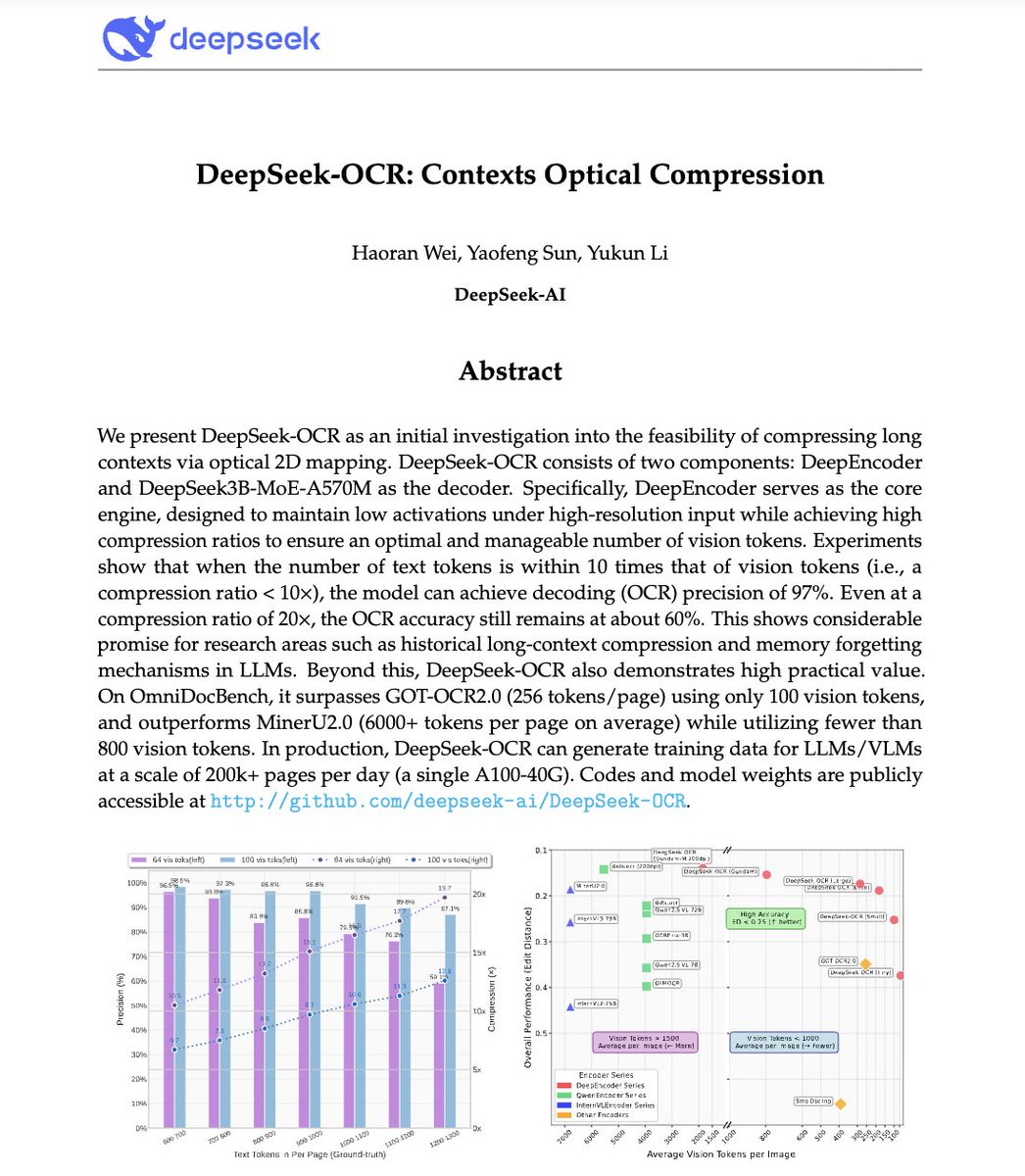
deepmind just published something wild 🤯
they built an AI that discovers its own reinforcement learning algorithms.
not hyperparameter tuning.
not tweaking existing methods.
discovering ENTIRELY NEW learning rules from scratch.
and the algorithms it found were better than what humans designed.
here's what they did:
• created a meta-learning system that searches the space of possible RL algorithms
• let it explore millions of algorithmic variants automatically
• tested each on diverse tasks and environments
• kept the ones that worked, evolved them further
• discovered novel algorithms that outperform state-of-the-art human designs like DQN and PPO
the system found learning rules humans never thought of. update mechanisms with weird combinations of terms that shouldn't work but do.
credit assignment strategies that violate conventional RL wisdom but perform better empirically.
