🐋 The Whale is back!!
DeepSeek just dropped an IMO gold-medalist model.
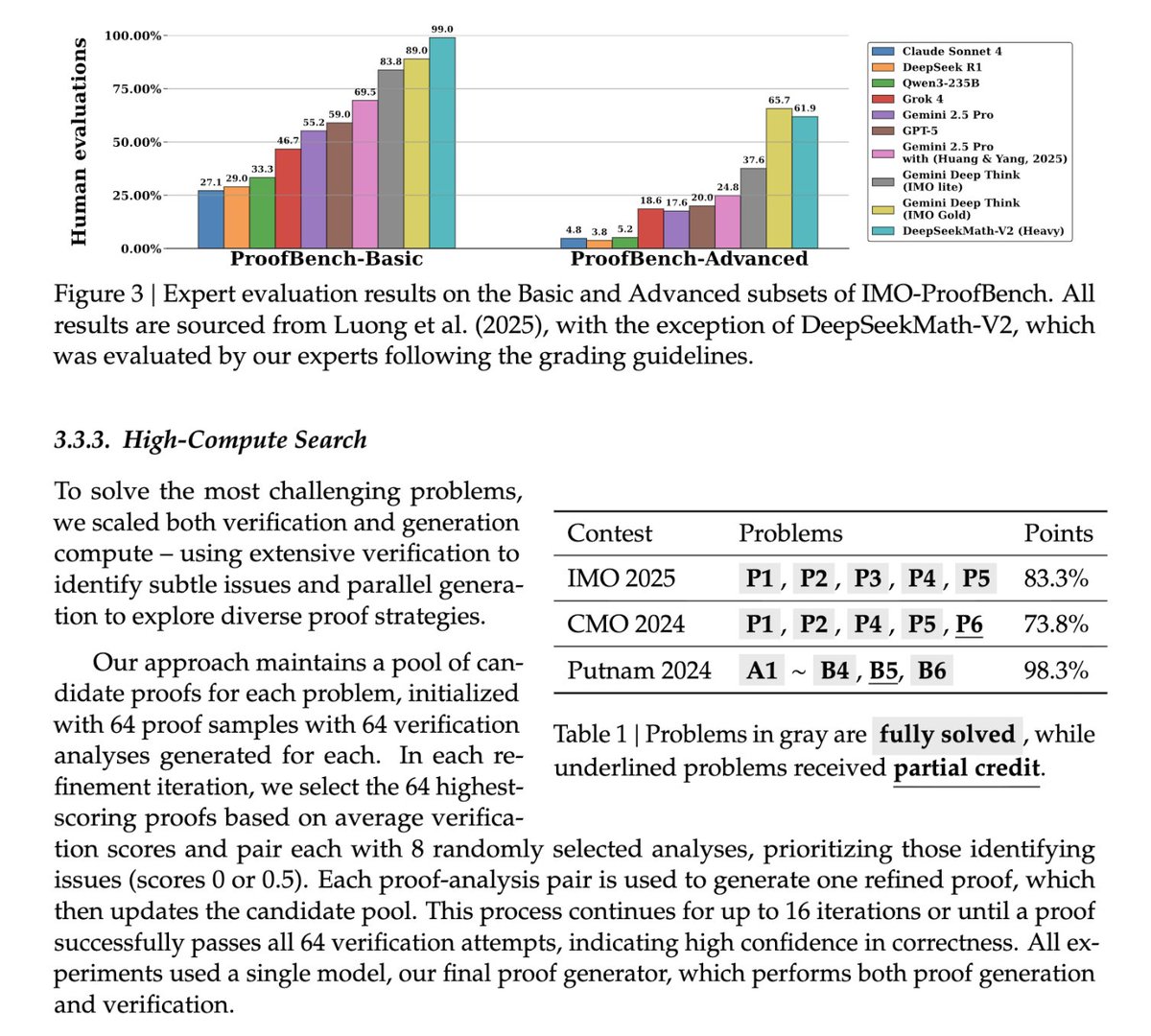
On ProofBench-Advanced—where models prove formal mathematical theorems—GPT-5 scores 20%. Gemini Deep Think IMO Gold hits 65.7%. DeepSeek Math V2 (Heavy) scores 61.9%.
