Everyone’s talking about AI agents and almost no one knows how to build one that actually works.
So here's the guide that you can use to build agents that work ↓
(Comment "Agent" and I'll DM you mega prompt to automate agent building using LLMs)
So here's the guide that you can use to build agents that work ↓
(Comment "Agent" and I'll DM you mega prompt to automate agent building using LLMs)

First: most "AI agents" are just glorified chatbots.
You don't need 20 papers or a PhD.
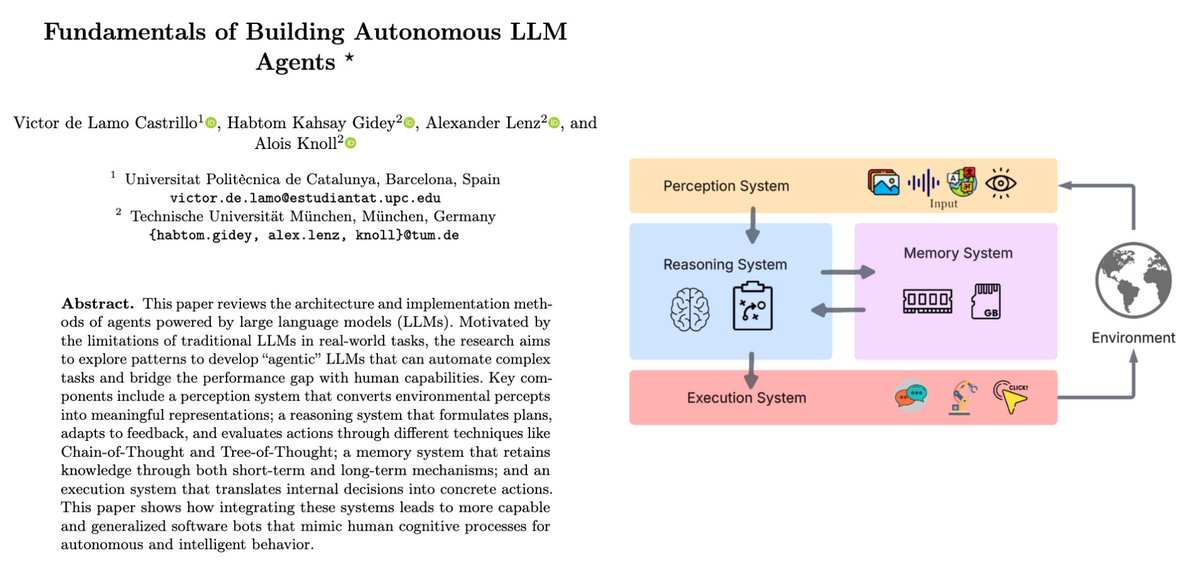
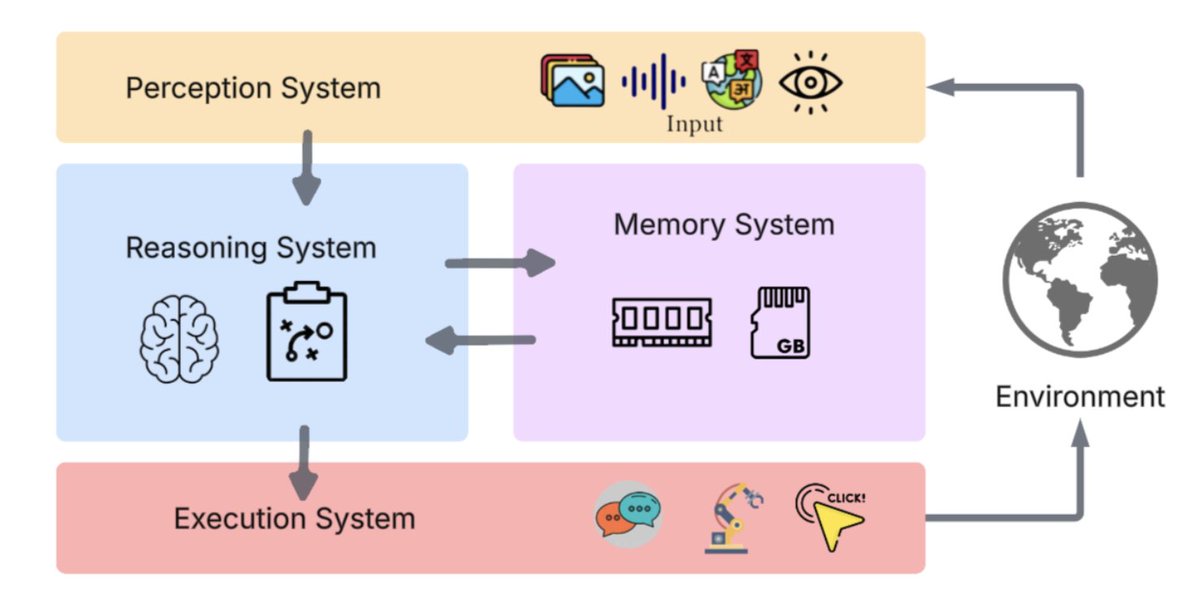
You need 4 things:
→ Memory
→ Tools
→ Autonomy
→ A reason to exist
Let’s break it down like you're building a startup MVP:
You don't need 20 papers or a PhD.
You need 4 things:
→ Memory
→ Tools
→ Autonomy
→ A reason to exist
Let’s break it down like you're building a startup MVP:
Step 1 - Start stupid simple.
Your stack:
✅ Python
✅ LangChain or CrewAI
✅ OpenAI API (GPT-4 Turbo)
✅ Pinecone or ChromaDB (for memory)
✅ Browser tools or API wrappers
That’s enough to build a basic functional agent in hours, not weeks.
Step 2 - Give your agent a real job.