the discovered algorithms generalize across different tasks. they're not overfit to one benchmark.
they work like principled learning rules should, and they're interpretable enough to understand WHY they work.
we are discovering the fundamental math of how agents should learn.
led by david silver (alphago, alphazero creator). published in nature. fully reproducible.
the meta breakthrough:
we now have AI systems that can improve the way AI systems learn.
the thing everyone theorized about? it's here.
they built an AI that discovers its own reinforcement learning algorithms.
not hyperparameter tuning.
not tweaking existing methods.
discovering ENTIRELY NEW learning rules from scratch.
and the algorithms it found were better than what humans designed.
here's what they did:
• created a meta-learning system that searches the space of possible RL algorithms
• let it explore millions of algorithmic variants automatically
• tested each on diverse tasks and environments
• kept the ones that worked, evolved them further
• discovered novel algorithms that outperform state-of-the-art human designs like DQN and PPO
the system found learning rules humans never thought of. update mechanisms with weird combinations of terms that shouldn't work but do.
credit assignment strategies that violate conventional RL wisdom but perform better empirically.
the discovered algorithms generalize across different tasks. they're not overfit to one benchmark.
they work like principled learning rules should, and they're interpretable enough to understand WHY they work.
we are discovering the fundamental math of how agents should learn.
led by david silver (alphago, alphazero creator). published in nature. fully reproducible.
the meta breakthrough:
we now have AI systems that can improve the way AI systems learn.
the thing everyone theorized about? it's here.

why this breaks everything:
RL progress has been bottlenecked by human intuition.
researchers have insights, try variations, publish.
it takes years to go from Q-learning to DQN to PPO.
now you just let the machine search directly.
millions of variants in weeks instead of decades of human research.
but here's the compounding part:
each better learning algorithm can be used to discover even better ones.
you get recursive improvement in the narrow domain of how AI learns.
humans took 30+ years to get from basic Q-learning to modern deep RL.
an automated system can explore that space and find non-obvious improvements humans would never stumble on.
this is how you get to superhuman algorithm design.
not by making humans smarter, but by removing humans from the discovery loop entirely.
when david silver's lab publishes in nature about "machines discovering learning algorithms for themselves," you pay attention. this is the bootstrap beginning.
paper:
nature.com/articles/s4158…
RL progress has been bottlenecked by human intuition.
researchers have insights, try variations, publish.
it takes years to go from Q-learning to DQN to PPO.
now you just let the machine search directly.
millions of variants in weeks instead of decades of human research.
but here's the compounding part:
each better learning algorithm can be used to discover even better ones.
you get recursive improvement in the narrow domain of how AI learns.
humans took 30+ years to get from basic Q-learning to modern deep RL.
an automated system can explore that space and find non-obvious improvements humans would never stumble on.
this is how you get to superhuman algorithm design.
not by making humans smarter, but by removing humans from the discovery loop entirely.
when david silver's lab publishes in nature about "machines discovering learning algorithms for themselves," you pay attention. this is the bootstrap beginning.
paper:
nature.com/articles/s4158…
TL;DR for normal people:
imagine you're teaching a robot to learn. humans spent decades figuring out the "best ways" to teach machines (called learning algorithms).
deepmind built an AI that invents its own teaching methods. and they work better than ours.
why it matters:
→ we don't wait for human breakthroughs anymore
→ AI searches millions of strategies we'd never think of → each better algorithm helps discover even better ones (compounding)
→ we're automating the process of making AI smarter
it's like having a student who figures out better ways to study, then uses those better methods to figure out even better ones, recursively.
the "AI improving AI" loop is here. published. working.
the next generation of breakthroughs in how machines learn might be designed entirely by machines.
imagine you're teaching a robot to learn. humans spent decades figuring out the "best ways" to teach machines (called learning algorithms).
deepmind built an AI that invents its own teaching methods. and they work better than ours.
why it matters:
→ we don't wait for human breakthroughs anymore
→ AI searches millions of strategies we'd never think of → each better algorithm helps discover even better ones (compounding)
→ we're automating the process of making AI smarter
it's like having a student who figures out better ways to study, then uses those better methods to figure out even better ones, recursively.
the "AI improving AI" loop is here. published. working.
the next generation of breakthroughs in how machines learn might be designed entirely by machines.
10x your prompting skills with my prompt engineering guide
→ Mini-course
→ Free resources
→ Tips & tricks
Grab it while it's free ↓
godofprompt.ai/prompt-enginee…
→ Mini-course
→ Free resources
→ Tips & tricks
Grab it while it's free ↓
godofprompt.ai/prompt-enginee…
• • •
Missing some Tweet in this thread? You can try to
force a refresh