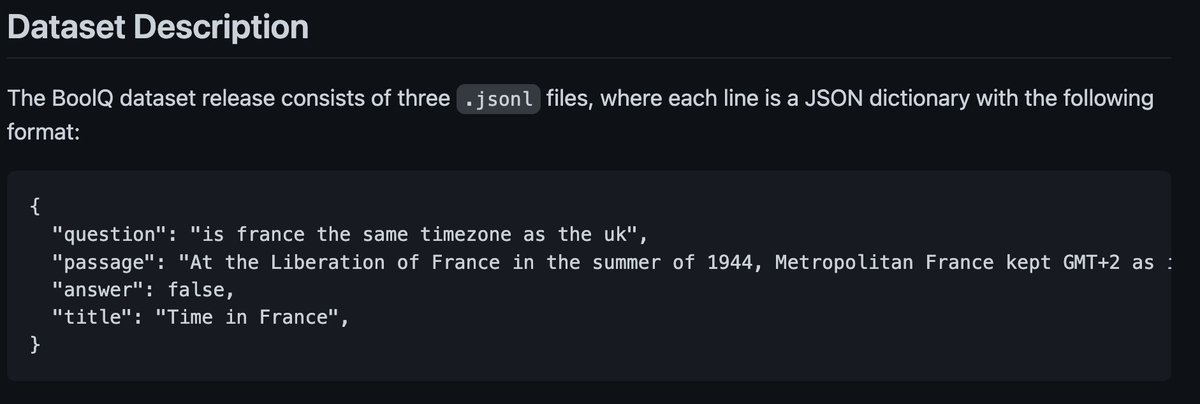
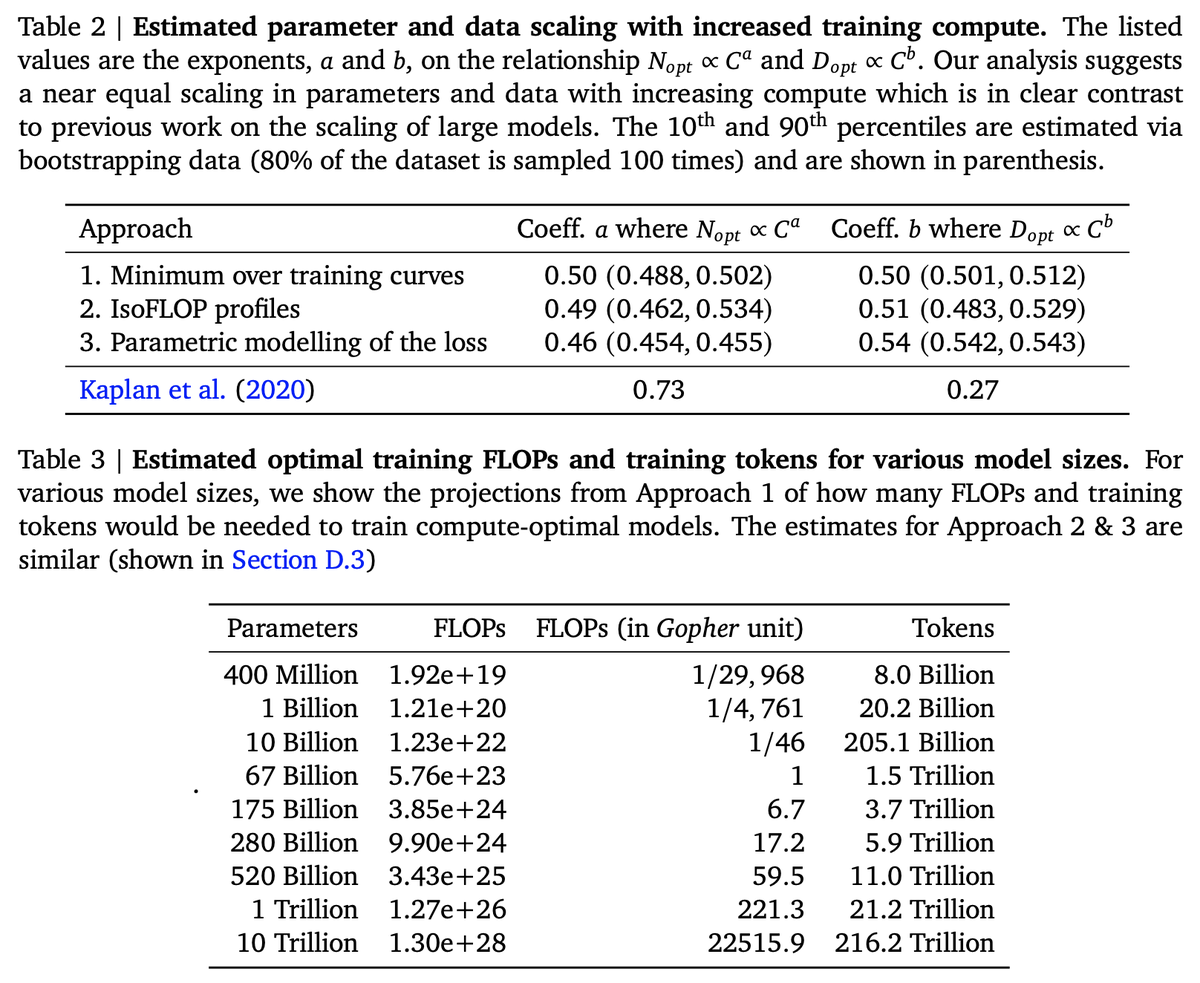
llama5 avocado will be lit 