That's second place—but Gemini isn't open source.
This is the best open math model in the world. And DeepSeek released the weights. Apache 2.0.
Here's what they discovered:
DeepSeek just dropped an IMO gold-medalist model.
On ProofBench-Advanced—where models prove formal mathematical theorems—GPT-5 scores 20%. Gemini Deep Think IMO Gold hits 65.7%. DeepSeek Math V2 (Heavy) scores 61.9%.
That's second place—but Gemini isn't open source.
This is the best open math model in the world. And DeepSeek released the weights. Apache 2.0.
Here's what they discovered:


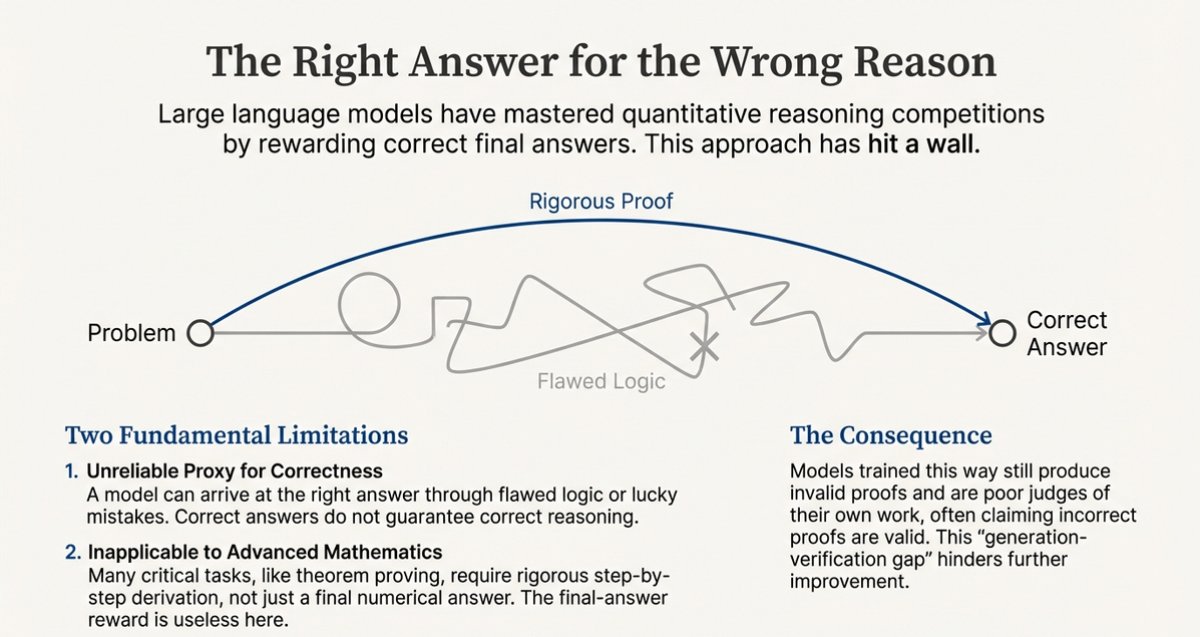
1/ Why Normal LLMs Break on Real Math
Most large language models are great at sounding smart, but:
- They’re rewarded for the final answer, not the reasoning.
- If they accidentally land on the right number with bad logic, they still get full credit.
- Over time they become “confident liars”: fluent, persuasive, and sometimes wrong.
That’s fatal for real math, where the proof is the product.
To fix this, DeepSeek Math V2 changes what the model gets rewarded for: not just being right, but being rigorously right.
Most large language models are great at sounding smart, but:
- They’re rewarded for the final answer, not the reasoning.
- If they accidentally land on the right number with bad logic, they still get full credit.
- Over time they become “confident liars”: fluent, persuasive, and sometimes wrong.
That’s fatal for real math, where the proof is the product.
