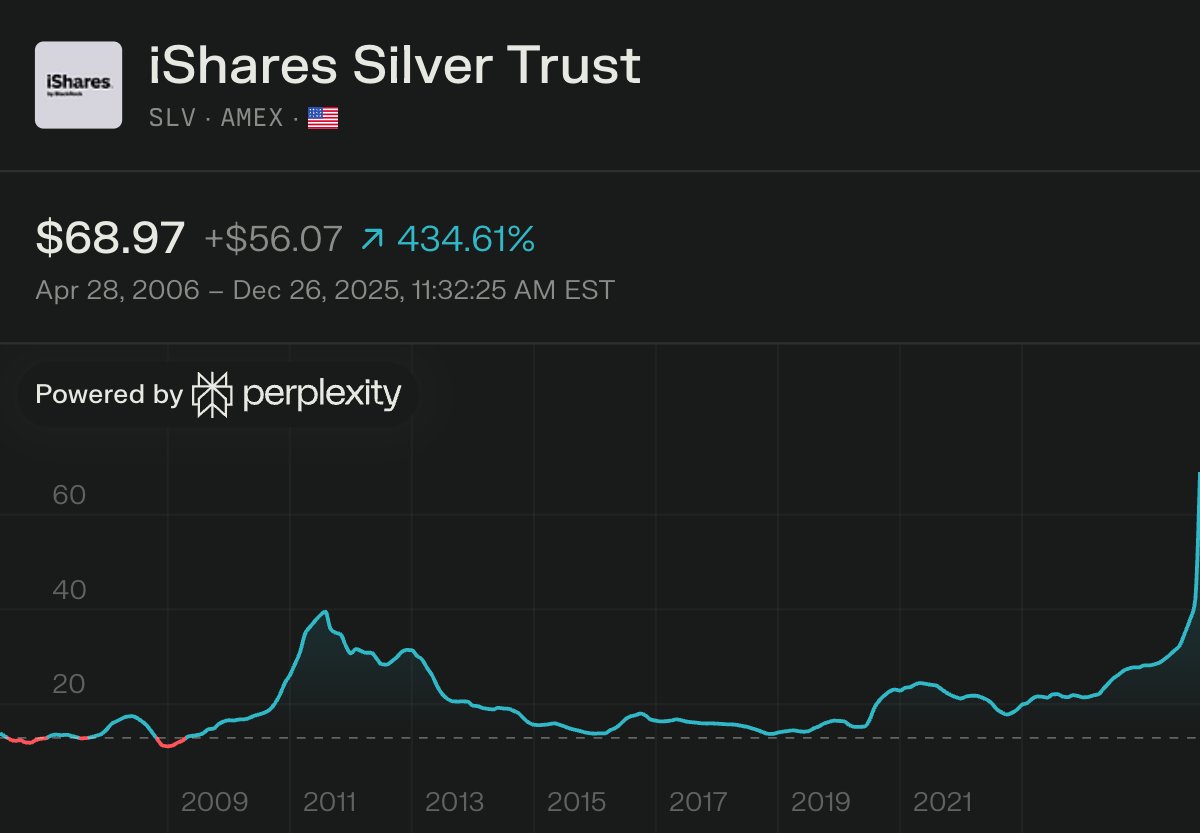
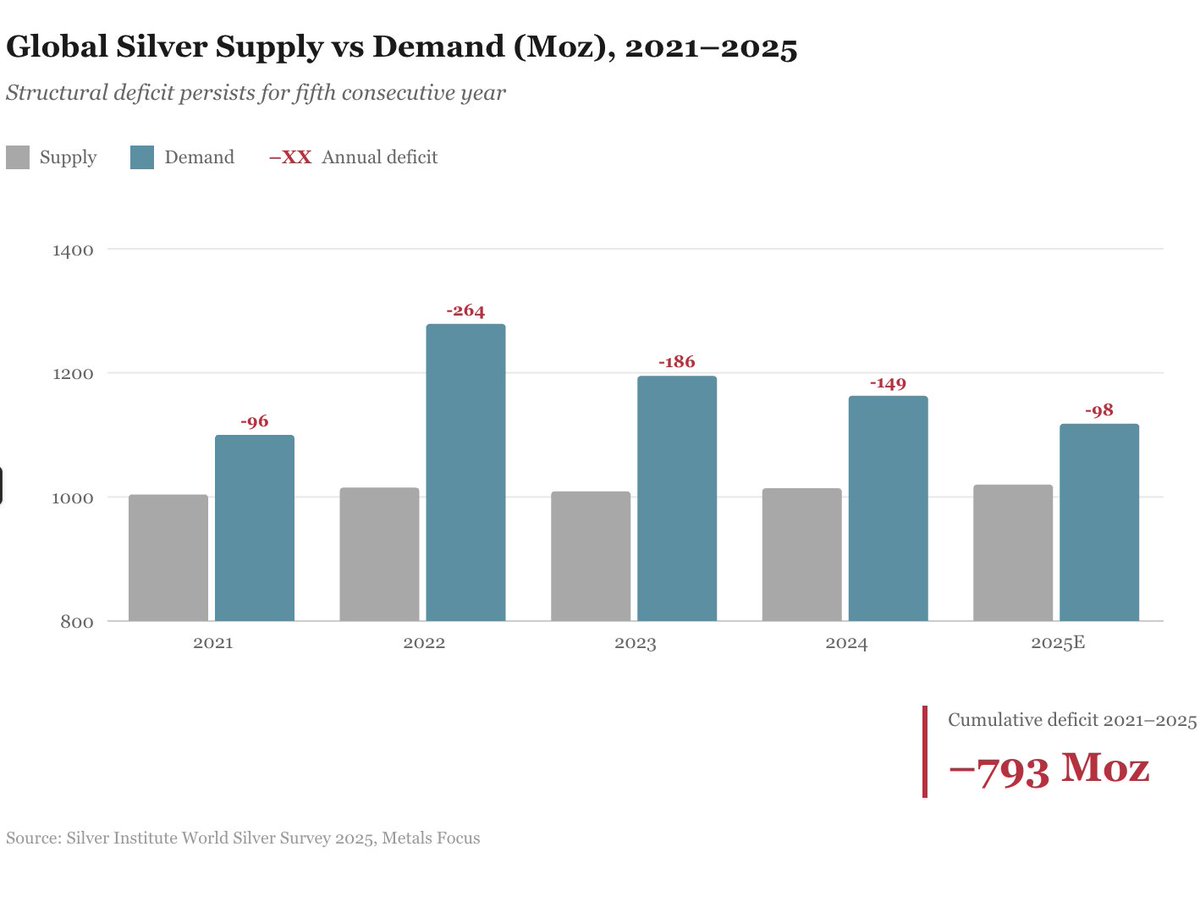
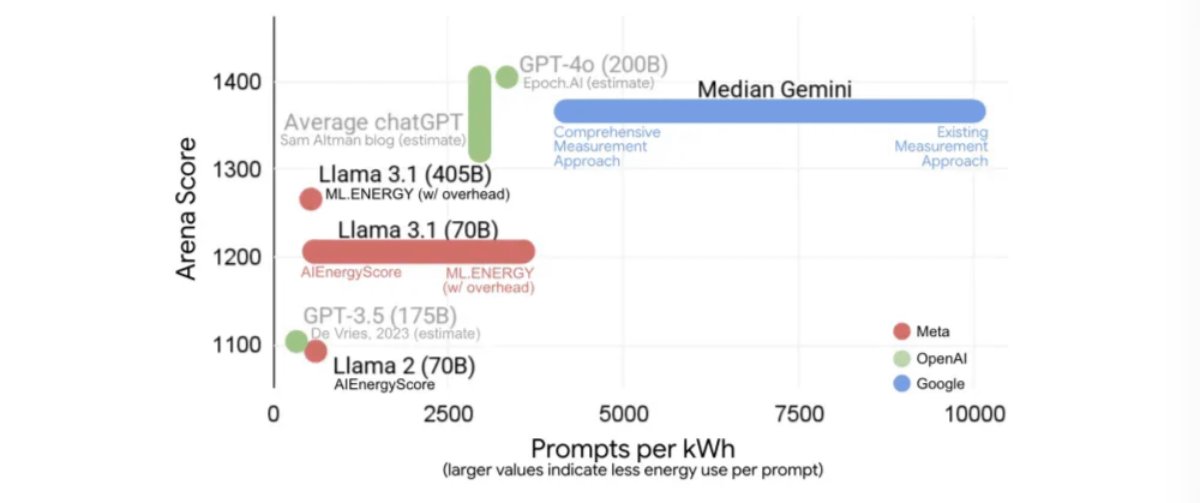
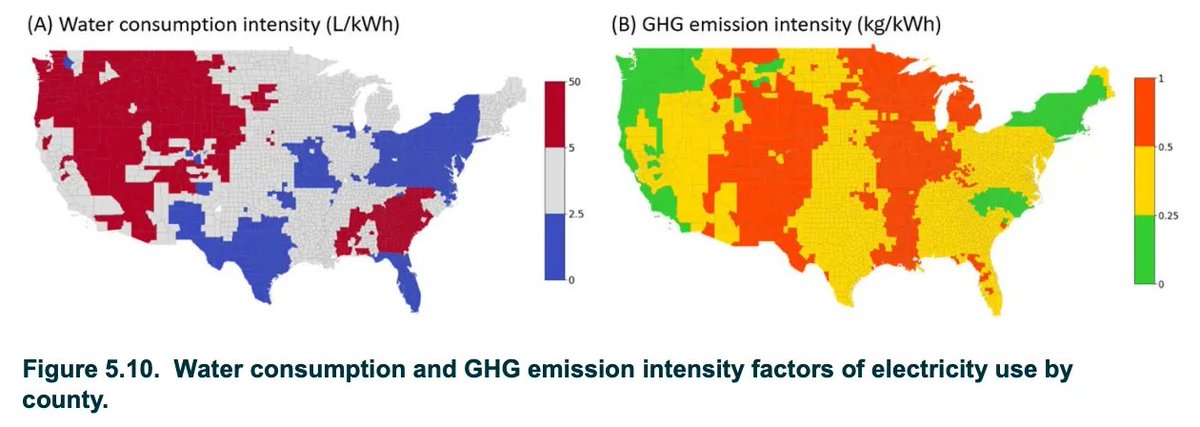
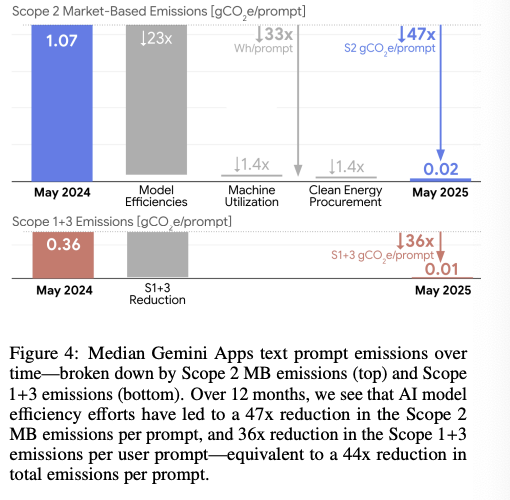
