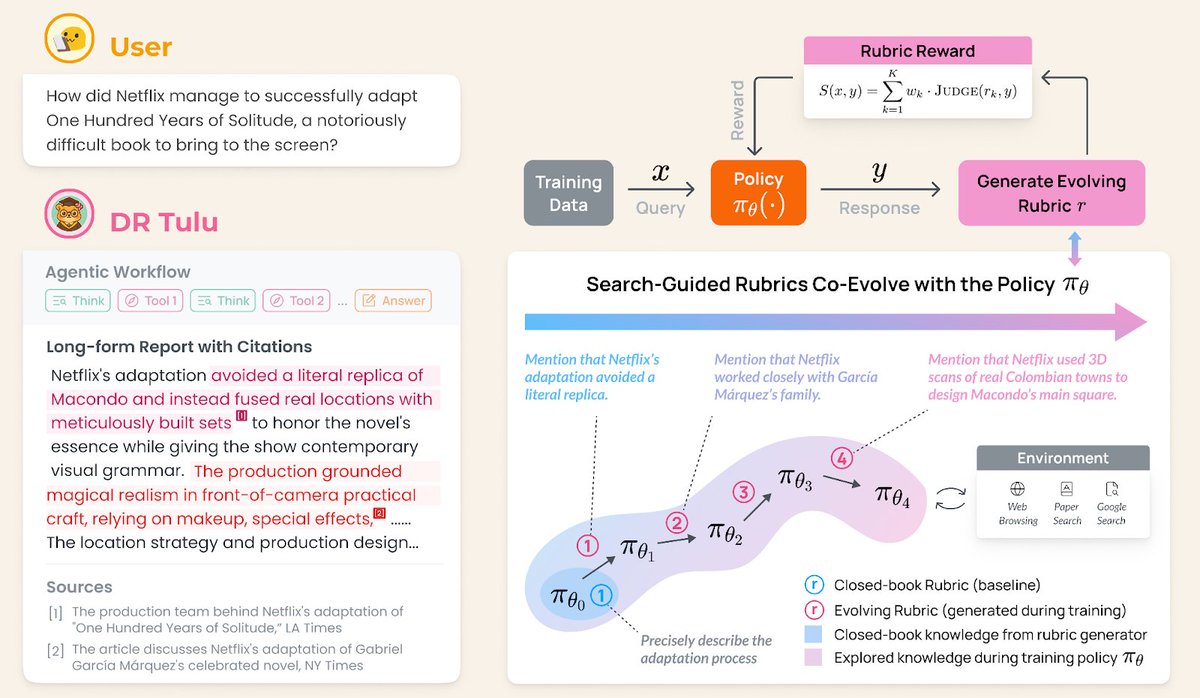
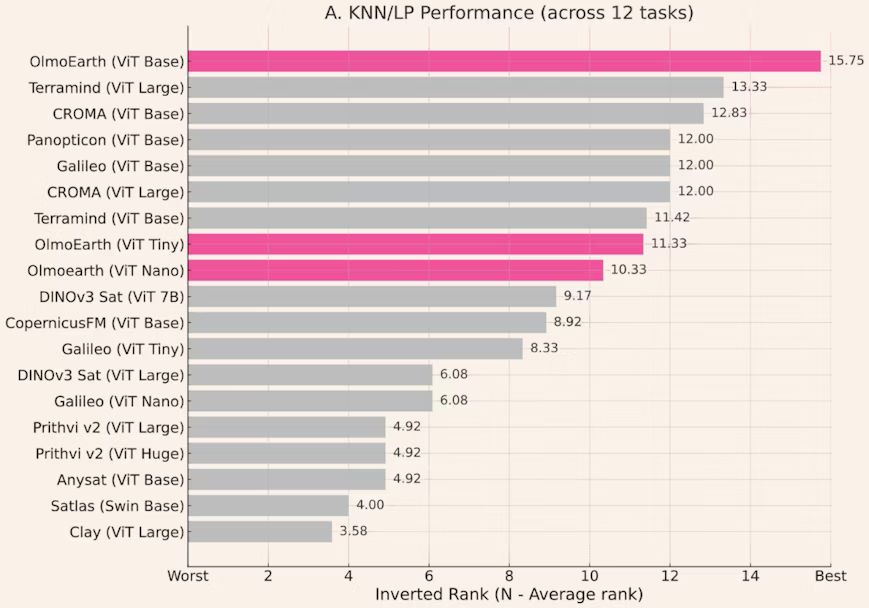
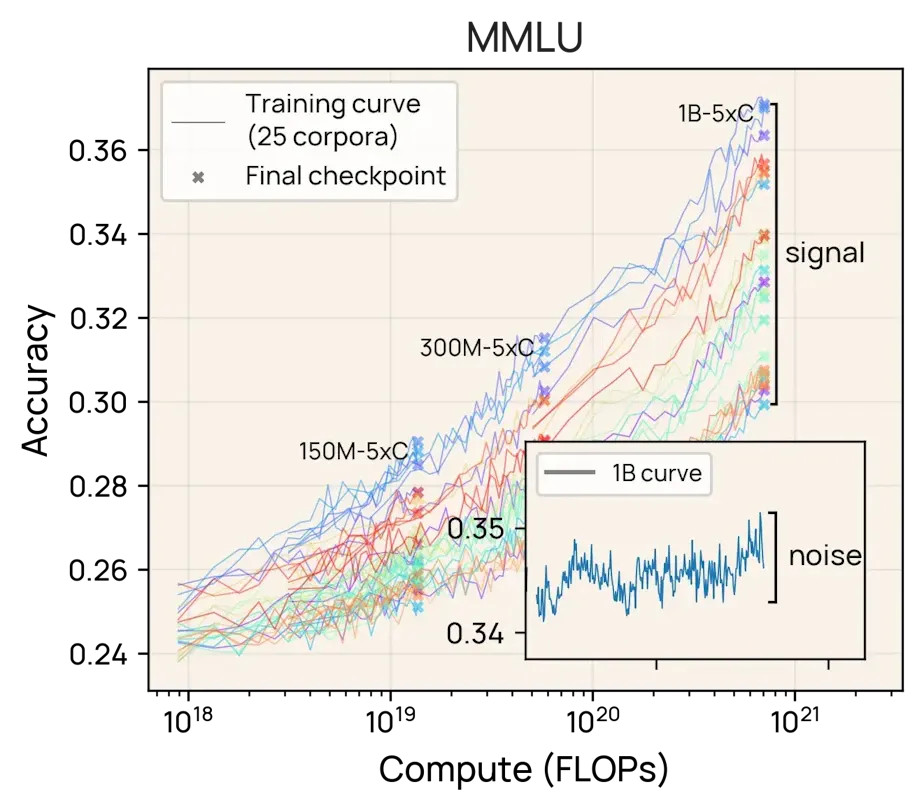
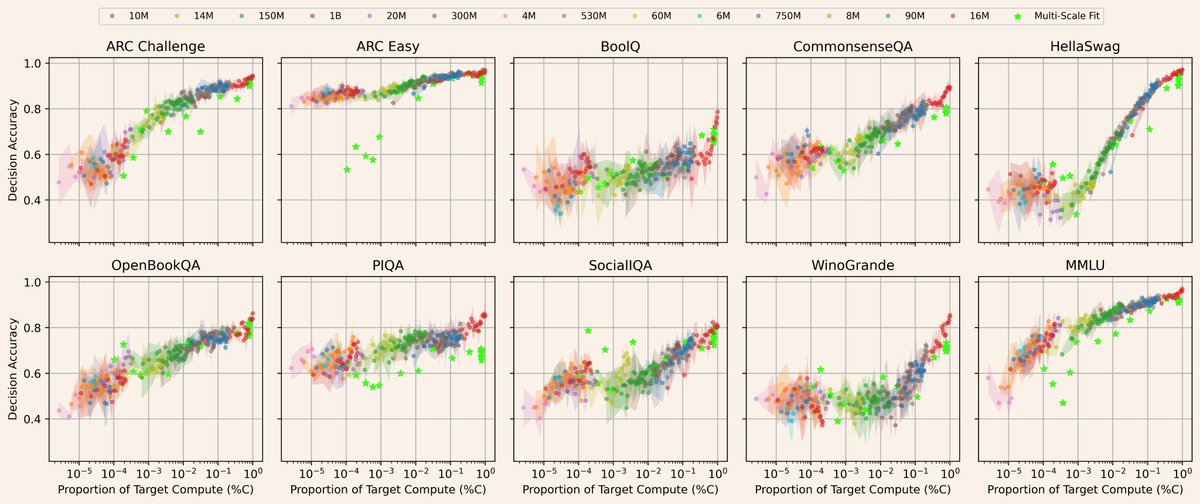
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵
Best fully open 32B reasoning model & best 32B base model. 🧵

Most models ship as a single opaque snapshot. Olmo 3 opens the model flow – pretraining, mid-training, & post-training – plus data recipes & code so you can see how capabilities are built + customize any stage.