To fix this, DeepSeek Math V2 changes what the model gets rewarded for: not just being right, but being rigorously right.
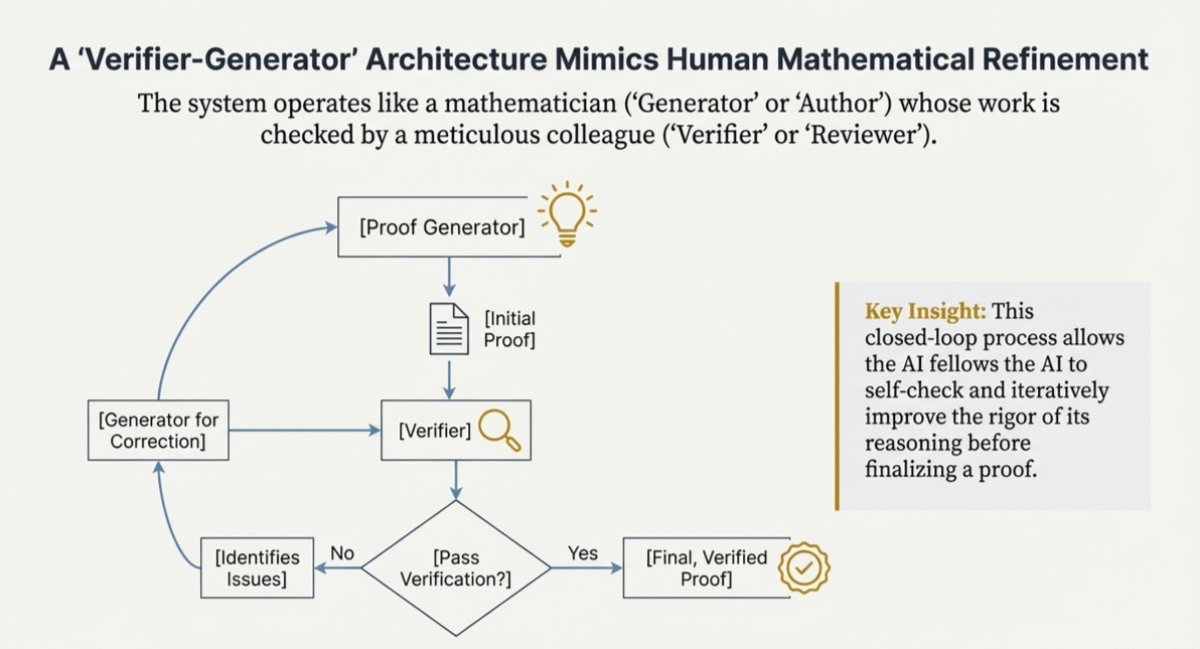
2/ The Core Idea: Generator + Verifier
Instead of one model doing everything, DeepSeek splits the job:
1. Generator – the “mathematician”
- Produces a full, step-by-step proof.
2. Verifier – the “internal auditor”
- Checks the proof for logical soundness.
- Ignores the final answer. It only cares about the reasoning.
This creates an internal feedback loop:
One model proposes, the other critiques.
Instead of one model doing everything, DeepSeek splits the job:
1. Generator – the “mathematician”
- Produces a full, step-by-step proof.
2. Verifier – the “internal auditor”
- Checks the proof for logical soundness.
- Ignores the final answer. It only cares about the reasoning.
This creates an internal feedback loop:
One model proposes, the other critiques.
