🎄 Advent of Small ML: Day 7 🎄 Topic: Entropy-Based Rewards (Forcing the model to "keep its options open")
there’s a fascinating recent paper (Layer by Layer: Uncovering Hidden Representations in Language Models - arxiv.org/abs/2502.02013 - shown to me by @aditjain1980) showing that reasoning models tend to have higher entropy in their middle layers
basically, instead of collapsing to an answer early, they keep more possibilities "alive" in their hidden states while thinking.
it made me think - if high entropy correlates with better reasoning, can we force the model to reason better by explicitly rewarding high entropy?
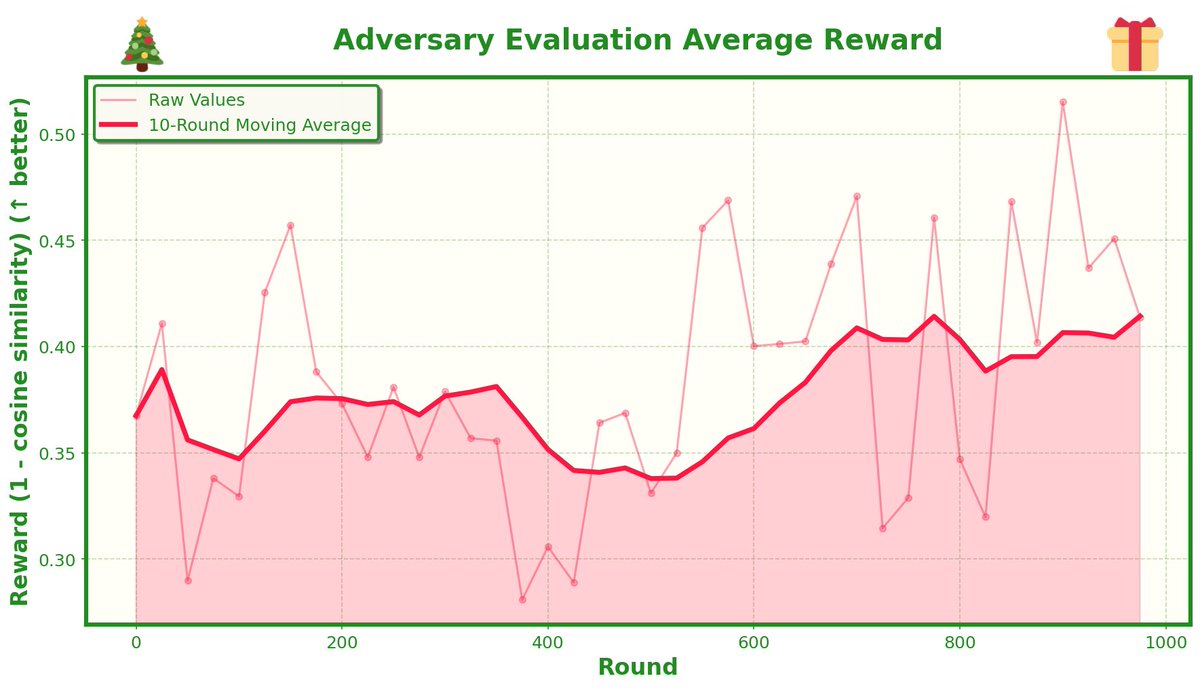
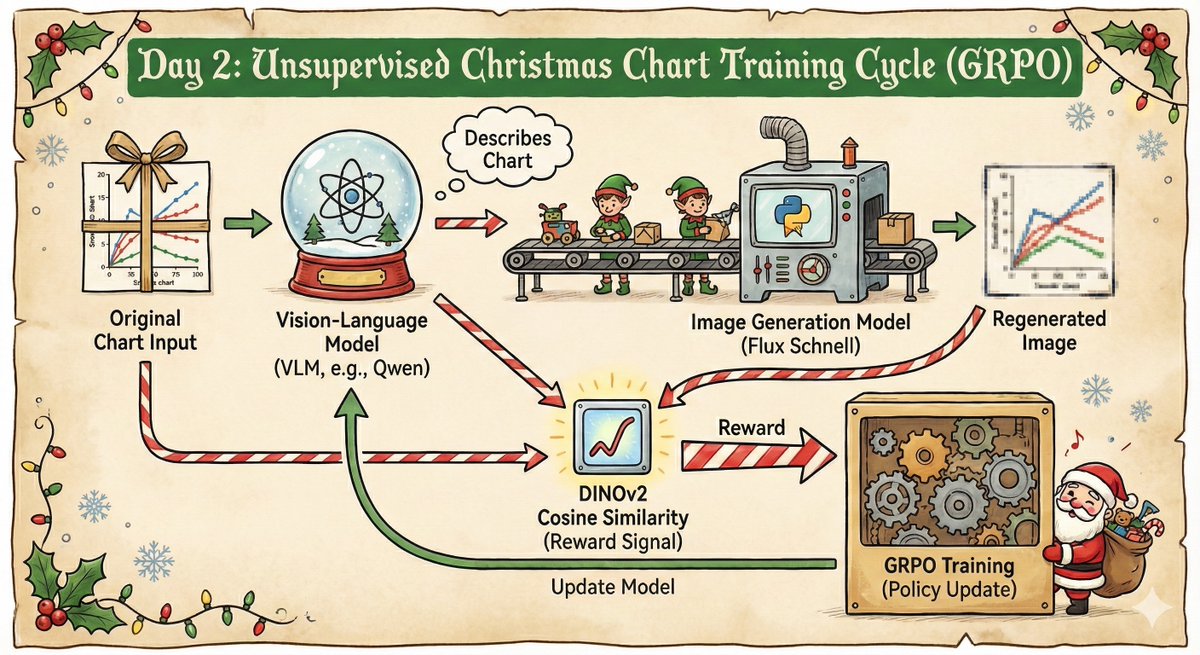
so I added a Matrix-based Entropy reward (Rényi entropy on eigenvalues) to GRPO training on the MATH500 dataset, rewarding the amount of entropy on the middle 10 layers of qwen 2.5 7b
the initial results were mixed.
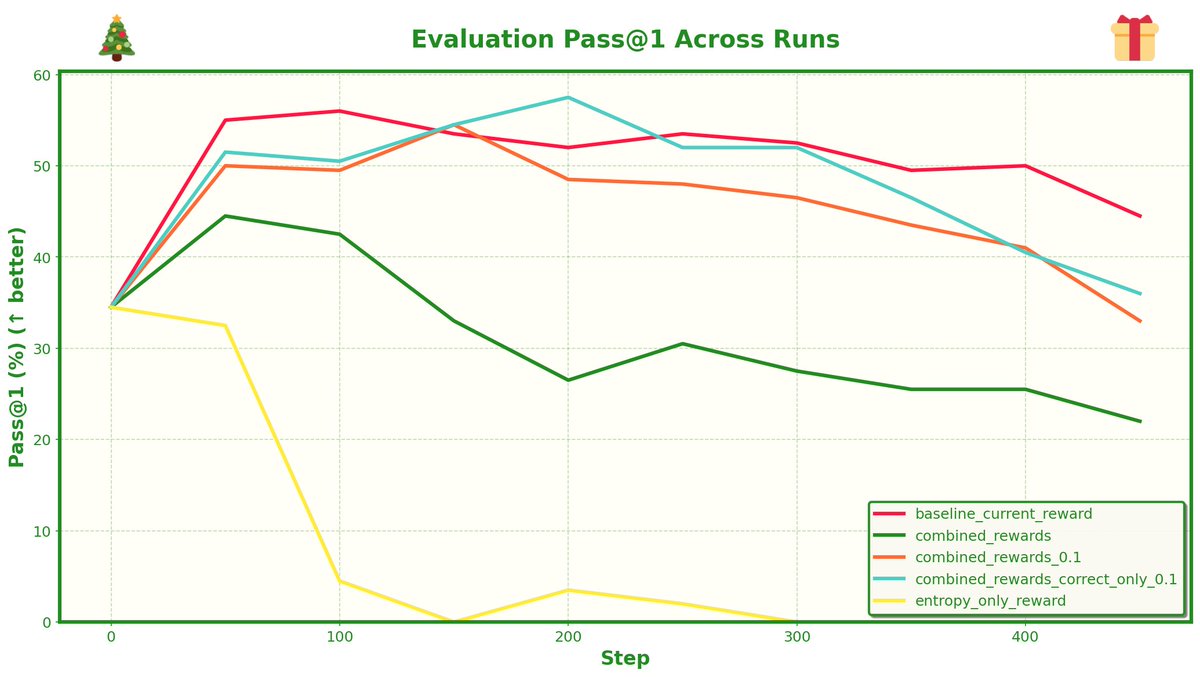
when I just rewarded entropy, the model definitely increased its entropy... but it didn't get better at math. It just learned to be "confused" and exploratory without actually converging on answers.
