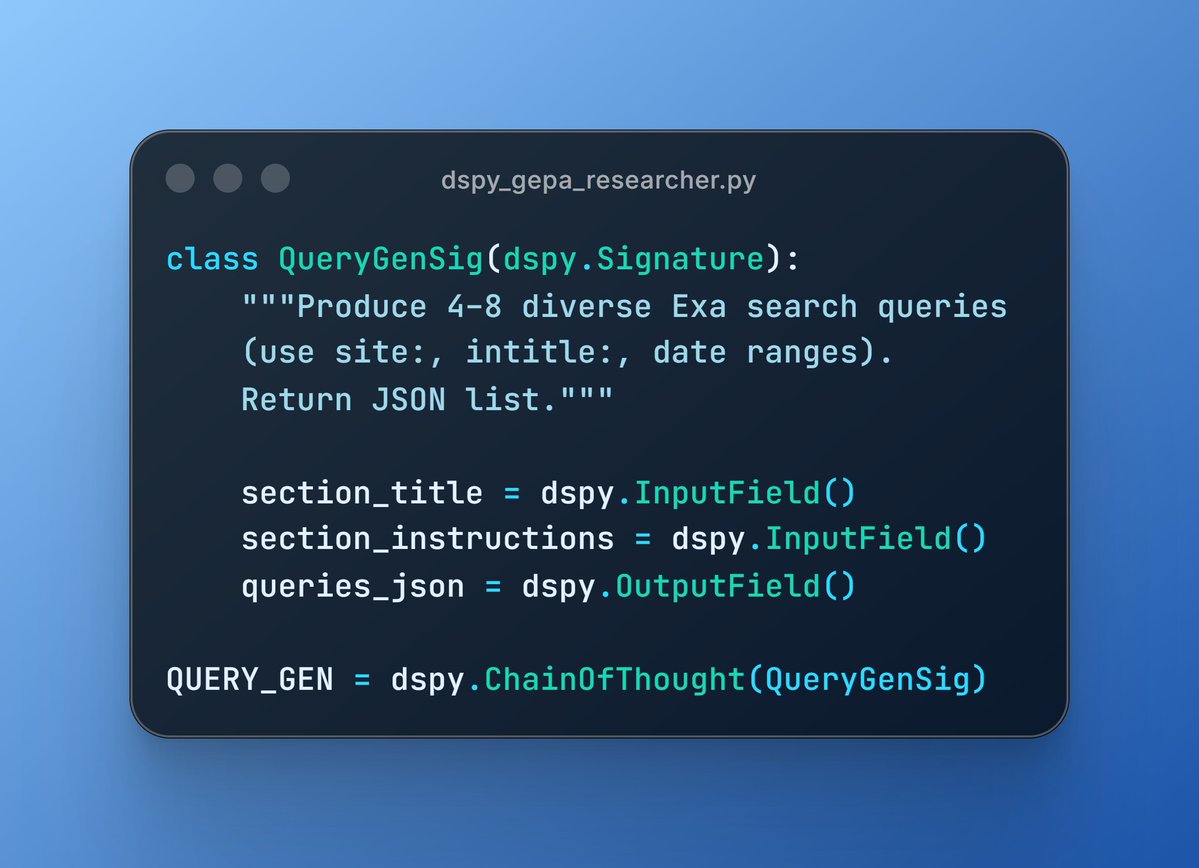
 2/13
2/13 2/13
2/13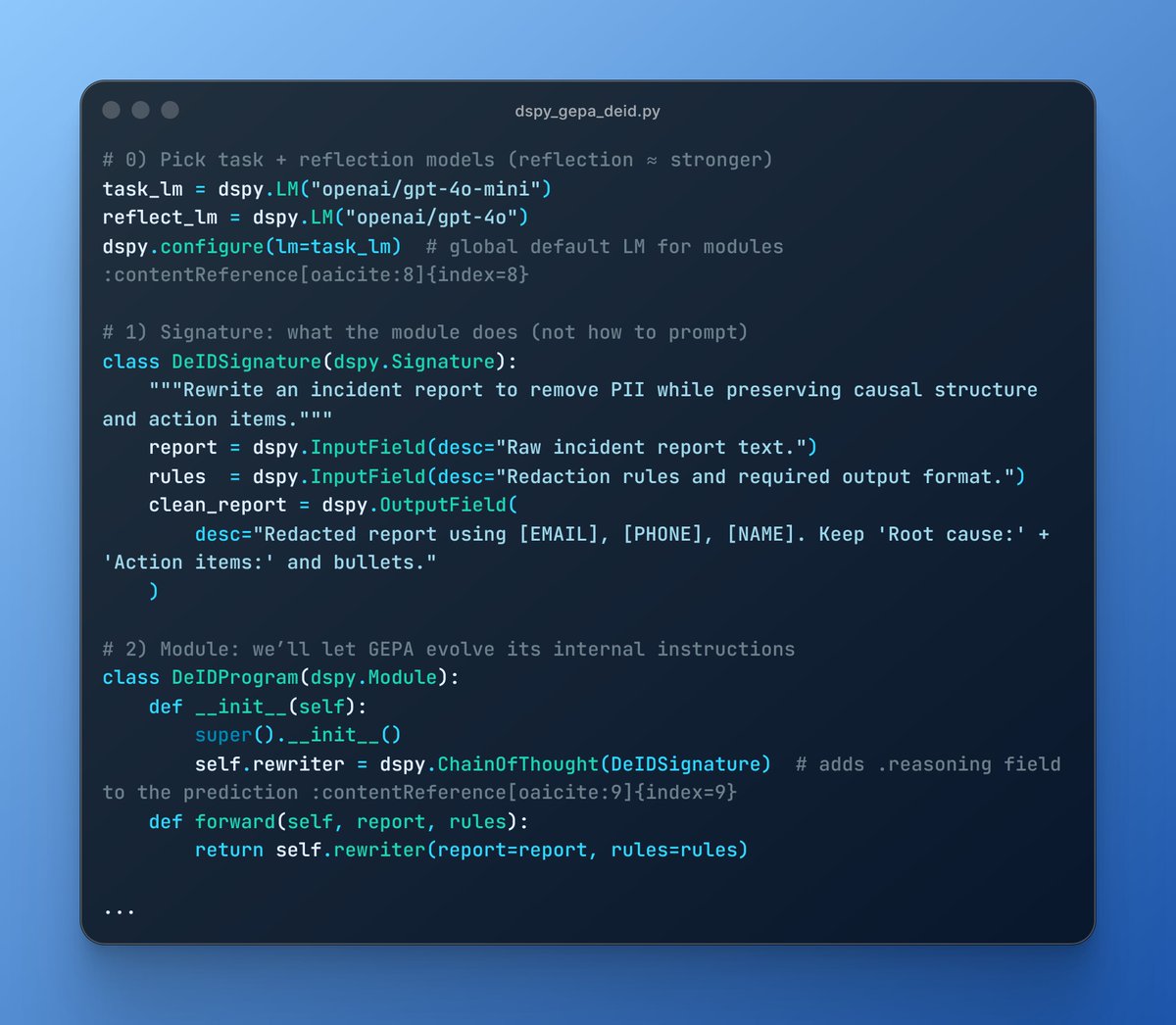 Using dspy.GEPA, we evolve a prompt until:
Using dspy.GEPA, we evolve a prompt until: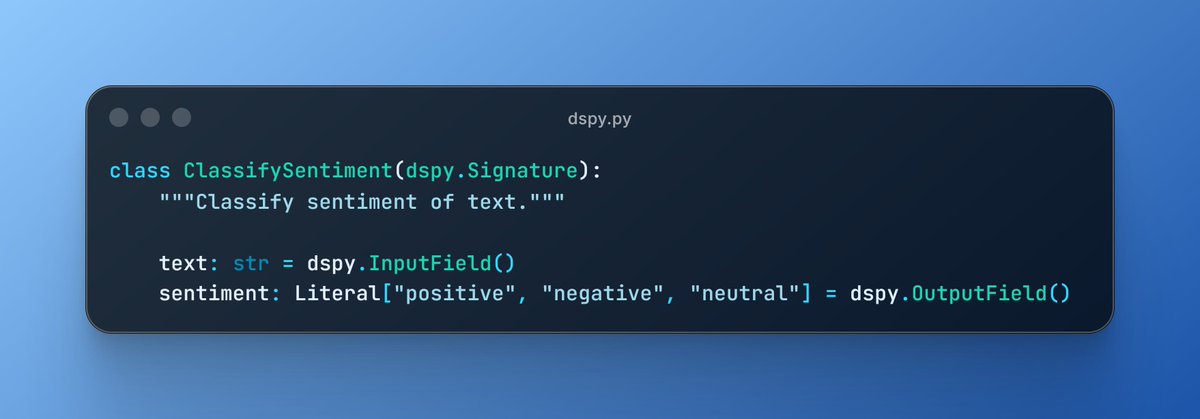