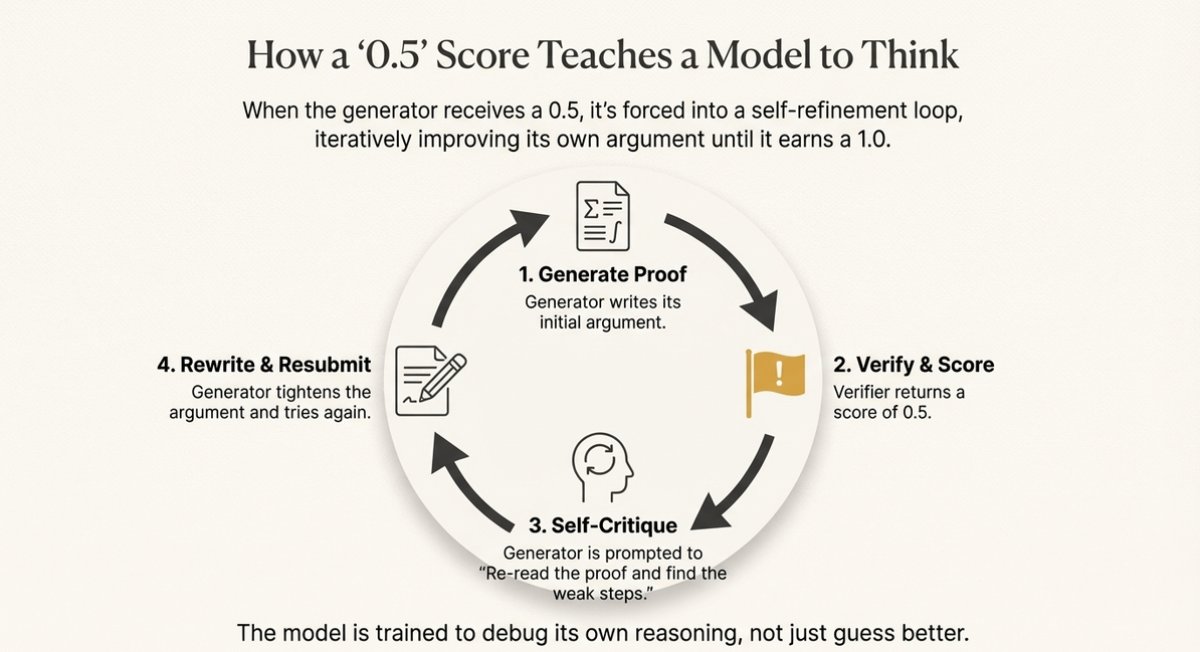
3/ The Secret Sauce: 1.0/0.5/0.0
The verifier doesn't just say yes or no. It scores on three levels:
1.0 = Rigorous, watertight
0.5 = Right idea, sloppy execution
0.0 = Fatal flaws
That 0.5 is the breakthrough.
It's the referee saying: "You solved it, but this wouldn't pass peer review."
When the generator sees 0.5, it re-reads its own proof, finds the weak steps, tightens the argument.
The model learns to debug its reasoning, not just guess better.
The verifier doesn't just say yes or no. It scores on three levels:
1.0 = Rigorous, watertight
0.5 = Right idea, sloppy execution
0.0 = Fatal flaws
That 0.5 is the breakthrough.
It's the referee saying: "You solved it, but this wouldn't pass peer review."
When the generator sees 0.5, it re-reads its own proof, finds the weak steps, tightens the argument.
The model learns to debug its reasoning, not just guess better.
4/ Putnam, IMO, and ProofBench
- Putnam 2024 – ~118/120
- IMO-Gold level performance
- On a “basic” proof dataset, V2 almost perfectly solves the set
- On an “advanced” dataset with long, tricky proofs, it still performs strongly, while many other large models collapse in accuracy
Models without this internal verifier do okay on short, easy proofs…
…and then fall off a cliff on long, complex ones.
DeepSeek’s architecture shows that built-in self-checking is the difference between “good at math questions” and “actually good at proofs.”
- Putnam 2024 – ~118/120
- IMO-Gold level performance
- On a “basic” proof dataset, V2 almost perfectly solves the set
- On an “advanced” dataset with long, tricky proofs, it still performs strongly, while many other large models collapse in accuracy
Models without this internal verifier do okay on short, easy proofs…
…and then fall off a cliff on long, complex ones.
DeepSeek’s architecture shows that built-in self-checking is the difference between “good at math questions” and “actually good at proofs.”

5/ How They Trained It
Big risk is if the generator gets smart and the verifier stays weak, the generator learns to game it.