It produced some pretty funny outputs, going on weird tangents and "overthinking" simple problems (examples below)
But then I changed the rewarding rule: Only reward high entropy if the final answer is CORRECT.
this worked (sort of) - it gave a 2.5% performance boost over the baseline.
this is a proof of concept that we can use RL to shape the internal dynamics of how a model thinks, not just its final output tokens.
Repo + Plots below
there’s a fascinating recent paper (Layer by Layer: Uncovering Hidden Representations in Language Models - arxiv.org/abs/2502.02013 - shown to me by @aditjain1980) showing that reasoning models tend to have higher entropy in their middle layers
basically, instead of collapsing to an answer early, they keep more possibilities "alive" in their hidden states while thinking.
it made me think - if high entropy correlates with better reasoning, can we force the model to reason better by explicitly rewarding high entropy?
so I added a Matrix-based Entropy reward (Rényi entropy on eigenvalues) to GRPO training on the MATH500 dataset, rewarding the amount of entropy on the middle 10 layers of qwen 2.5 7b
the initial results were mixed.
when I just rewarded entropy, the model definitely increased its entropy... but it didn't get better at math. It just learned to be "confused" and exploratory without actually converging on answers.
It produced some pretty funny outputs, going on weird tangents and "overthinking" simple problems (examples below)
But then I changed the rewarding rule: Only reward high entropy if the final answer is CORRECT.
this worked (sort of) - it gave a 2.5% performance boost over the baseline.
this is a proof of concept that we can use RL to shape the internal dynamics of how a model thinks, not just its final output tokens.
Repo + Plots below

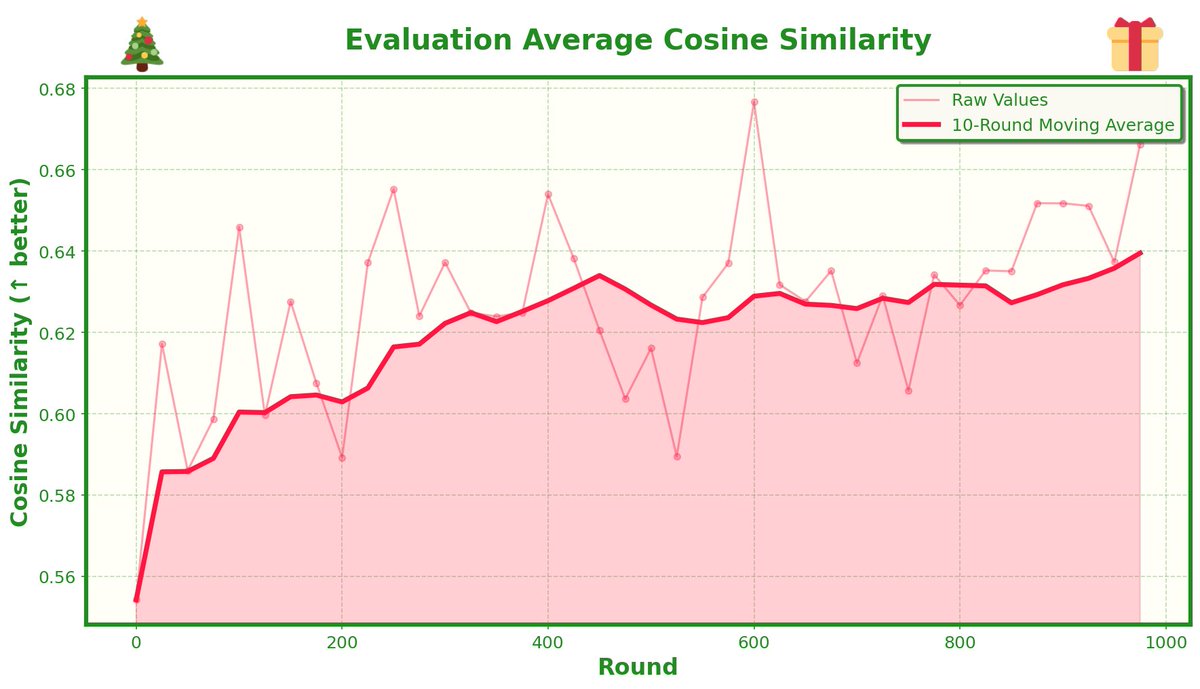
Entropy results - entropy of 10 layers throughout training

Pass@1 on eval set for math500 - its very minor but the peak score is higher when entropy is rewarded
qualitatively I love the reasoning traces from the higher entropy models - feels very refreshing/not normal llm speak - some examples below



• • •
Missing some Tweet in this thread? You can try to
force a refresh