Meet the Olmo 3 family:
🏗️ Olmo 3-Base (7B, 32B)—foundations for post-training with strong code, math, & reading comprehension skills
🛠️ Olmo 3-Instruct (7B)—multi-turn chat + tool use
🧠 Olmo 3-Think (7B, 32B)—“thinking” models that show their reasoning
All designed to run on hardware from laptops to research clusters.
🏗️ Olmo 3-Base (7B, 32B)—foundations for post-training with strong code, math, & reading comprehension skills
🛠️ Olmo 3-Instruct (7B)—multi-turn chat + tool use
🧠 Olmo 3-Think (7B, 32B)—“thinking” models that show their reasoning
All designed to run on hardware from laptops to research clusters.
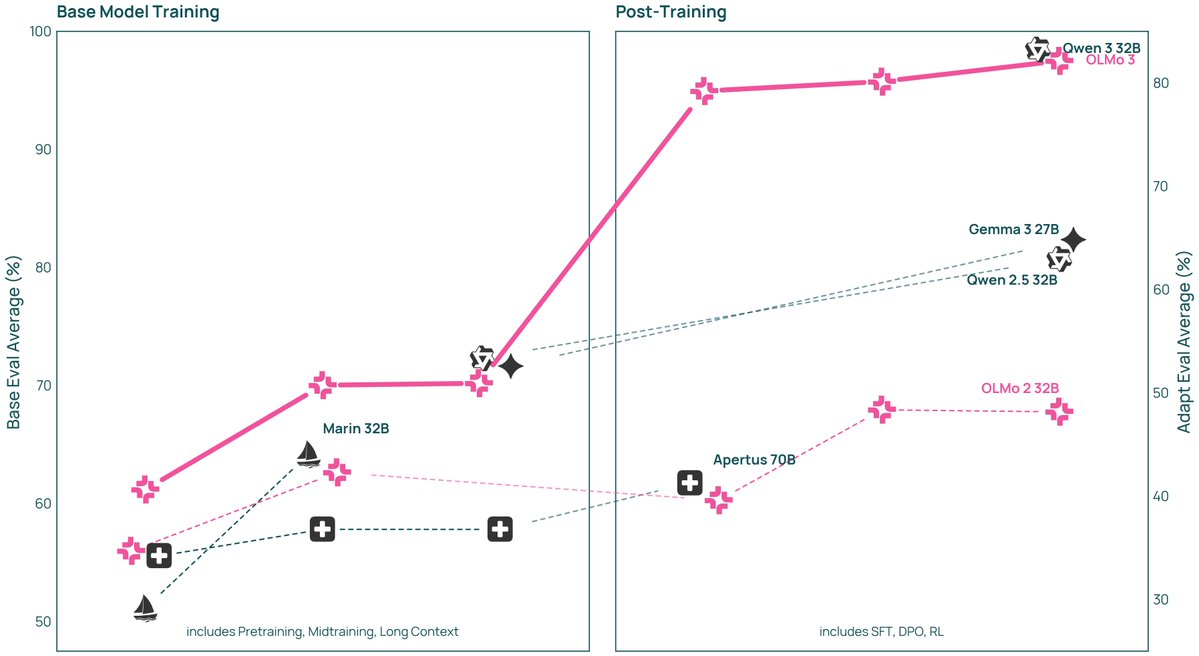
At the center is Olmo 3-Think (32B)—a fully open 32B-scale reasoning model. We see 32B as a sweet spot: a large jump in reasoning over 7B, but still small enough for many users to fine-tune and study. 💡
We trained Olmo 3 on ~6T tokens from our new Dolma 3 pretraining dataset + new post-training sets featuring stronger data decontamination and richer math/code/reasoning mixes.
A long-context extension pushes Olmo 3’s context window to ~65K tokens (~48K words)—enough for full papers, books, & other long files.
