Claude Code over Excel++ 🤖📊
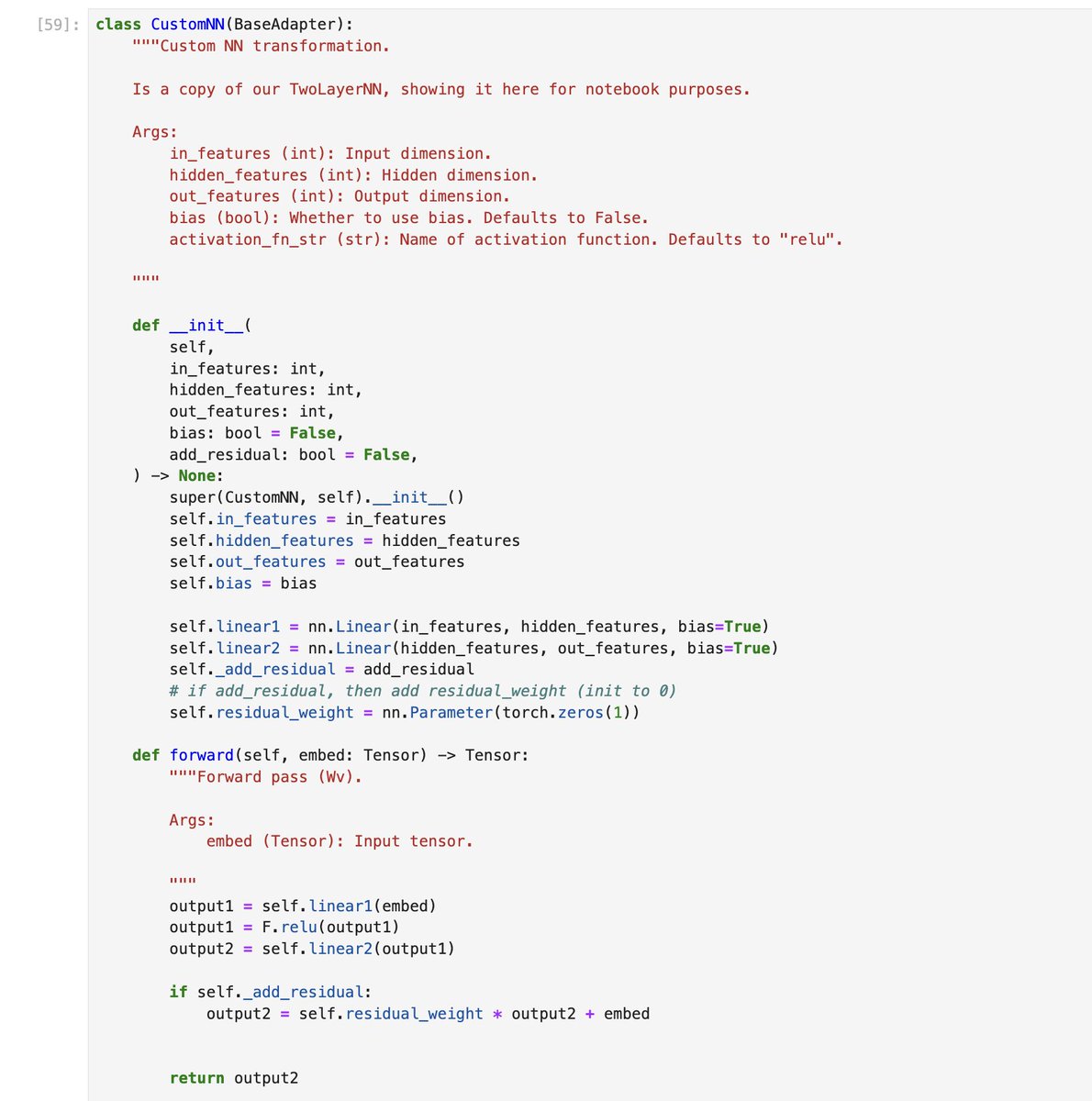
Claude already 'works' over Excel, but in a naive manner - it writes raw python/openpyxl to analyze an Excel sheet cell-by-cell and generally lacks a semantic understanding of the content. Basically the coding abstractions used are too low-level to have the coding agent accurately do more sophisticated analysis.
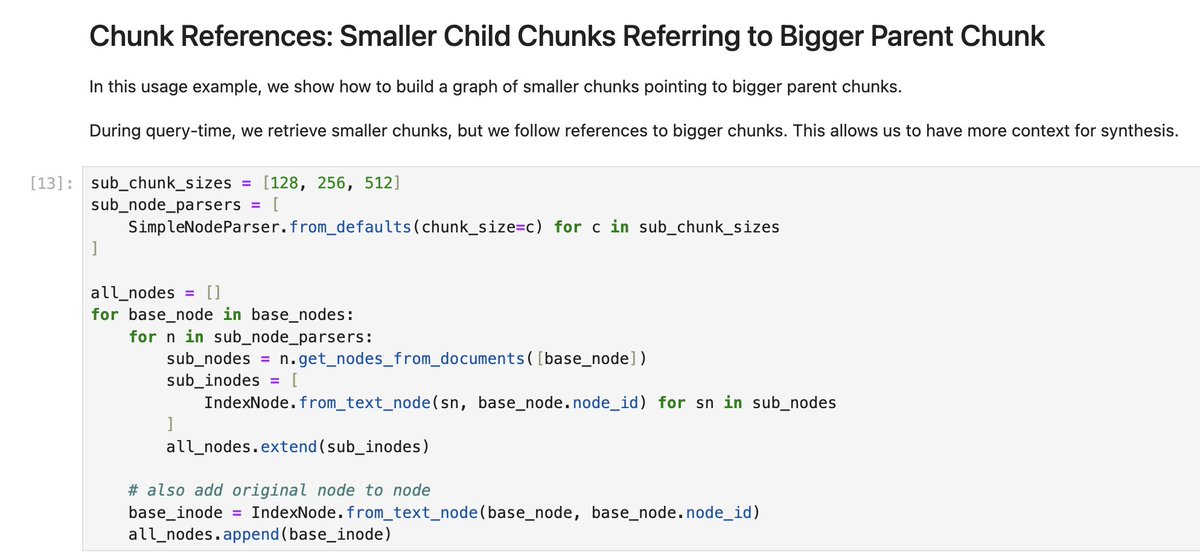
Our new LlamaSheets API lets you automatically segment structure complex Excel sheets into well-formatted 2D tables. This both gives Claude Code immediate semantic awareness of the sheet, and allows it to run Pandas/SQL over well-structured dataframes.
We've written a guide showing you how specifically to use LlamaSheets with coding agents!
Guide: developers.llamaindex.ai/python/cloud/l…
Sign up to LlamaCloud: cloud.llamaindex.ai
Claude already 'works' over Excel, but in a naive manner - it writes raw python/openpyxl to analyze an Excel sheet cell-by-cell and generally lacks a semantic understanding of the content. Basically the coding abstractions used are too low-level to have the coding agent accurately do more sophisticated analysis.
Our new LlamaSheets API lets you automatically segment structure complex Excel sheets into well-formatted 2D tables. This both gives Claude Code immediate semantic awareness of the sheet, and allows it to run Pandas/SQL over well-structured dataframes.
We've written a guide showing you how specifically to use LlamaSheets with coding agents!
Guide: developers.llamaindex.ai/python/cloud/l…
Sign up to LlamaCloud: cloud.llamaindex.ai
• • •
Missing some Tweet in this thread? You can try to
force a refresh