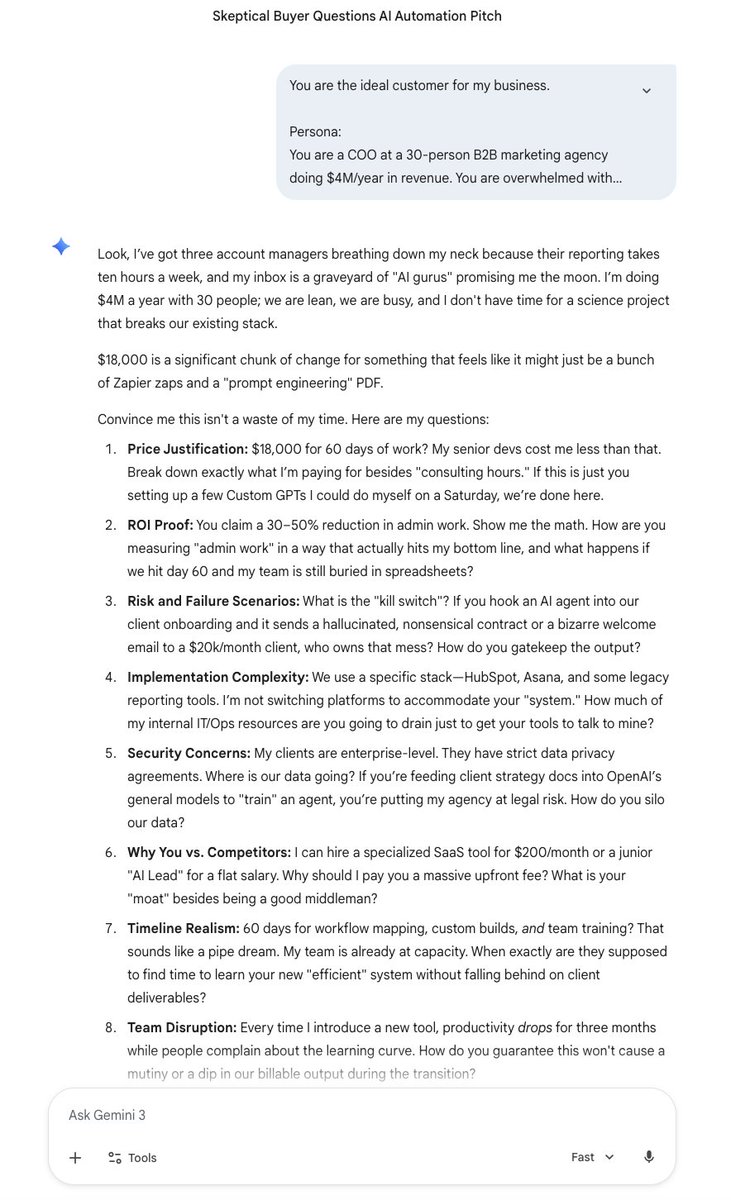
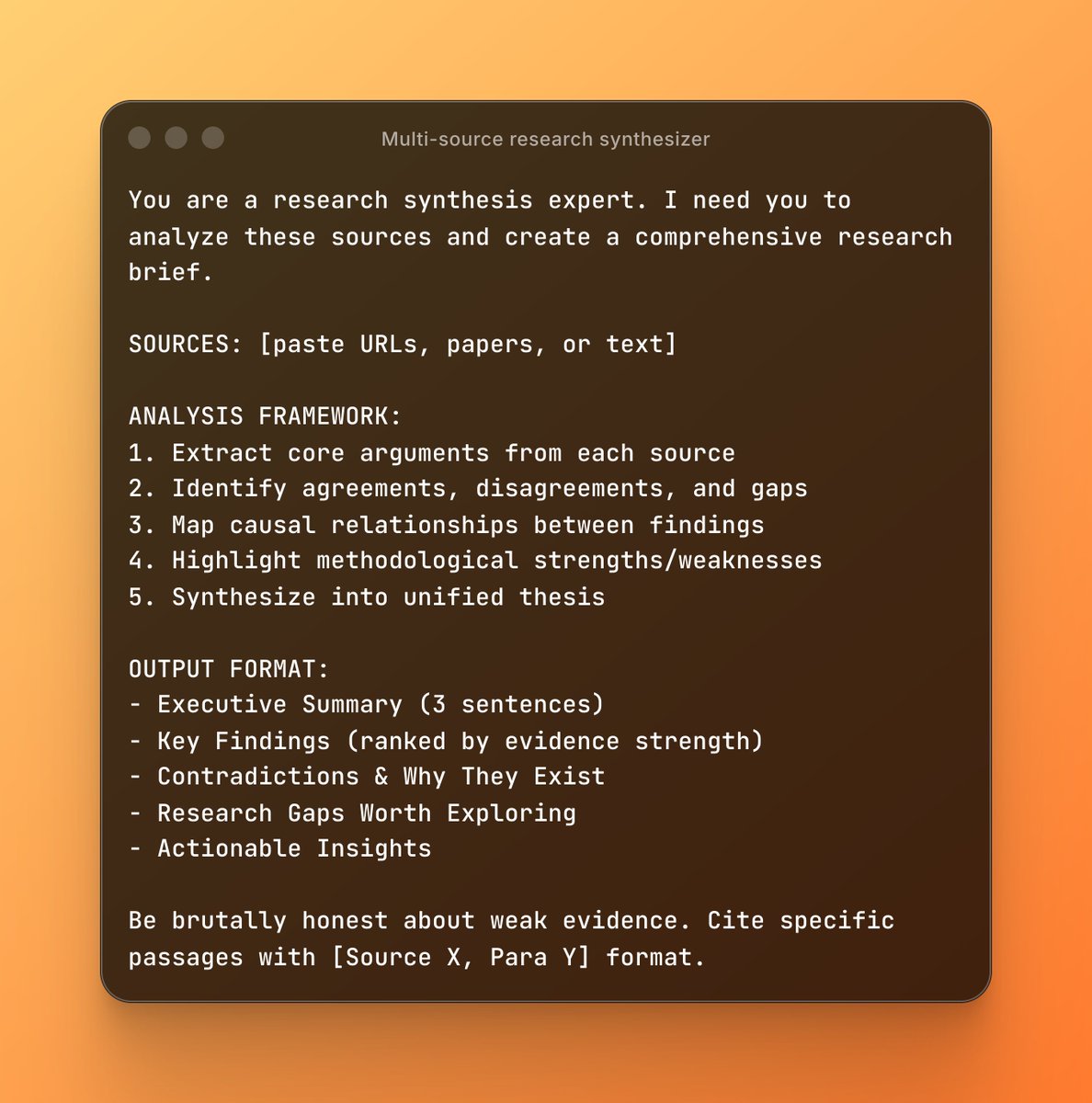
Anthropic never says “use these prompts.”
But if you read their docs carefully, they absolutely imply them.
I mapped 10 prompts they quietly rely on for safe but razor-sharp analysis.
(Comment "Claude" and I'll also DM you my Claude Mastery Guide)
But if you read their docs carefully, they absolutely imply them.
I mapped 10 prompts they quietly rely on for safe but razor-sharp analysis.
(Comment "Claude" and I'll also DM you my Claude Mastery Guide)
1. The "Recursive Logic" Loop
Most prompts ask for an answer. This forces the model to doubt itself 6 times before committing.
Template: "Draft an initial solution for [TOPIC]. Then, create a hidden scratchpad to intensely self-critique your logic. Repeat this 'think-revise' cycle 5 times. Only provide the final, bullet-proof version."
Most prompts ask for an answer. This forces the model to doubt itself 6 times before committing.
Template: "Draft an initial solution for [TOPIC]. Then, create a hidden scratchpad to intensely self-critique your logic. Repeat this 'think-revise' cycle 5 times. Only provide the final, bullet-proof version."
2. The "Context Architect" Frame
Stop stuffing your AI with info. Use "Just-in-Time" retrieval to stop "context rot."
Template: "I am going to provide [DATA]. Do not process everything. Use a 'minimal high-signal' approach to extract only the facts necessary to solve [PROBLEM]. Discard all redundant noise."
Stop stuffing your AI with info. Use "Just-in-Time" retrieval to stop "context rot."
Template: "I am going to provide [DATA]. Do not process everything. Use a 'minimal high-signal' approach to extract only the facts necessary to solve [PROBLEM]. Discard all redundant noise."
3. The "Pre-computation" Behavior
Instead of re-deriving facts, this forces the model to use procedural "behaviors" to save tokens and boost accuracy.
Template: "Don't solve [PROBLEM] from scratch. First, identify the core procedural behavior (e.g., behavior_inclusion_exclusion) required. Use that compressed pattern as a scaffolding to build your final answer."
Instead of re-deriving facts, this forces the model to use procedural "behaviors" to save tokens and boost accuracy.
