You're in a ML Engineering Interview at Meta, and the interviewer asks:
"Why use LoRA for fine-tuning? Can't we just update all the weights?"
Here's how you answer:
Don't say: "To save memory." The answer is too shallow.
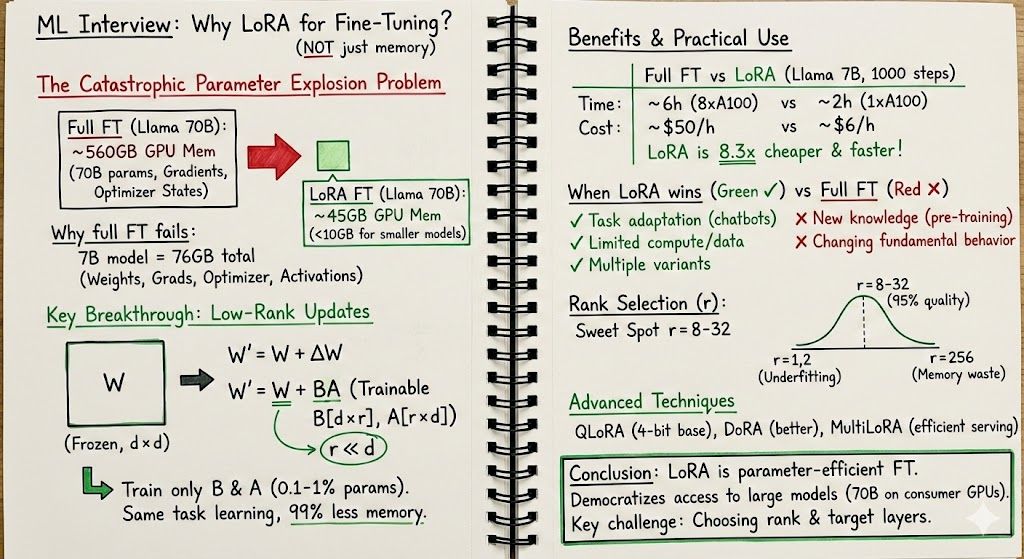
The real answer is the catastrophic parameter explosion problem.
Fine-tuning Llama 70B requires updating 70 BILLION parameters. That's 280GB just for gradients + 280GB for optimizer states.
You need 560GB+ GPU memory for full fine-tuning. LoRA does it with <10GB.
Nov 3, 2025 • 16 tweets • 4 min read
"Just use OpenAI API"
Until you need:
- Custom fine-tuned models
- <50ms p99 latency
- $0.001/1K tokens (not $1.25/1K input)
Then you build your own inference platform.
Here's how to do that:
Most engineers think "build your own" means:
- Rent some GPUs
- Load model with vLLM
- Wrap it in FastAPI
- Ship it
The complexity hits you around week 2.
Oct 4, 2025 • 13 tweets • 3 min read
You're in a Machine Learning Interview at Perplexity, and the interviewer asks:
"Why do we need rerankers in RAG? Isn't semantic search enough?"
Here's how you answer:
Don't say: "To get better results" or "To improve accuracy."
Too vague.
The real answer is the two-tower bottleneck.
Your embedding model creates separate vectors for query and document.
No interaction = no understanding of relevance.
You're ranking without reading.
Sep 29, 2025 • 11 tweets • 2 min read
You’re in a AI Engineer interview at Microsoft, and the interviewer asks:
‘Our team needs to build RAG over 10M documents. Which vector database and why?’
Here’s how you answer:
Don’t say: ‘Pinecone scales best’ or ‘Chroma is easiest.’
Wrong framing.
The real answer isn’t about features - it’s about matching DB architecture to your query patterns.
Read-heavy prototype vs. write-heavy production vs. hybrid search = completely different databases.
Sep 24, 2025 • 11 tweets • 2 min read
You're in a ML Inference Engineer interview at Google, and the interviewer asks:
"Our team wants to switch from Gemini API to a fine tuned. Which serving framework and why?"
Here's how you answer:
Don't say: "vLLM is fastest" or "Ollama is easiest."
Wrong framing.
The real answer isn't about features - it's about matching serving philosophy to your constraints.
Local prototype vs. production scale vs. complex workflows = completely different frameworks.
Sep 18, 2025 • 16 tweets • 3 min read
You're in a ML Engineer interview at Perplexity, and the interviewer asks:
"Your RAG system is hallucinating in production. How do you diagnose what's broken - the retriever or the generator?"
Here's how you can answer:
Most candidates say "check accuracy" or "run more tests."
Wrong approach.
RAG systems fail at TWO distinct stages, and you need different metrics for each.
Generic accuracy won't tell you WHERE the problem is.
Sep 17, 2025 • 13 tweets • 3 min read
You're in a ML Engineer interview at Groq, and the interviewer asks:
"How do you measure LLM inference performance? What metrics matter most for production systems?"
Here's how you can answer
Most candidates fumble here because they only know "tokens per second" or TPS.
Incomplete answer.
There are 4 critical metrics every ML engineer should understand cold.
Sep 16, 2025 • 13 tweets • 4 min read
You're in a ML Inference engineer interview at Google, and the interviewer asks:
"What's the real bottleneck in LLM serving throughput? How can PagedAttention help?"
Here's how you can answer:
Traditional LLM serving hits a memory wall fast. The problem isn't compute - it's how we manage the KV cache.
65% model weights
30% KV cache
5% activations.
When KV cache is managed poorly, you're wasting 60-80% of your GPU memory.
Sep 15, 2025 • 12 tweets • 3 min read
You're in a Research engineer interview at OpenAI, and the interviewer asks:
"How do you train your model for Computer Use? Can RL solve this? "
Here's how you can answer:
Traditional LLM training hits a wall with computer use tasks.
You can't just feed it more text and expect it to:
- Navigate complex UIs
- Handle multi-step workflows
- Recover from errors gracefully
- Adapt to new software
Sep 11, 2025 • 9 tweets • 3 min read
You're in an ML inference engineer interview at Anthropic, and the interviewer asks:
"Can you explain speculative decoding and why we'd want to use it?"
Here's how you can answer:
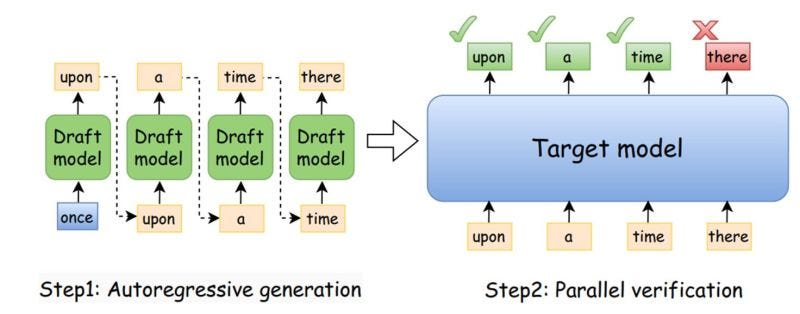
The Core Concept -
Speculative decoding is an inference optimization that speeds up autoregressive generation without sacrificing quality.
It uses two models working together – a small, fast 'draft model' that proposes multiple tokens ahead, and our main 'target model' that verifies these proposals in parallel.