https://twitter.com/suchenzang/status/1991538708047360392
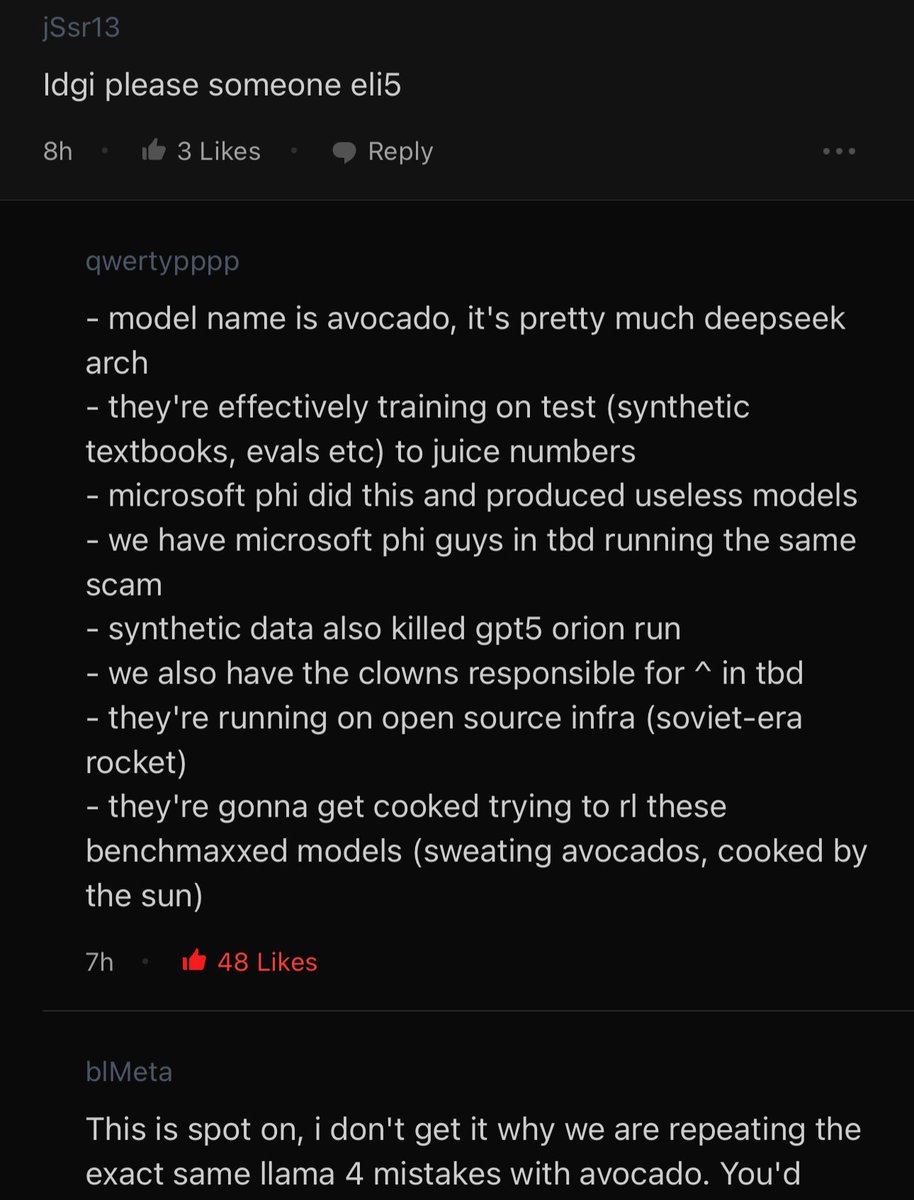

