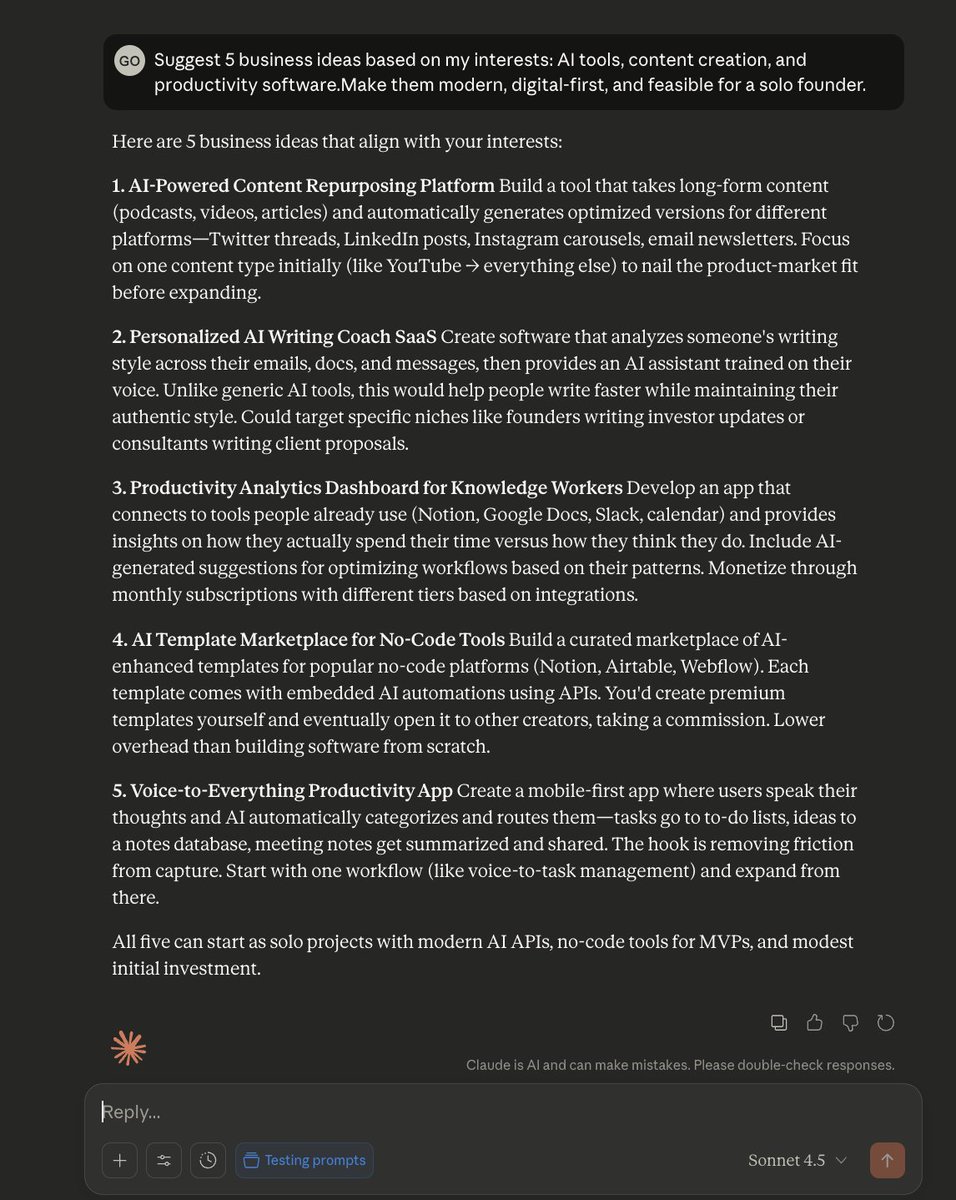
Most people ask AI to “write a blog post” and then wonder why it sounds generic.
What they don’t know is that elite writers and research teams use hidden prompting techniques specifically for long-form writing.
These 10 techniques control structure, coherence, and depth over thousands of words. Almost nobody uses them.
Here are the advanced prompt techniques for writing blogs, essays, and newsletters
Bookmark this.
What they don’t know is that elite writers and research teams use hidden prompting techniques specifically for long-form writing.
These 10 techniques control structure, coherence, and depth over thousands of words. Almost nobody uses them.
Here are the advanced prompt techniques for writing blogs, essays, and newsletters
Bookmark this.
Technique 1: Invisible Outline Lock
Great long-form writing lives or dies by structure.
Instead of asking for an outline, experts force the model to create one silently and obey it.
Template:
"Before writing, internally create a detailed outline optimized for clarity,
logical flow, and narrative momentum.
Do not show the outline.
Write the full article strictly following it."
Great long-form writing lives or dies by structure.
Instead of asking for an outline, experts force the model to create one silently and obey it.
Template:
"Before writing, internally create a detailed outline optimized for clarity,
logical flow, and narrative momentum.
Do not show the outline.
Write the full article strictly following it."

