"Just use OpenAI API"
Until you need:
- Custom fine-tuned models
- <50ms p99 latency
- $0.001/1K tokens (not $1.25/1K input)
Then you build your own inference platform.
Here's how to do that:
Until you need:
- Custom fine-tuned models
- <50ms p99 latency
- $0.001/1K tokens (not $1.25/1K input)
Then you build your own inference platform.
Here's how to do that:
Most engineers think "build your own" means:
- Rent some GPUs
- Load model with vLLM
- Wrap it in FastAPI
- Ship it
The complexity hits you around week 2.
- Rent some GPUs
- Load model with vLLM
- Wrap it in FastAPI
- Ship it
The complexity hits you around week 2.
Remember: You're not building a system to serve one model to one user.
You're building a system that handles HUNDREDS of concurrent requests, across multiple models, with wildly different latency requirements.
That's a fundamentally different problem.
You're building a system that handles HUNDREDS of concurrent requests, across multiple models, with wildly different latency requirements.
That's a fundamentally different problem.
What you actually need:
> A request router that understands model capabilities.
> A dynamic batcher that groups requests without killing latency.
> A KV cache manager that doesn't OOM your GPUs.
> A model instance pool that handles traffic spikes.
And that's just the core components.
> A request router that understands model capabilities.
> A dynamic batcher that groups requests without killing latency.
> A KV cache manager that doesn't OOM your GPUs.
> A model instance pool that handles traffic spikes.
And that's just the core components.
Your <50ms p99 requirement breaks down as:
- Network overhead: 10-15ms (you can't fix this)
- Queueing delay: 5-20ms (if you batch wrong, this explodes)
- First token latency: 20-40ms (model dependent)
- Per-token generation: 10-50ms (grows with context length)
You have maybe 5ms of slack. This is why "just throw H100s at it" fails.
- Network overhead: 10-15ms (you can't fix this)
- Queueing delay: 5-20ms (if you batch wrong, this explodes)
- First token latency: 20-40ms (model dependent)
- Per-token generation: 10-50ms (grows with context length)
You have maybe 5ms of slack. This is why "just throw H100s at it" fails.
btw get this kinda content in your inbox daily -
now back to the thread - fullstackagents.substack.com
now back to the thread - fullstackagents.substack.com

The first principle of inference platforms:
Continuous batching ≠ Static batching
Static batching waits for 8 requests, then processes them together. Continuous batching processes 8 requests and adds request #9 mid-generation.
vLLM does this. TensorRT-LLM does this. Your FastAPI wrapper doesn't.
This single difference is 3-5x throughput.
Continuous batching ≠ Static batching
Static batching waits for 8 requests, then processes them together. Continuous batching processes 8 requests and adds request #9 mid-generation.
vLLM does this. TensorRT-LLM does this. Your FastAPI wrapper doesn't.
This single difference is 3-5x throughput.
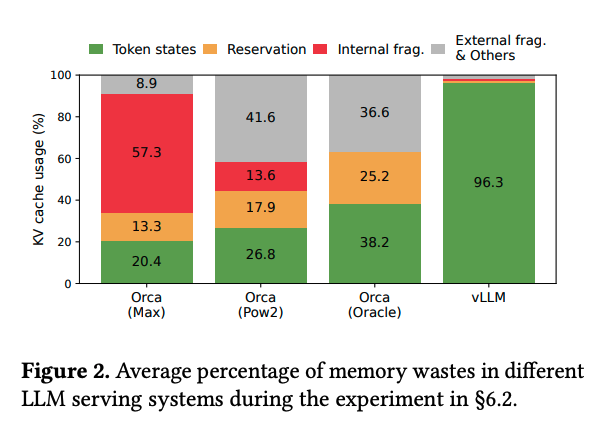
KV cache memory makes things difficult.
Llama 70B at 4K context needs 560GB of KV cache for just 32 concurrent requests. Your H100 has 80GB total.
PagedAttention (from vLLM) solved this by treating KV cache like virtual memory. Manual implementation? You'll OOM before you understand why.
Llama 70B at 4K context needs 560GB of KV cache for just 32 concurrent requests. Your H100 has 80GB total.
PagedAttention (from vLLM) solved this by treating KV cache like virtual memory. Manual implementation? You'll OOM before you understand why.
"We have 20 fine-tuned models for different tasks"
Now your platform needs model routing based on user intent.
Dynamic loading and unloading so you don't keep 20 models in memory.
Shared KV cache across similar base models.
LoRA adapter swapping in <100ms.
This is where 90% of DIY inference platforms die.
Now your platform needs model routing based on user intent.
Dynamic loading and unloading so you don't keep 20 models in memory.
