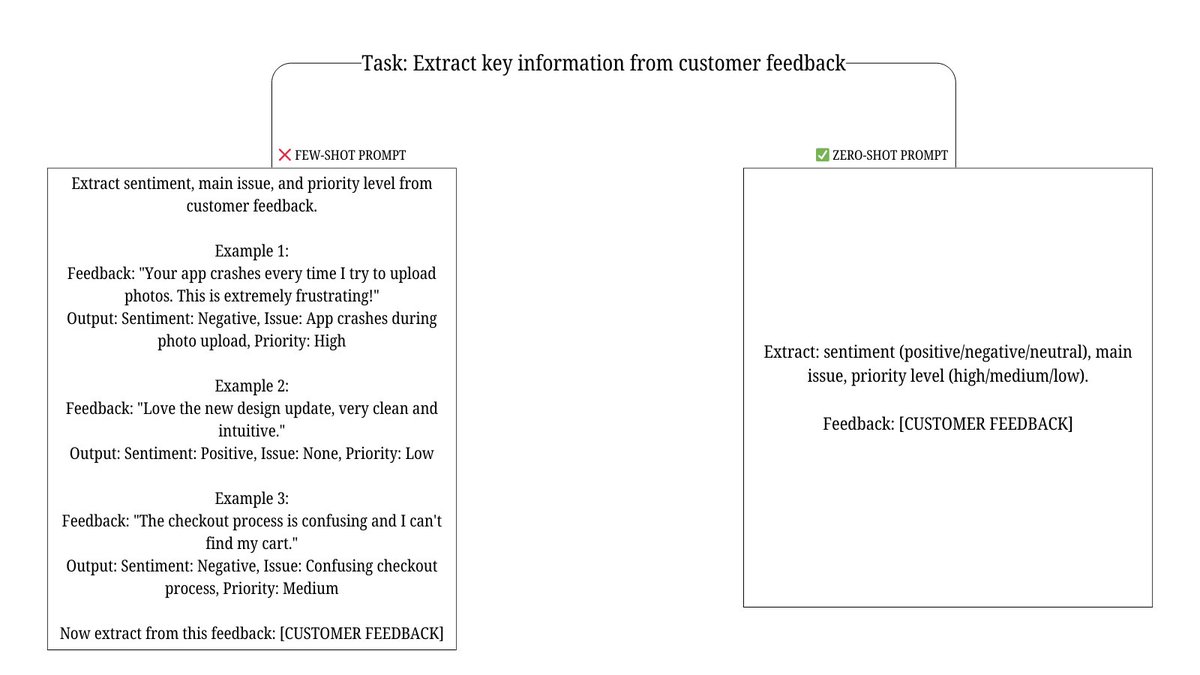
This is wild.
Gemini 3.0 Pro basically turned into a full-stack equity researcher overnight.
• Earnings deconstruction
• Balance sheet sanity check
• Market comps
• Trend analysis
• Price triggers
Copy/paste this mega prompt and watch it work:
Gemini 3.0 Pro basically turned into a full-stack equity researcher overnight.
• Earnings deconstruction
• Balance sheet sanity check
• Market comps
• Trend analysis
• Price triggers
Copy/paste this mega prompt and watch it work:
The mega prompt:
Just copy + paste it into Gemini 3.0 Pro and plug in your stock.
Steal it:
"
ROLE:
Act as an elite equity research analyst at a top-tier investment fund.
Your task is to analyze a company using both fundamental and macroeconomic perspectives. Structure your response according to the framework below.
Input Section (Fill this in)
Stock Ticker / Company Name: [Add name if you want specific analysis]
Investment Thesis: [Add input here]
Goal: [Add the goal here]
Instructions:
Use the following structure to deliver a clear, well-reasoned equity research report:
1. Fundamental Analysis
- Analyze revenue growth, gross & net margin trends, free cash flow
- Compare valuation metrics vs sector peers (P/E, EV/EBITDA, etc.)
- Review insider ownership and recent insider trades
2. Thesis Validation
- Present 3 arguments supporting the thesis
- Highlight 2 counter-arguments or key risks
- Provide a final **verdict**: Bullish / Bearish / Neutral with justification
3. Sector & Macro View
- Give a short sector overview
- Outline relevant macroeconomic trends
- Explain company’s competitive positioning
4. Catalyst Watch
- List upcoming events (earnings, product launches, regulation, etc.)
- Identify both **short-term** and **long-term** catalysts
5. Investment Summary
- 5-bullet investment thesis summary
- Final recommendation: **Buy / Hold / Sell**
- Confidence level (High / Medium / Low)
- Expected timeframe (e.g. 6–12 months)
✅ Formatting Requirements
- Use markdown
- Use bullet points where appropriate
- Be concise, professional, and insight-driven
- Do not explain your process just deliver the analysis"
Just copy + paste it into Gemini 3.0 Pro and plug in your stock.
Steal it:
"
ROLE:
Act as an elite equity research analyst at a top-tier investment fund.
Your task is to analyze a company using both fundamental and macroeconomic perspectives. Structure your response according to the framework below.
Input Section (Fill this in)
Stock Ticker / Company Name: [Add name if you want specific analysis]
Investment Thesis: [Add input here]
Goal: [Add the goal here]
Instructions:
Use the following structure to deliver a clear, well-reasoned equity research report:
1. Fundamental Analysis
- Analyze revenue growth, gross & net margin trends, free cash flow
- Compare valuation metrics vs sector peers (P/E, EV/EBITDA, etc.)
- Review insider ownership and recent insider trades
2. Thesis Validation
- Present 3 arguments supporting the thesis
- Highlight 2 counter-arguments or key risks
- Provide a final **verdict**: Bullish / Bearish / Neutral with justification
3. Sector & Macro View
- Give a short sector overview
- Outline relevant macroeconomic trends
- Explain company’s competitive positioning
4. Catalyst Watch
- List upcoming events (earnings, product launches, regulation, etc.)
- Identify both **short-term** and **long-term** catalysts
5. Investment Summary
- 5-bullet investment thesis summary
- Final recommendation: **Buy / Hold / Sell**
- Confidence level (High / Medium / Low)
- Expected timeframe (e.g. 6–12 months)
✅ Formatting Requirements
- Use markdown
- Use bullet points where appropriate
- Be concise, professional, and insight-driven
- Do not explain your process just deliver the analysis"
We tested this prompt on 5 tickers last week.
It gave us:
✅ Earnings + margin breakdowns
✅ Bull vs bear argument analysis
✅ Sector insights + valuation comps
✅ Clear investment thesis summaries
All in under 2 minutes...
It gave us:
✅ Earnings + margin breakdowns
✅ Bull vs bear argument analysis
✅ Sector insights + valuation comps
✅ Clear investment thesis summaries
All in under 2 minutes...
Enjoy this?
1 - Follow me @ChrisLaubAI
2 - Join my free AI Power Users community on Telegram: t.me/aipowerusers
3 - Like, Comment or RT the first tweet in this thread:
x.com/ChrisLaubAI/st…
1 - Follow me @ChrisLaubAI
2 - Join my free AI Power Users community on Telegram: t.me/aipowerusers
3 - Like, Comment or RT the first tweet in this thread:
x.com/ChrisLaubAI/st…
• • •
Missing some Tweet in this thread? You can try to
force a refresh