Technique 2: Section Cognitive Load Control
Most AI articles fail because they introduce too many ideas at once.
Experts cap idea density per section.
Template:
"Each section may introduce only ONE new core idea.
If additional ideas arise, defer them to later sections."
Most AI articles fail because they introduce too many ideas at once.
Experts cap idea density per section.
Template:
"Each section may introduce only ONE new core idea.
If additional ideas arise, defer them to later sections."

Technique 3: Reader State Anchoring
Professionals prompt for reader psychology, not just content.
Template:
"Assume the reader starts confused and skeptical.
By the end, they should feel clarity, confidence, and momentum.
Maintain this emotional progression throughout the piece."
Professionals prompt for reader psychology, not just content.
Template:
"Assume the reader starts confused and skeptical.
By the end, they should feel clarity, confidence, and momentum.
Maintain this emotional progression throughout the piece."

Technique 4: Anti-Summary Constraint
Summaries kill long-form depth.
Experts ban them.
Template:
"Do not use summarizing phrases such as:
"in conclusion", "to summarize", "overall", "in short".
End sections by opening curiosity, not closing it."
Summaries kill long-form depth.
Experts ban them.
Template:
"Do not use summarizing phrases such as:
"in conclusion", "to summarize", "overall", "in short".
End sections by opening curiosity, not closing it."

Technique 5: Concept Compression Pass
High-level writers increase density without shortening length.
Template:
"After writing each section, internally rewrite it to:
- Remove redundancy
- Increase conceptual density
- Preserve length and tone"
High-level writers increase density without shortening length.
Template:
"After writing each section, internally rewrite it to:
- Remove redundancy
- Increase conceptual density
- Preserve length and tone"

Technique 6: False Consensus Breaker
Generic writing follows common beliefs.
Great writing challenges them.
Template:
"Explicitly challenge the most common belief about this topic
before presenting the correct framing."
Generic writing follows common beliefs.
Great writing challenges them.
Template:
"Explicitly challenge the most common belief about this topic
before presenting the correct framing."

Technique 7: Expert Blind-Spot Injection
Experts skip steps beginners need.
This forces the model to include them.
Template:
"Include insights that experts assume are obvious and therefore
rarely explain, but beginners desperately need."
Experts skip steps beginners need.
This forces the model to include them.
Template:
"Include insights that experts assume are obvious and therefore
rarely explain, but beginners desperately need."
Technique 8: Temporal Authority Shift
You shift the writing from theory to lived experience.
Template:
"Write this as if it was written AFTER applying these ideas
in the real world and observing what actually worked and failed."
You shift the writing from theory to lived experience.
Template:
"Write this as if it was written AFTER applying these ideas
in the real world and observing what actually worked and failed."
Technique 9: Section Purpose Lock
Every section must do one job only.
Template:
"Each section must serve exactly ONE purpose:
- Reframe belief
- Teach a mechanism
- Remove confusion
- Increase motivation
Do not mix purposes."
Every section must do one job only.
Template:
"Each section must serve exactly ONE purpose:
- Reframe belief
- Teach a mechanism
- Remove confusion
- Increase motivation
Do not mix purposes."
Technique 10: Self-Critiquing Writer Loop
Elite prompts force self-editing before delivery.
Template:
"Before finalizing, internally critique the piece for:
- Generic phrasing
- Shallow explanations
- Missed nuance
Fix all issues before presenting the final version."
Elite prompts force self-editing before delivery.
Template:
"Before finalizing, internally critique the piece for:
- Generic phrasing
- Shallow explanations
- Missed nuance
Fix all issues before presenting the final version."
The difference between bad AI writing and great AI writing is not talent.
It’s prompt architecture.
Most people prompt for topics.
Experts prompt for thinking, structure, and reader psychology.
These techniques aren’t secret.
They’re just buried in research papers nobody reads.
Now you know them.
No more generic long-form content.
It’s prompt architecture.
Most people prompt for topics.
Experts prompt for thinking, structure, and reader psychology.
These techniques aren’t secret.
They’re just buried in research papers nobody reads.
Now you know them.
No more generic long-form content.
The AI prompt library your competitors don't want you to find
→ Biggest collection of text & image prompts
→ Unlimited custom prompts
→ Lifetime access & updates
Grab it before it's gone 👇
godofprompt.ai/pricing
→ Biggest collection of text & image prompts
→ Unlimited custom prompts
→ Lifetime access & updates
Grab it before it's gone 👇
godofprompt.ai/pricing
That's a wrap:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
https://twitter.com/1643695629665722379/status/1999798129512817109
• • •
Missing some Tweet in this thread? You can try to
force a refresh