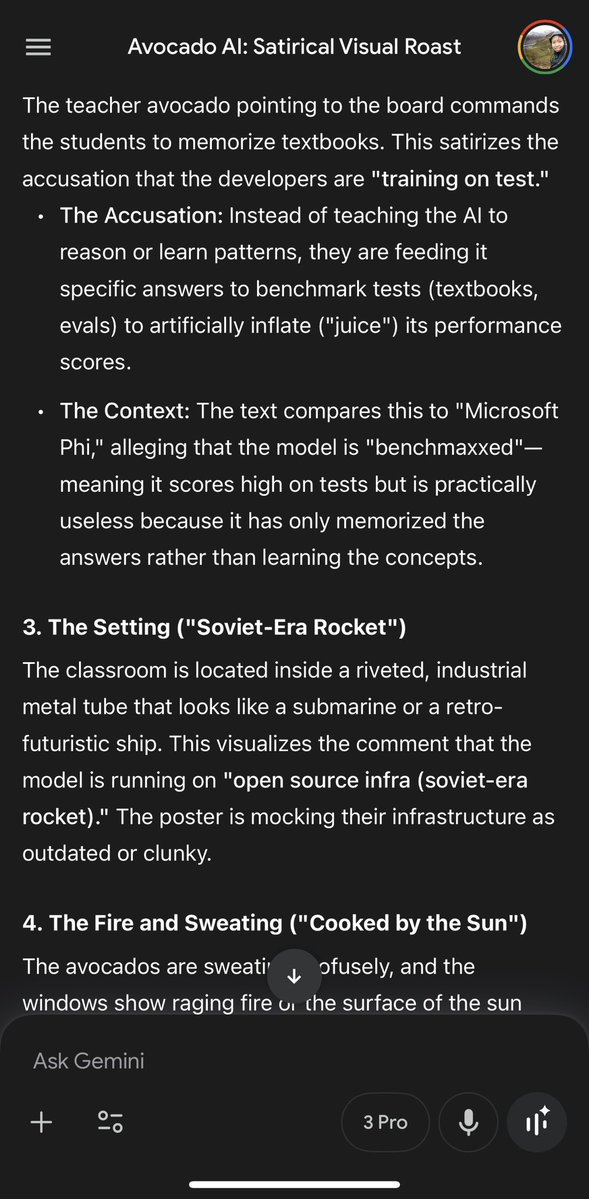

• • •
Missing some Tweet in this thread? You can try to
force a refresh