Don't build an agent that "can do anything."
Give it one job:
→ Book meetings
→ Summarize emails
→ Scrape LinkedIn
→ Manage your Notion
→ Answer FAQs
Small scope = actual success.
Step 3 - Autonomy ≠ Magic.
Everyone thinks agents should self-loop forever.
That’s why they crash and hallucinate.
Fix it with:
→ Guardrails
→ Task manager loops (like CrewAI or AutoGen)
→ Human-in-the-loop checkpoints
Autonomy needs rules. Not just vibes.
Step 4 - Memory is not a vector DB.
Founders confuse “storing text” with “having memory.”
You want:
→ Short-term memory (conversation context)
→ Long-term memory (retrievable knowledge)
→ Episodic memory (what it did before)
Most agents don’t have this = they forget everything.
Step 5 - Tools are what make it smart.
No tools = useless agent.
Tool it up with:
→ Web browsing
→ Python eval
→ Zapier for APIs
→ Custom plugins for your stack (Stripe, Airtable, Slack, etc)
The agent doesn’t need to “think” it needs to act.
Step 6 - UI is half the product.
Don’t ship a CLI. Nobody cares.
Wrap your agent in:
→ Streamlit (fast MVP)
→ Next.js + React
→ ChatGPT Plugin UI
→ WhatsApp/Slack bot
Build like a product, not a demo.
Your stack:
✅ Python
✅ LangChain or CrewAI
✅ OpenAI API (GPT-4 Turbo)
✅ Pinecone or ChromaDB (for memory)
✅ Browser tools or API wrappers
That’s enough to build a basic functional agent in hours, not weeks.
Step 2 - Give your agent a real job.
Don't build an agent that "can do anything."
Give it one job:
→ Book meetings
→ Summarize emails
→ Scrape LinkedIn
→ Manage your Notion
→ Answer FAQs
Small scope = actual success.
Step 3 - Autonomy ≠ Magic.
Everyone thinks agents should self-loop forever.
That’s why they crash and hallucinate.
Fix it with:
→ Guardrails
→ Task manager loops (like CrewAI or AutoGen)
→ Human-in-the-loop checkpoints
Autonomy needs rules. Not just vibes.
Step 4 - Memory is not a vector DB.
Founders confuse “storing text” with “having memory.”
You want:
→ Short-term memory (conversation context)
→ Long-term memory (retrievable knowledge)
→ Episodic memory (what it did before)
Most agents don’t have this = they forget everything.
Step 5 - Tools are what make it smart.
No tools = useless agent.
Tool it up with:
→ Web browsing
→ Python eval
→ Zapier for APIs
→ Custom plugins for your stack (Stripe, Airtable, Slack, etc)
The agent doesn’t need to “think” it needs to act.
Step 6 - UI is half the product.
Don’t ship a CLI. Nobody cares.
Wrap your agent in:
→ Streamlit (fast MVP)
→ Next.js + React
→ ChatGPT Plugin UI
→ WhatsApp/Slack bot
Build like a product, not a demo.
What breaks most agents?
→ No error handling
→ No task boundaries
→ Bad prompt hygiene
→ Trying to do too much
→ Running in infinite loops
→ Forgetting the damn API keys
Your agent isn’t dumb. You’re just lazy. Fix your plumbing.
→ No error handling
→ No task boundaries
→ Bad prompt hygiene
→ Trying to do too much
→ Running in infinite loops
→ Forgetting the damn API keys
Your agent isn’t dumb. You’re just lazy. Fix your plumbing.
Want shortcuts? Steal these.
→ Use Superagent
if you hate infra
→ Use LangGraph
for smart flows
→ Use CrewAI
to orchestrate roles
→ Use ReAct pattern
for tool use
→ Use GPT-4 Turbo with function calling - it just works
→ Use Superagent
if you hate infra
→ Use LangGraph
for smart flows
→ Use CrewAI
to orchestrate roles
→ Use ReAct pattern
for tool use
→ Use GPT-4 Turbo with function calling - it just works
Want examples? Build these:
• An AI SDR that scrapes leads + sends intros
• A content repurposer that posts on X + LinkedIn
• A Notion bot that updates your docs from meetings
• A customer support bot that handles 80% of tickets
• A market research bot that autogenerates reports
All agent-ready. All monetizable.
12. Stop waiting for GPT-5.
99% of people saying “agents are early” haven’t built one.
You can build a useful AI agent today - if you don’t try to build Jarvis.
Start small.
Ship fast.
Make it useful.
Then stack automation on top.
• An AI SDR that scrapes leads + sends intros
• A content repurposer that posts on X + LinkedIn
• A Notion bot that updates your docs from meetings
• A customer support bot that handles 80% of tickets
• A market research bot that autogenerates reports
All agent-ready. All monetizable.
12. Stop waiting for GPT-5.
99% of people saying “agents are early” haven’t built one.
You can build a useful AI agent today - if you don’t try to build Jarvis.
Start small.
Ship fast.
Make it useful.
Then stack automation on top.
Building a solid AI agent is like building a startup MVP:
→ Solve a small problem
→ Use off-the-shelf tools
→ Keep it scoped
→ Iterate fast
→ Make it usable
→ Don’t be fancy
And most importantly:
Build something useful, not impressive.
→ Solve a small problem
→ Use off-the-shelf tools
→ Keep it scoped
→ Iterate fast
→ Make it usable
→ Don’t be fancy
And most importantly:
Build something useful, not impressive.
Save this thread. Share it with your cofounder.
And if you're actually building an agent in public - reply and drop a link.
I want to see the ones that work.
And if you're actually building an agent in public - reply and drop a link.
I want to see the ones that work.
• • •
Missing some Tweet in this thread? You can try to
force a refresh