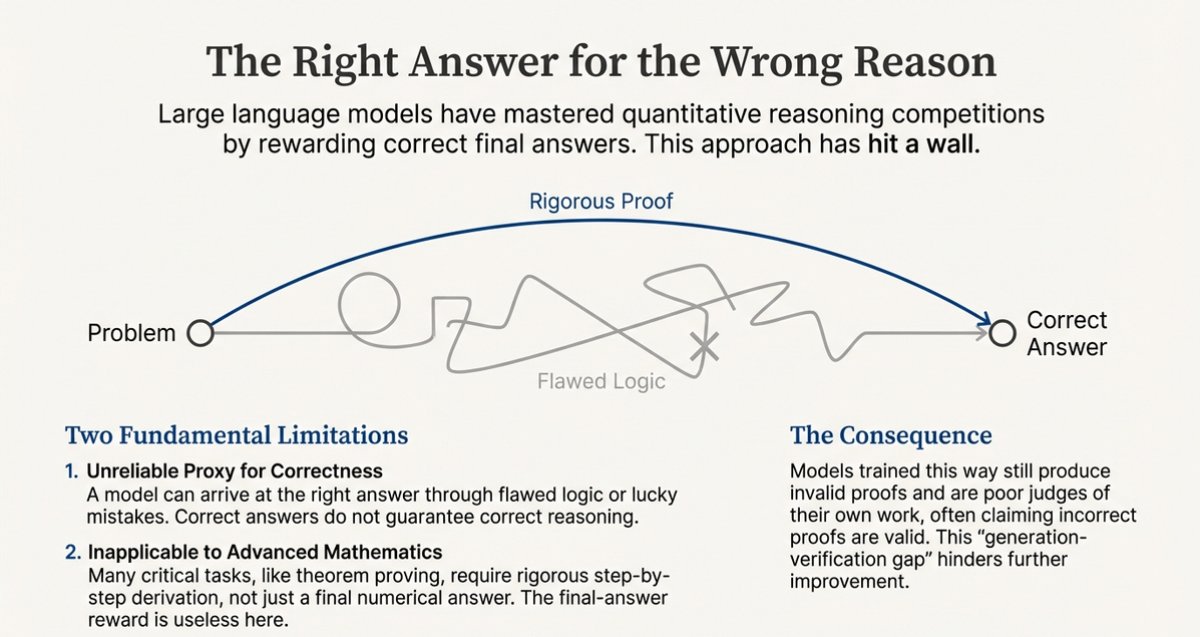
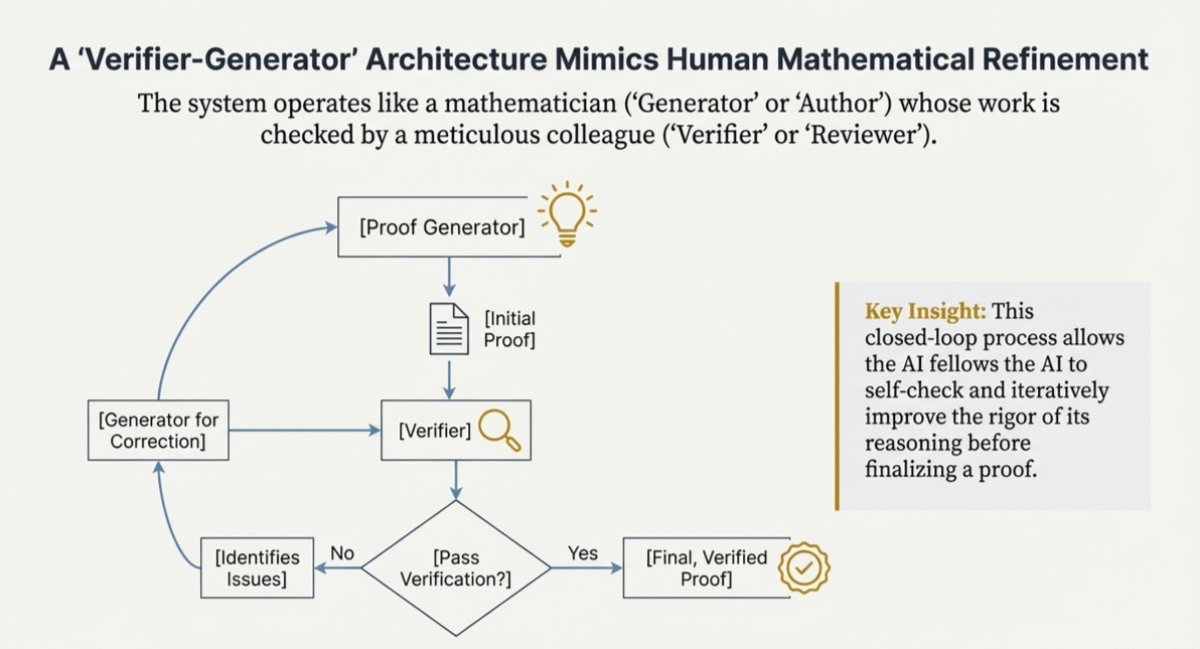
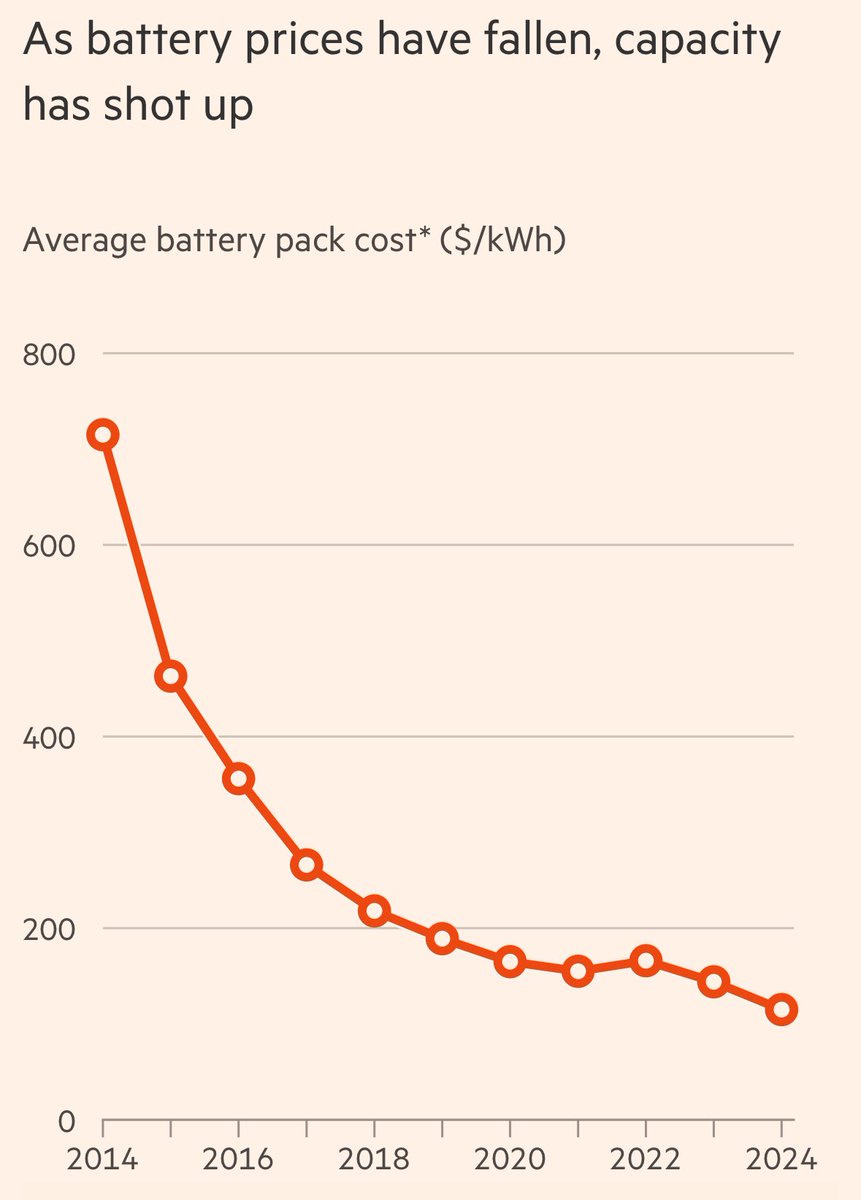
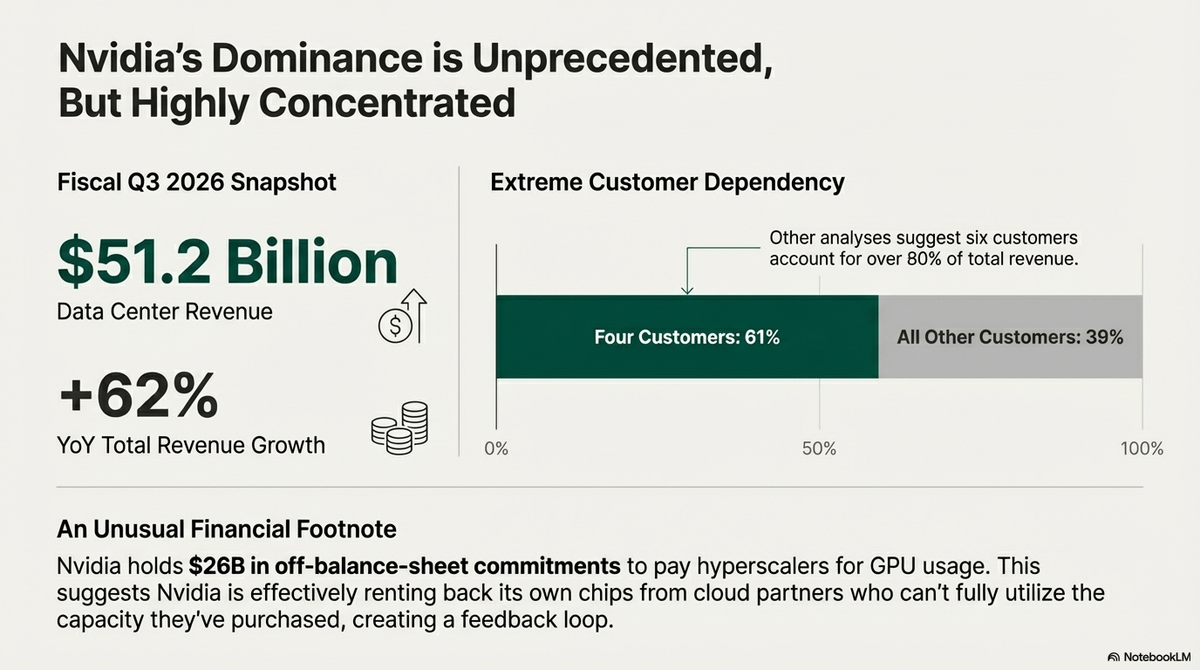
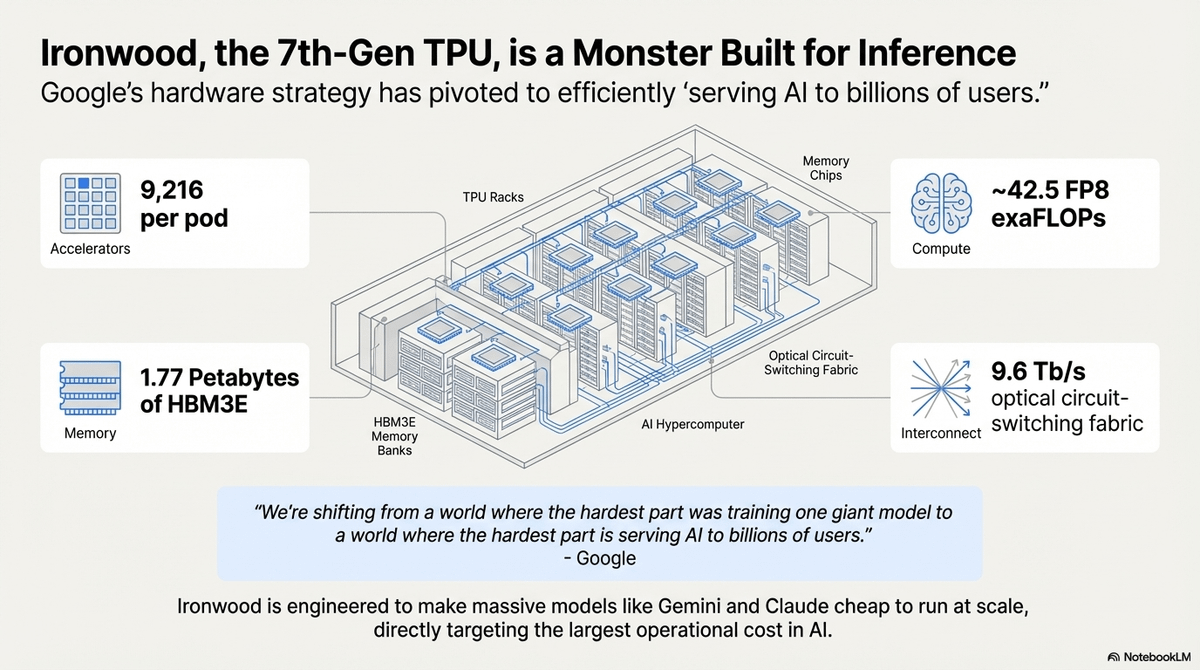
🚨The White House just launched the Genesis Mission — a Manhattan Project for AI
The Department of Energy will build a national AI platform on top of U.S. supercomputers and federal science data, train scientific foundation models, and run AI agents + robotic labs to automate experiments in biotech, critical materials, nuclear fission/fusion, space, quantum, and semiconductors.
Let’s unpack what this order actually builds, and how it could rewire the AI, energy, and science landscape over the next decade:
The Department of Energy will build a national AI platform on top of U.S. supercomputers and federal science data, train scientific foundation models, and run AI agents + robotic labs to automate experiments in biotech, critical materials, nuclear fission/fusion, space, quantum, and semiconductors.