Three-phase solution:
Phase 1 – Human Cold Start. Contest problems graded by expert mathematicians. Anchors the verifier to real standards.
Phase 2 – Meta-Verification. The verifier can start hallucinating errors—seeing problems that don't exist. Solution: a second model checks whether critiques are legitimate or noise.
Phase 3 – Scaled Compute. For the hardest problems, human labeling is too slow. Run many verification passes, use majority vote as training signal.
Humans set the rules. Compute scales them.
Big risk is if the generator gets smart and the verifier stays weak, the generator learns to game it.
Three-phase solution:
Phase 1 – Human Cold Start. Contest problems graded by expert mathematicians. Anchors the verifier to real standards.
Phase 2 – Meta-Verification. The verifier can start hallucinating errors—seeing problems that don't exist. Solution: a second model checks whether critiques are legitimate or noise.
Phase 3 – Scaled Compute. For the hardest problems, human labeling is too slow. Run many verification passes, use majority vote as training signal.
Humans set the rules. Compute scales them.


6/ Big Model, Big Hardware
DeepSeek Math V2 is a Mixture-of-Experts (MoE) model with about 685B parameters.
- Only some “experts” are active per problem, so each step is cheaper than a dense 685B model
- But all those parameters still have to live in GPU memory
The code is open. The bottleneck is compute.
DeepSeek Math V2 is a Mixture-of-Experts (MoE) model with about 685B parameters.
- Only some “experts” are active per problem, so each step is cheaper than a dense 685B model
- But all those parameters still have to live in GPU memory
The code is open. The bottleneck is compute.

7/ How You Actually Use It: Agent Mode
In practice, you don’t just send one prompt and get a perfect proof.
Instead, you run it in agent mode, something like:
1. Ask it to solve a problem.
2. It generates a proof and a self-verification score.
3. If the score is 0.5, you feed its own critique back in:
- “Refine this proof based on the issues you identified.”
4. Repeat this refinement loop a few times (e.g., up to 8 rounds).
5. Stop when it produces a 1.0 proof or you’re satisfied.
You're managing a feedback loop, not passively waiting for output.
In practice, you don’t just send one prompt and get a perfect proof.
Instead, you run it in agent mode, something like:
1. Ask it to solve a problem.
2. It generates a proof and a self-verification score.
3. If the score is 0.5, you feed its own critique back in:
- “Refine this proof based on the issues you identified.”
4. Repeat this refinement loop a few times (e.g., up to 8 rounds).
5. Stop when it produces a 1.0 proof or you’re satisfied.
You're managing a feedback loop, not passively waiting for output.

8/ Limitations
Creativity. Great at formal reasoning and polishing proofs. Still struggles with problems needing genuinely novel insight.
Cost. Those record-setting scores rely on many proof attempts and verification runs. Real-world use means cheaper settings, slightly lower performance.
Residual Errors. The verifier is still a neural net. It can be fooled. Error rate is lower, not zero.
This is a big leap toward reliable reasoning—not "perfect AI mathematician."
Creativity. Great at formal reasoning and polishing proofs. Still struggles with problems needing genuinely novel insight.
Cost. Those record-setting scores rely on many proof attempts and verification runs. Real-world use means cheaper settings, slightly lower performance.
Residual Errors. The verifier is still a neural net. It can be fooled. Error rate is lower, not zero.
This is a big leap toward reliable reasoning—not "perfect AI mathematician."

9/ From Chatbots to Reasoners
DeepSeek Math V2 represents more than just a math milestone.
The pattern here will spread:
- Split generation and verification
- Train on proof quality, not just right answers
- Add self-critique loops and meta-verifiers
This is the template for any domain where being wrong is expensive—code, science, law, anything that needs to survive peer review.
DeepSeek Math V2 represents more than just a math milestone.
The pattern here will spread:
- Split generation and verification
- Train on proof quality, not just right answers
- Add self-critique loops and meta-verifiers
This is the template for any domain where being wrong is expensive—code, science, law, anything that needs to survive peer review.

• • •
Missing some Tweet in this thread? You can try to
force a refresh