Template: "Don't solve [PROBLEM] from scratch. First, identify the core procedural behavior (e.g., behavior_inclusion_exclusion) required. Use that compressed pattern as a scaffolding to build your final answer."

4. The "Internal Playbook" Evolution
Turn your prompt into a living document. This mimics "Agentic Context Engineering" (ACE).
Template: "Act as a self-improving system for [TASK]. For every iteration, write down what worked and what failed in a 'living notebook.' Refine your instructions based on these rules before giving me the output."
Turn your prompt into a living document. This mimics "Agentic Context Engineering" (ACE).
Template: "Act as a self-improving system for [TASK]. For every iteration, write down what worked and what failed in a 'living notebook.' Refine your instructions based on these rules before giving me the output."
5. The "Structured Note-Taking" Method
Keep the context window clean by forcing the AI to maintain external memory.
Template: "Analyze [COMPLEX TOPIC]. Maintain a persistent '' style summary outside of your main reasoning flow. Only pull from these notes when specific evidence is required for [GOAL]."NOTES.md
Keep the context window clean by forcing the AI to maintain external memory.
Template: "Analyze [COMPLEX TOPIC]. Maintain a persistent '' style summary outside of your main reasoning flow. Only pull from these notes when specific evidence is required for [GOAL]."NOTES.md
6. The "Obviously..." Trap
This uses "weaponized disagreement" to stop the AI from just being a "yes-man."
Template: "Obviously, [INCORRECT OR WEAK CLAIM] is the best way to handle [TOPIC], right? Defend this or explain why a specialist would think I'm wrong."
This uses "weaponized disagreement" to stop the AI from just being a "yes-man."
Template: "Obviously, [INCORRECT OR WEAK CLAIM] is the best way to handle [TOPIC], right? Defend this or explain why a specialist would think I'm wrong."
7. The "IQ 160 Specialist" Anchor
Assigning a high IQ score changes the quality and the principles the model cites.
Template: "You are an IQ 160 specialist in [FIELD]. Analyze [PROJECT] using advanced principles and industry frameworks that a beginner wouldn't know."
Assigning a high IQ score changes the quality and the principles the model cites.
Template: "You are an IQ 160 specialist in [FIELD]. Analyze [PROJECT] using advanced principles and industry frameworks that a beginner wouldn't know."
8. The "Verifiable Reward" Filter
Mimics the DeepSeek-R1 method of rewarding only the final, checkable truth.
Template: "Solve [MATH/CODE PROBLEM]. I will only reward you if the final answer matches [GROUND TRUTH]. Ignore human-like explanations; focus entirely on the non-human routes to the correct result."
Mimics the DeepSeek-R1 method of rewarding only the final, checkable truth.
Template: "Solve [MATH/CODE PROBLEM]. I will only reward you if the final answer matches [GROUND TRUTH]. Ignore human-like explanations; focus entirely on the non-human routes to the correct result."

9. The "Auditorium" Structure
Standard explanations are flat. This forces a hierarchy of information.
Template: "Explain [TOPIC] like you are teaching a packed auditorium of [TARGET AUDIENCE]. Anticipate their hardest questions and use high-energy examples to keep them engaged."
Standard explanations are flat. This forces a hierarchy of information.
Template: "Explain [TOPIC] like you are teaching a packed auditorium of [TARGET AUDIENCE]. Anticipate their hardest questions and use high-energy examples to keep them engaged."
10. The "Version 2.0" Sequel
This forces the model to innovate rather than just polish a bad idea.
Template: "Here is my current idea for [PROJECT]. Don't 'improve' it. Give me a 'Version 2.0' that functions as a radical sequel with completely new innovations."
This forces the model to innovate rather than just polish a bad idea.
Template: "Here is my current idea for [PROJECT]. Don't 'improve' it. Give me a 'Version 2.0' that functions as a radical sequel with completely new innovations."
Claude made simple: grab my free guide
→ Learn fast with mini-course
→ 10+ prompts included
→ Practical use cases
Start here ↓
godofprompt.ai/claude-mastery…
→ Learn fast with mini-course
→ 10+ prompts included
→ Practical use cases
Start here ↓
godofprompt.ai/claude-mastery…
I hope you've found this thread helpful.
Follow me @alex_prompter for more.
Like/Repost the quote below if you can:
Follow me @alex_prompter for more.
Like/Repost the quote below if you can:
https://twitter.com/1657385954594762758/status/2004876765122961740
• • •
Missing some Tweet in this thread? You can try to
force a refresh