Let’s unpack what this order actually builds, and how it could rewire the AI, energy, and science landscape over the next decade:

1/ At the core is a new American Science and Security Platform.
DOE is ordered to turn the national lab system into an integrated stack that provides:
• HPC for large-scale model training, simulation, inference
• Domain foundation models across physics, materials, bio, energy
• AI agents to explore design spaces, evaluate experiments, automate workflows
• Robotic/automated labs + production tools for AI-directed experiments and manufacturing
National-scale AI scientist + AI lab tech as infrastructure.
DOE is ordered to turn the national lab system into an integrated stack that provides:
• HPC for large-scale model training, simulation, inference
• Domain foundation models across physics, materials, bio, energy
• AI agents to explore design spaces, evaluate experiments, automate workflows
• Robotic/automated labs + production tools for AI-directed experiments and manufacturing
National-scale AI scientist + AI lab tech as infrastructure.

2/ The targets are very explicit and very strategic.
Within 60 days, DOE has to propose at least 20 “national challenges” in:
• advanced manufacturing
• biotechnology
• critical materials
• nuclear fission & fusion
• quantum information science
• semiconductors & microelectronics
This is about energy dominance, supply chains, and defense.
Within 60 days, DOE has to propose at least 20 “national challenges” in:
• advanced manufacturing
• biotechnology
• critical materials
• nuclear fission & fusion
• quantum information science
• semiconductors & microelectronics
This is about energy dominance, supply chains, and defense.

3/ The timelines are aggressive enough to matter:
• 60 days → list of challenges
• 90 days → full inventory of federal compute/network/storage for Genesis
• 120 days → initial model + data assets, plus a plan to ingest more datasets (other agencies, academia, private sector)
• 240 days → map all robotic labs and automated facilities across national labs
• 270 days → demonstrate initial operating capability on at least one challenge
Goal: A Functioning AI-for-science loop online in <9 months.
• 60 days → list of challenges
• 90 days → full inventory of federal compute/network/storage for Genesis
• 120 days → initial model + data assets, plus a plan to ingest more datasets (other agencies, academia, private sector)
• 240 days → map all robotic labs and automated facilities across national labs
• 270 days → demonstrate initial operating capability on at least one challenge
Goal: A Functioning AI-for-science loop online in <9 months.

4/ This also formalizes a federal AI stack parallel to the commercial one.
The order tells DOE and the White House science office to:
• align agency AI programs and datasets onto this platform
• run joint funding calls and prize programs
• build partnership frameworks with external players (co-dev agreements, user facilities, data/model sharing, IP rules)
Nvidia, OpenAI, Anthropic, xAI, Google, the clouds, biotech & chip companies are now potential suppliers and co-developers for a DOE AI system
The order tells DOE and the White House science office to:
• align agency AI programs and datasets onto this platform
• run joint funding calls and prize programs
• build partnership frameworks with external players (co-dev agreements, user facilities, data/model sharing, IP rules)
Nvidia, OpenAI, Anthropic, xAI, Google, the clouds, biotech & chip companies are now potential suppliers and co-developers for a DOE AI system

5/ Genesis marks a clear shift
Until now, frontier AI has mostly been driven by private labs. With Genesis, the U.S. is explicitly building a state-run AI backbone for science, energy, and security:
• DOE coordinates a national AI-for-science platform
• National labs and supercomputers become part of a unified AI stack
• Models, agents, and robotic labs are treated as strategic infrastructure, not just tools
The questions now are who supplies the compute and models, how IP and data are shared, and how fast other countries launch their own Genesis-style efforts?
whitehouse.gov/presidential-a…
Until now, frontier AI has mostly been driven by private labs. With Genesis, the U.S. is explicitly building a state-run AI backbone for science, energy, and security:
• DOE coordinates a national AI-for-science platform
• National labs and supercomputers become part of a unified AI stack
• Models, agents, and robotic labs are treated as strategic infrastructure, not just tools
The questions now are who supplies the compute and models, how IP and data are shared, and how fast other countries launch their own Genesis-style efforts?
whitehouse.gov/presidential-a…
• • •
Missing some Tweet in this thread? You can try to
force a refresh