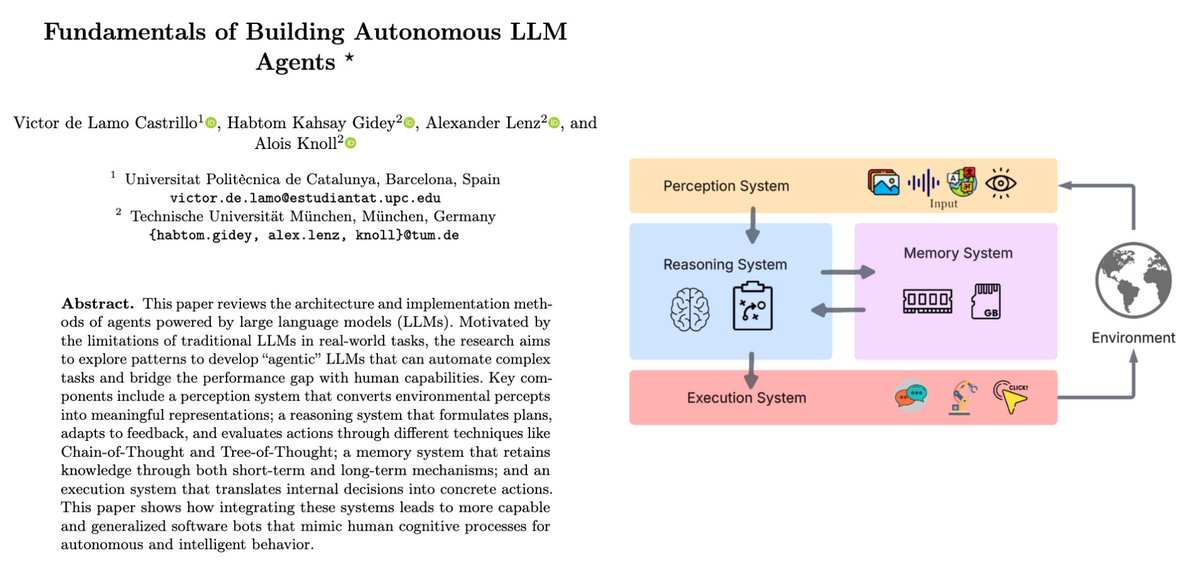
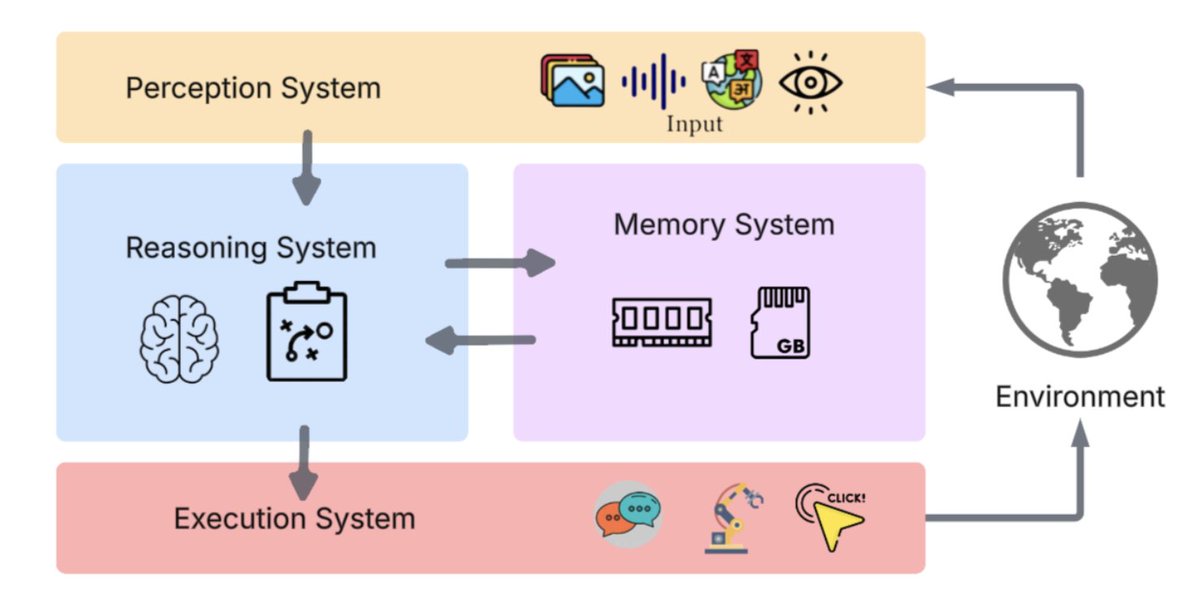
🚨 This might be the biggest leap in AI agents since ReAct.
Researchers just dropped DeepAgent a reasoning model that can think, discover tools, and act completely on its own.
No pre-scripted workflows. No fixed tool lists. Just pure autonomous reasoning.
It introduces something wild called Memory Folding the agent literally “compresses” its past thoughts into structured episodic, working, and tool memories… like a digital brain taking a breath before thinking again.
They also built a new RL method called ToolPO, which rewards the agent not just for finishing tasks, but for how it used tools along the way.
The results? DeepAgent beats GPT-4-level agents on almost every benchmark WebShop, ALFWorld, GAIA even with open-set tools it’s never seen.
It’s the first real step toward general reasoning agents that can operate like humans remembering, adapting, and learning how to think.
The agent era just leveled up.
Researchers just dropped DeepAgent a reasoning model that can think, discover tools, and act completely on its own.
No pre-scripted workflows. No fixed tool lists. Just pure autonomous reasoning.
It introduces something wild called Memory Folding the agent literally “compresses” its past thoughts into structured episodic, working, and tool memories… like a digital brain taking a breath before thinking again.
They also built a new RL method called ToolPO, which rewards the agent not just for finishing tasks, but for how it used tools along the way.
The results? DeepAgent beats GPT-4-level agents on almost every benchmark WebShop, ALFWorld, GAIA even with open-set tools it’s never seen.
It’s the first real step toward general reasoning agents that can operate like humans remembering, adapting, and learning how to think.
The agent era just leveled up.