Shared KV cache across similar base models.
LoRA adapter swapping in <100ms.
This is where 90% of DIY inference platforms die.
Use OpenAI API when you're under 100K requests/month, using standard models, can tolerate 500ms+ latency, and cost per request is 10x higher than raw compute.
Build your own when you have custom models, doing 500K+ requests/month, need sub-100ms p99, or when cost optimization actually matters.
The break-even is usually around $5-10K/month in API spend.
Build your own when you have custom models, doing 500K+ requests/month, need sub-100ms p99, or when cost optimization actually matters.
The break-even is usually around $5-10K/month in API spend.
Let's do the actual math:
OpenAI GPT-5 pricing: $1.25 per 1M input tokens, $10 per 1M output tokens
1M requests × 1K input tokens × 500 output tokens = $1,250 input + $5,000 output = $6,250
Your H100 inference platform at $2/hour: 1M requests at 100 req/sec = 2.8 hours = $5.60 in compute.
But you forgot engineering time ($50K to build), maintenance ($10K/month), and the 6 months to break even.
OpenAI GPT-5 pricing: $1.25 per 1M input tokens, $10 per 1M output tokens
1M requests × 1K input tokens × 500 output tokens = $1,250 input + $5,000 output = $6,250
Your H100 inference platform at $2/hour: 1M requests at 100 req/sec = 2.8 hours = $5.60 in compute.
But you forgot engineering time ($50K to build), maintenance ($10K/month), and the 6 months to break even.
Production inference platforms have four layers:
Request handling (load balancer, rate limiter, queue). Orchestration (model router, dynamic batcher, priority scheduler). Inference engine (vLLM/TRT-LLM, KV cache manager, multi-GPU coordinator). Observability (per-component latency, GPU utilization, cost per token).
Most engineers build layer 1 and 3, then wonder why production breaks.
Request handling (load balancer, rate limiter, queue). Orchestration (model router, dynamic batcher, priority scheduler). Inference engine (vLLM/TRT-LLM, KV cache manager, multi-GPU coordinator). Observability (per-component latency, GPU utilization, cost per token).
Most engineers build layer 1 and 3, then wonder why production breaks.
The mistakes that kill DIY inference platforms:
> Ignoring queueing theory. Your GPU isn't the bottleneck - your queue is. Requests pile up faster than you can batch them.
> Optimizing throughput over latency. Sure you hit 1000 tokens/sec in aggregate, but user experience is terrible because individual requests wait.
> Not measuring per-token latency. Your p99 looks fine until you realize tokens 50-100 are taking 200ms each.
> Ignoring queueing theory. Your GPU isn't the bottleneck - your queue is. Requests pile up faster than you can batch them.
> Optimizing throughput over latency. Sure you hit 1000 tokens/sec in aggregate, but user experience is terrible because individual requests wait.
> Not measuring per-token latency. Your p99 looks fine until you realize tokens 50-100 are taking 200ms each.
Here's where it gets interesting: speculative decoding, prefix caching, and continuous batching work AGAINST each other.
Speculative decoding wants more compute upfront for faster generation. Prefix caching wants more memory to reuse common contexts. Continuous batching wants shorter sequences for better throughput.
Optimize one, degrade the others. This tradeoff doesn't exist when you're just calling OpenAI's API.
Speculative decoding wants more compute upfront for faster generation. Prefix caching wants more memory to reuse common contexts. Continuous batching wants shorter sequences for better throughput.
Optimize one, degrade the others. This tradeoff doesn't exist when you're just calling OpenAI's API.
The production checklist for inference platforms:
> Use continuous batching (vLLM or TensorRT-LLM, not raw PyTorch).
> Implement request prioritization from day one.
> Monitor per-component latency, not just end-to-end.
> Auto-scale based on queue depth, not CPU.
> Track both $/token AND tokens/sec.
Have model hot-swapping ready. Plan for 10x traffic spikes.
> Use continuous batching (vLLM or TensorRT-LLM, not raw PyTorch).
> Implement request prioritization from day one.
> Monitor per-component latency, not just end-to-end.
> Auto-scale based on queue depth, not CPU.
> Track both $/token AND tokens/sec.
Have model hot-swapping ready. Plan for 10x traffic spikes.
That's it for today.
Building an inference platform is a 6-month engineering project with hidden costs everywhere.
But when you hit scale? It pays for itself in weeks.
The key is knowing when to build vs when to rent.
See ya tomorrow!
Building an inference platform is a 6-month engineering project with hidden costs everywhere.
But when you hit scale? It pays for itself in weeks.
The key is knowing when to build vs when to rent.
See ya tomorrow!
• • •
Missing some Tweet in this thread? You can try to
force a refresh