The economics of AI has been a big question mark in many investors' minds - What does the value chain look like? How do you model out the ROIC of AI? What would the ROIC look like?
We built up an end-to-end economics stack to answer this question - how we go from a chip’s silicon cost, through full system integration, all the way down to the dollar cost per million inference tokens.(1/4)🧵
We built up an end-to-end economics stack to answer this question - how we go from a chip’s silicon cost, through full system integration, all the way down to the dollar cost per million inference tokens.(1/4)🧵
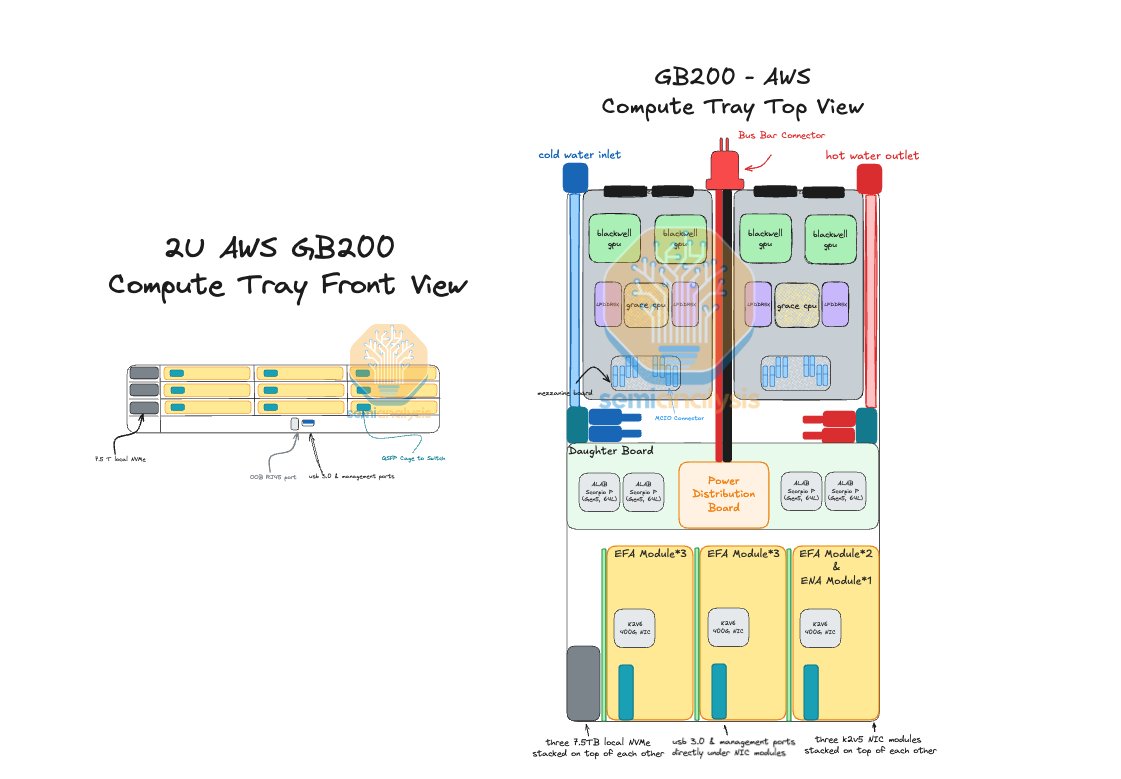
At the top of the stack, our accelerator analysis starts with the semiconductor bill of materials (transistors, packaging, HBM, and yield assumptions) to determine GPU provider content. From there, our BoM and ODM modeling breaks down every component inside the server. The network topology model then maps how these servers interconnect.(2/4)

When you roll this all up, illustratively for H200s, that gives us a capital cost of roughly $1.06 per GPU-hour, to which we add electricity and colocation costs for a complete TCO of $1.41 per GPU-hour. That’s the economic foundation. The cost to own and operate the hardware. A neocloud might rent that same GPU for roughly $2 per hour, leaving a modest gross margin. But until now, that’s where most analysis stopped at TCO/hr.(3/4)

The missing piece was InferenceMAX™, which gives us rigorous, real-world throughput data. Using DeepSeek R1 FP8 runs on H200s, we can now translate cost per GPU-hour into cost per million tokens, about $0.53 per million tokens.
Finally, once we couple that compute cost with real application metrics (average tokens per user, token price, and active user counts) we can close the loop from silicon economics all the way to application-layer profitability. In this example, we land at roughly 34% gross margin at the app level. This framework lets us, for the first time, connect token demand forecasts to megawatt requirements. As models evolve and inference efficiency improves, these relationships will keep shifting - but this stack gives us a repeatable way to translate demand into hardware, power, and ultimately, answer the question on economics.(4/4)
Finally, once we couple that compute cost with real application metrics (average tokens per user, token price, and active user counts) we can close the loop from silicon economics all the way to application-layer profitability. In this example, we land at roughly 34% gross margin at the app level. This framework lets us, for the first time, connect token demand forecasts to megawatt requirements. As models evolve and inference efficiency improves, these relationships will keep shifting - but this stack gives us a repeatable way to translate demand into hardware, power, and ultimately, answer the question on economics.(4/4)
• • •
Missing some Tweet in this thread? You can try to
force a refresh