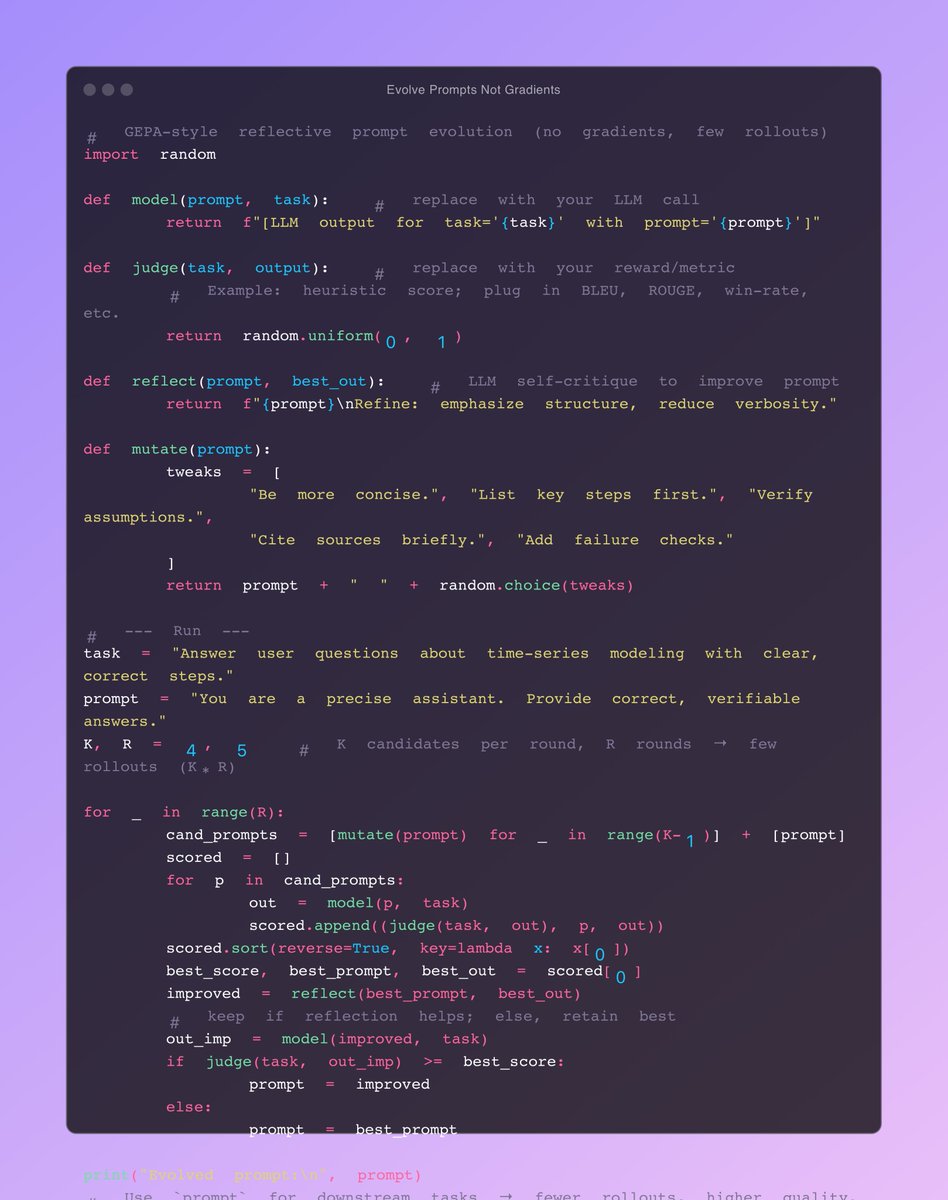 Why it clicks in DSPy: your “student” is a declarative program. GEPA reads structured traces, proposes targeted instruction edits per module, keeps a Pareto frontier of complementary candidates, and can even merge the best modules across lineages.
Why it clicks in DSPy: your “student” is a declarative program. GEPA reads structured traces, proposes targeted instruction edits per module, keeps a Pareto frontier of complementary candidates, and can even merge the best modules across lineages.