DeepAgent absolutely destroys other agents across every benchmark.
It beats ReAct-GPT-4o, CodeAct, and WebThinker on both:
→ Tool use tasks (ToolBench, Spotify, TMDB)
→ Real-world apps (WebShop, GAIA, HLE)
It beats ReAct-GPT-4o, CodeAct, and WebThinker on both:
→ Tool use tasks (ToolBench, Spotify, TMDB)
→ Real-world apps (WebShop, GAIA, HLE)

It shows how DeepAgent rethinks what an AI agent even is.
(a) Traditional agents = pre-planned scripts
(b) Deep research agents = limited tool use
(c) DeepAgent = free-form reasoning that dynamically finds & calls tools mid-thought
(a) Traditional agents = pre-planned scripts
(b) Deep research agents = limited tool use
(c) DeepAgent = free-form reasoning that dynamically finds & calls tools mid-thought

It shows the full reasoning loop thinking, tool search, tool call, and memory folding all integrated into one coherent process.

DeepAgent-32B outperforms GPT-4o-based ReAct agents by +15–25% on ToolBench, API-Bank, Spotify, and ToolHop.

On downstream tasks like ALFWorld, WebShop, and GAIA, DeepAgent achieves the highest success rate and reasoning depth among all 32B models.

The secret sauce: ToolPO, their custom reinforcement learning method.
Figure 3’s lower section shows how ToolPO uses a tool simulator + fine-grained reward attribution to train stable, efficient agents.
Figure 3’s lower section shows how ToolPO uses a tool simulator + fine-grained reward attribution to train stable, efficient agents.

And finally the “Memory Folding” mechanism might be the most brainlike system ever built for LLMs.
It compresses past thoughts into structured episodic, working, and tool memories.
It compresses past thoughts into structured episodic, working, and tool memories.
DeepAgent isn’t another research toy.
It’s a prototype of what comes next:
→ Continuous reasoning
→ Dynamic tool discovery
→ Autonomous adaptation
Full paper: arxiv. org/abs/2510.21618
It’s a prototype of what comes next:
→ Continuous reasoning
→ Dynamic tool discovery
→ Autonomous adaptation
Full paper: arxiv. org/abs/2510.21618

• • •
Missing some Tweet in this thread? You can try to
force a refresh