A long-context extension pushes Olmo 3’s context window to ~65K tokens (~48K words)—enough for full papers, books, & other long files.
Olmo 3 packs a punch. In our evals:
⦿ Olmo 3-Think (32B) is the strongest fully open 32B reasoner
⦿ Olmo 3-Base models beat fully open Marin & Apertus, rival Qwen 2.5 & Gemma 3
⦿ Olmo 3-Instruct (7B) ties or bests Qwen 2.5, Gemma 3 & Llama 3.1 on tough benchmarks
⦿ Olmo 3-Think (32B) is the strongest fully open 32B reasoner
⦿ Olmo 3-Base models beat fully open Marin & Apertus, rival Qwen 2.5 & Gemma 3
⦿ Olmo 3-Instruct (7B) ties or bests Qwen 2.5, Gemma 3 & Llama 3.1 on tough benchmarks
Rolling out alongside Olmo 3: a big Ai2 Playground upgrade ↴
🤔 Thinking mode—see intermediate reasoning on complex tasks
🧰 Tool calling—define JSON-schema tools or call tools in our Asta platform
🤔 Thinking mode—see intermediate reasoning on complex tasks
🧰 Tool calling—define JSON-schema tools or call tools in our Asta platform
Olmo 3 is wired into OlmoTrace in the Ai2 Playground, so you don’t just see its behavior—you can trace it.
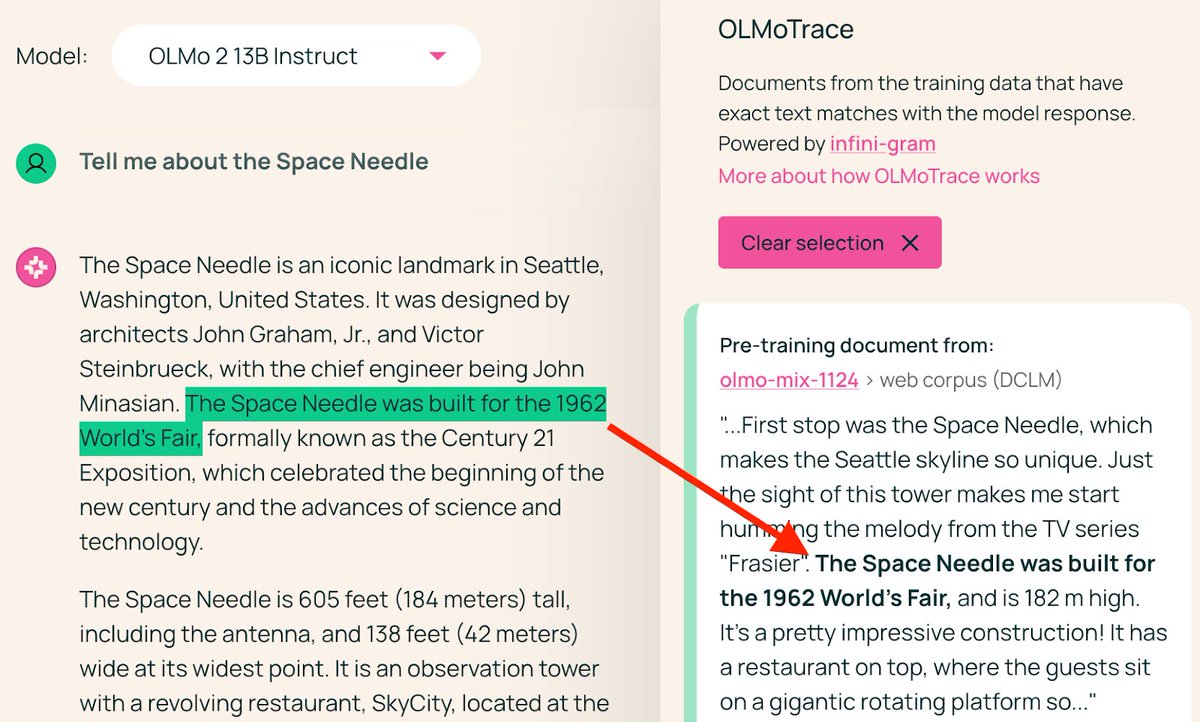
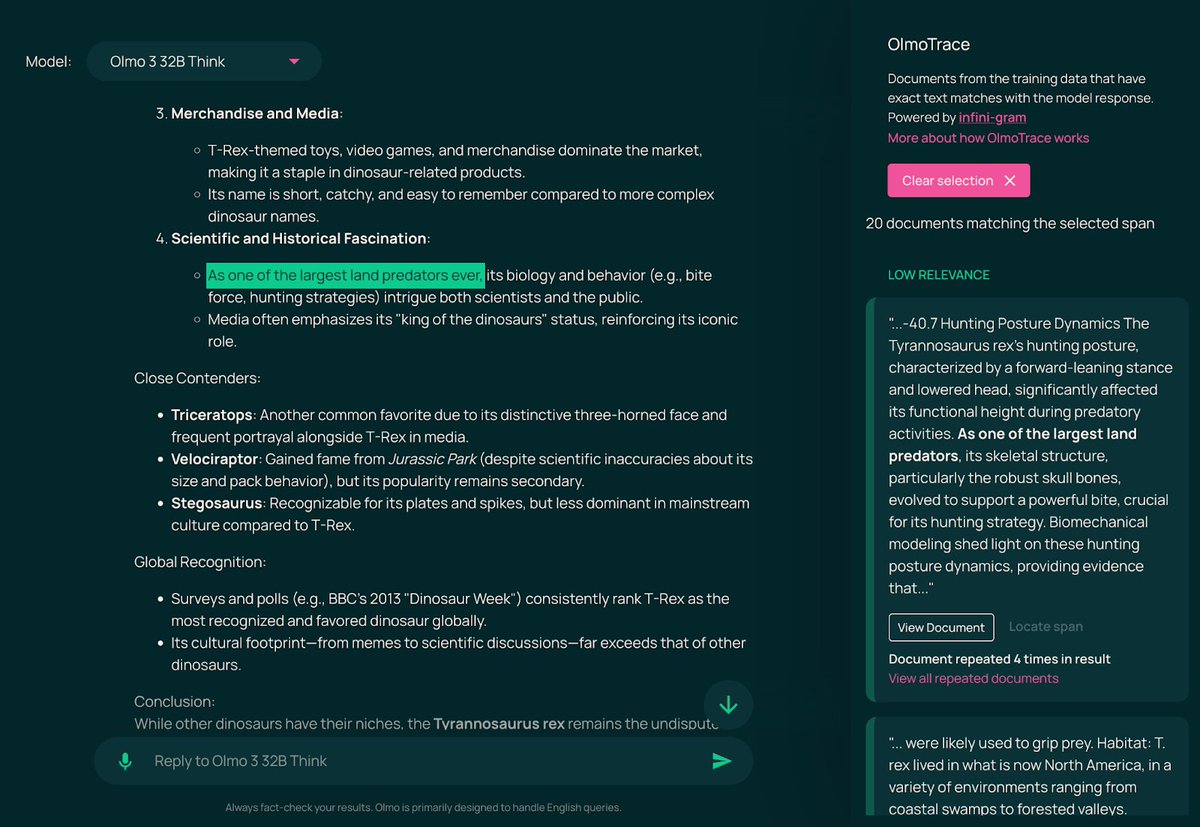
For example, you can ask Olmo 3-Think (32B) to answer a general-knowledge question, then use OlmoTrace to inspect where and how the model may have learned to generate parts of its response. 🧑🎓
For example, you can ask Olmo 3-Think (32B) to answer a general-knowledge question, then use OlmoTrace to inspect where and how the model may have learned to generate parts of its response. 🧑🎓
If you care about AI that you can customize & improve, Olmo 3 is for you—available now under Apache 2.0.
Dive deep with Olmo leads Hanna Hajishirzi and Noah Smith about how & why we built Olmo 3, and what comes next.
Dive deep with Olmo leads Hanna Hajishirzi and Noah Smith about how & why we built Olmo 3, and what comes next.
✨ Try Olmo 3 in the Ai2 Playground → playground.allenai.org/?utm_source=x&… & our Discord → discord.gg/ai2
💻 Download: huggingface.co/collections/al…
📝 Blog: allenai.org/blog/olmo3?utm…
📚 Technical report: allenai.org/papers/olmo3?u…
💻 Download: huggingface.co/collections/al…
📝 Blog: allenai.org/blog/olmo3?utm…
📚 Technical report: allenai.org/papers/olmo3?u…
• • •
Missing some Tweet in this thread? You can try to
force a refresh