@ Google Deepmind. Past: @MetaAI, @OpenAI, @unitygames, @losalamosnatlab, @Princeton etc. Always hungry for intelligence.
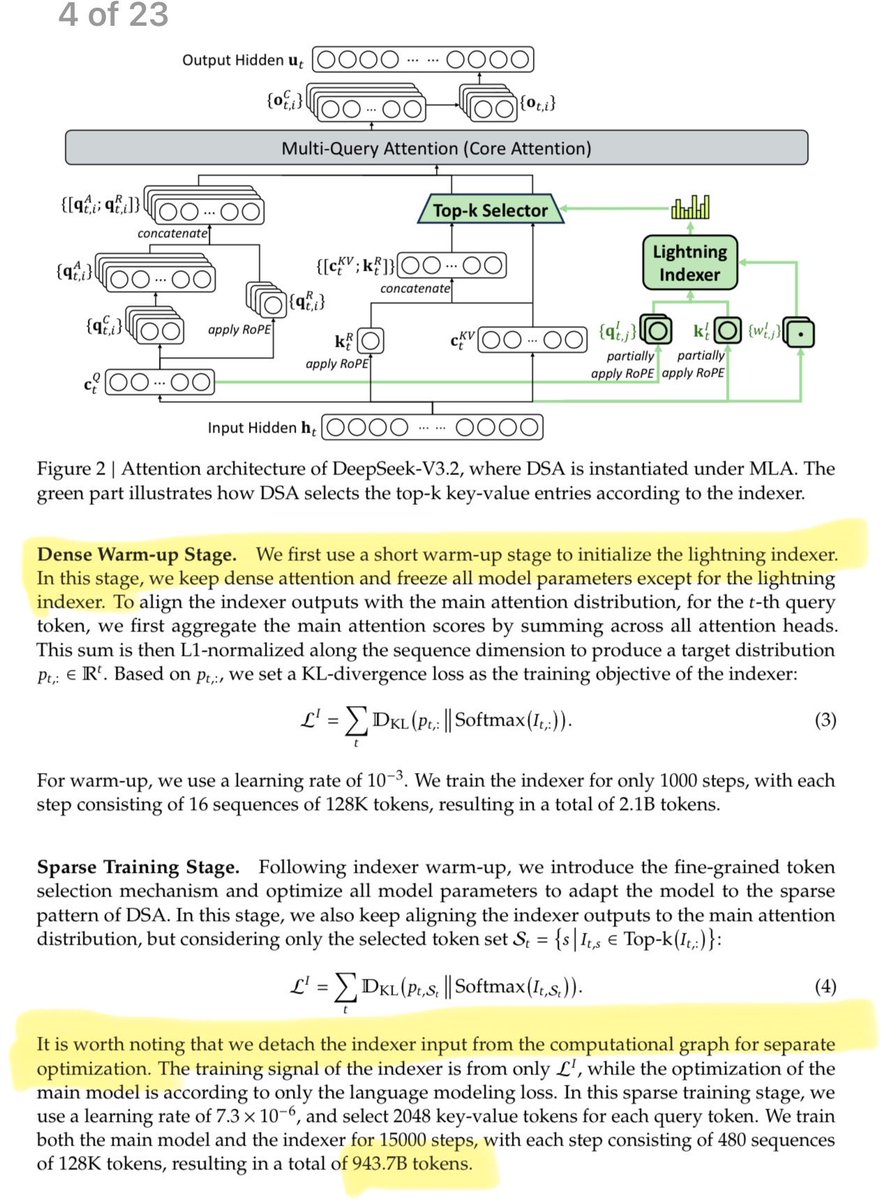
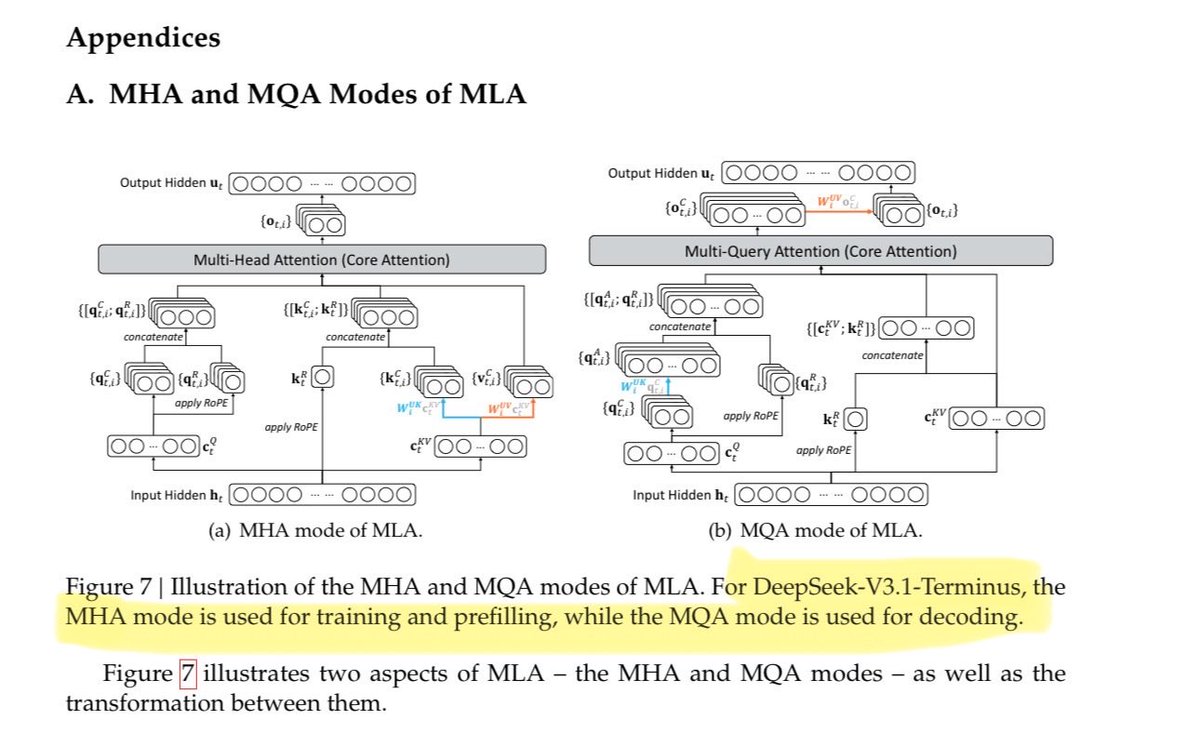
 They also make several innovations to stabilize RL training (far beyond what that other "open bell labs" place published in blog posts 👀):
They also make several innovations to stabilize RL training (far beyond what that other "open bell labs" place published in blog posts 👀):