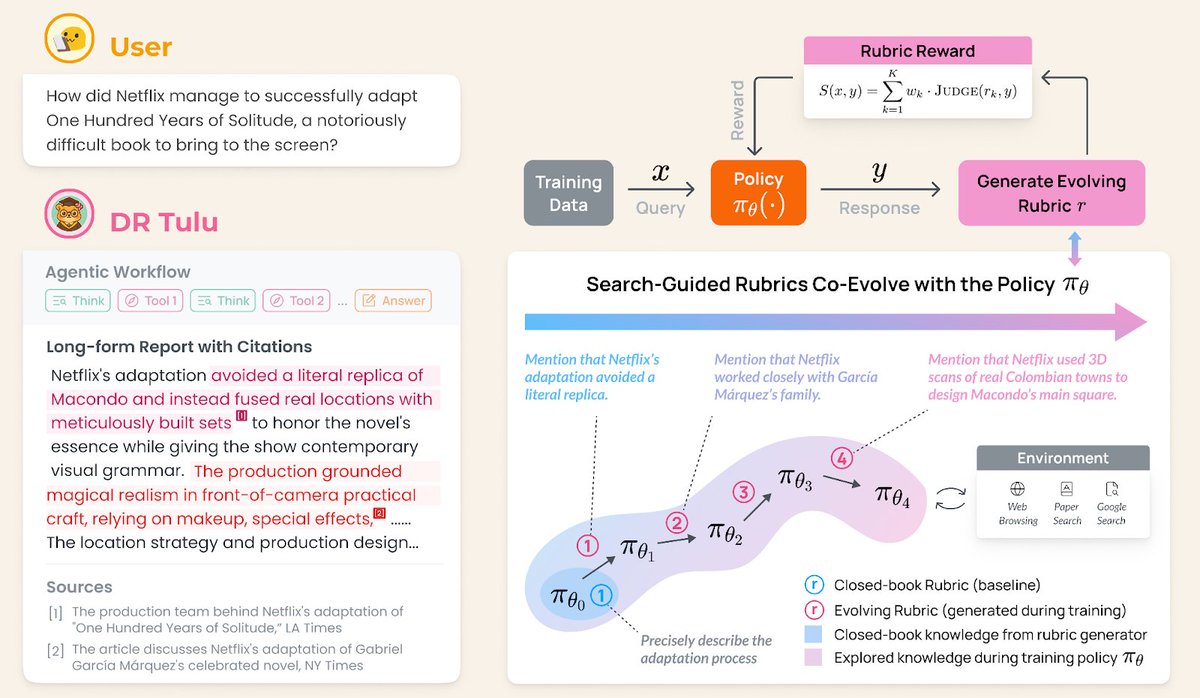
 Most models ship as a single opaque snapshot. Olmo 3 opens the model flow – pretraining, mid-training, & post-training – plus data recipes & code so you can see how capabilities are built + customize any stage.
Most models ship as a single opaque snapshot. Olmo 3 opens the model flow – pretraining, mid-training, & post-training – plus data recipes & code so you can see how capabilities are built + customize any stage.
 🧪 After analyzing 30 benchmarks & 465 open-weight models, the verdict is clear: a simple metric, signal-to-noise ratio (SNR), can reveal which benchmarks are actually informative for making decisions between two models.
🧪 After analyzing 30 benchmarks & 465 open-weight models, the verdict is clear: a simple metric, signal-to-noise ratio (SNR), can reveal which benchmarks are actually informative for making decisions between two models.
 🔮DataDecide measures how accurately small experiments (1B parameters, 100B tokens, 3 seeds) predict the real ranking of large runs. This helps us make the most cost-effective decisions for our training runs. 💸
🔮DataDecide measures how accurately small experiments (1B parameters, 100B tokens, 3 seeds) predict the real ranking of large runs. This helps us make the most cost-effective decisions for our training runs. 💸

 Paper Finder breaks down your query into relevant components, such as searching for papers, following citations, evaluating for relevance, and running follow-up queries based on the results. It then presents not only the papers, but also short summaries of why the paper is relevant to your specific query.
Paper Finder breaks down your query into relevant components, such as searching for papers, following citations, evaluating for relevance, and running follow-up queries based on the results. It then presents not only the papers, but also short summaries of why the paper is relevant to your specific query.
 Benchmarking Tülu 3. Interesting finding: Reinforcement Learning from Verifiable Rewards (RLVR) framework improved the MATH performance more significantly at a larger scale, i.e. 405B compared to 70B and 8B, similar to the findings in the DeepSeek-R1 report.
Benchmarking Tülu 3. Interesting finding: Reinforcement Learning from Verifiable Rewards (RLVR) framework improved the MATH performance more significantly at a larger scale, i.e. 405B compared to 70B and 8B, similar to the findings in the DeepSeek-R1 report.
 8B model: huggingface.co/allenai/Llama-…
8B model: huggingface.co/allenai/Llama-…
