Introducing GLM-OCR: SOTA performance, optimized for complex document understanding.
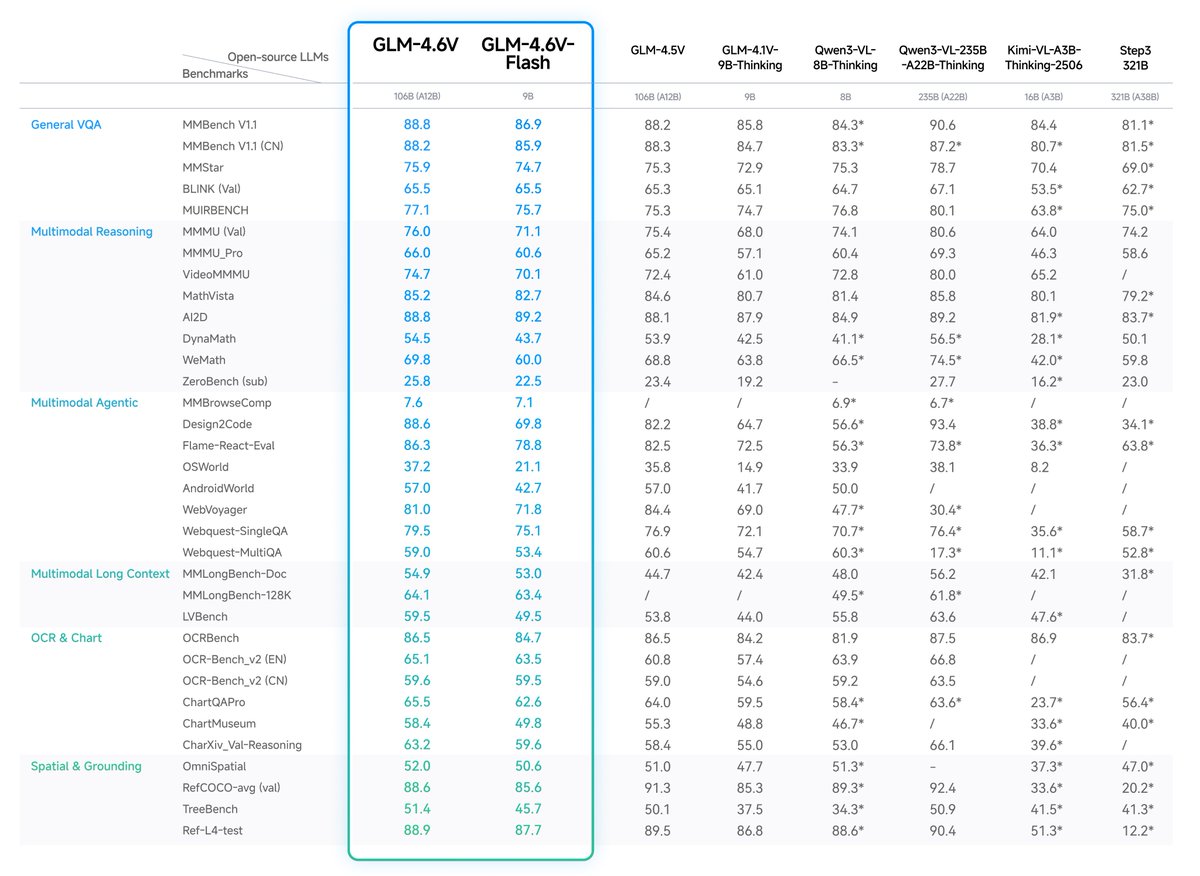
With only 0.9B parameters, GLM-OCR delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction.
Weights: huggingface.co/zai-org/GLM-OCR
Try it: ocr.z.ai
API: docs.z.ai/guides/vlm/glm…
With only 0.9B parameters, GLM-OCR delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction.
Weights: huggingface.co/zai-org/GLM-OCR
Try it: ocr.z.ai
API: docs.z.ai/guides/vlm/glm…
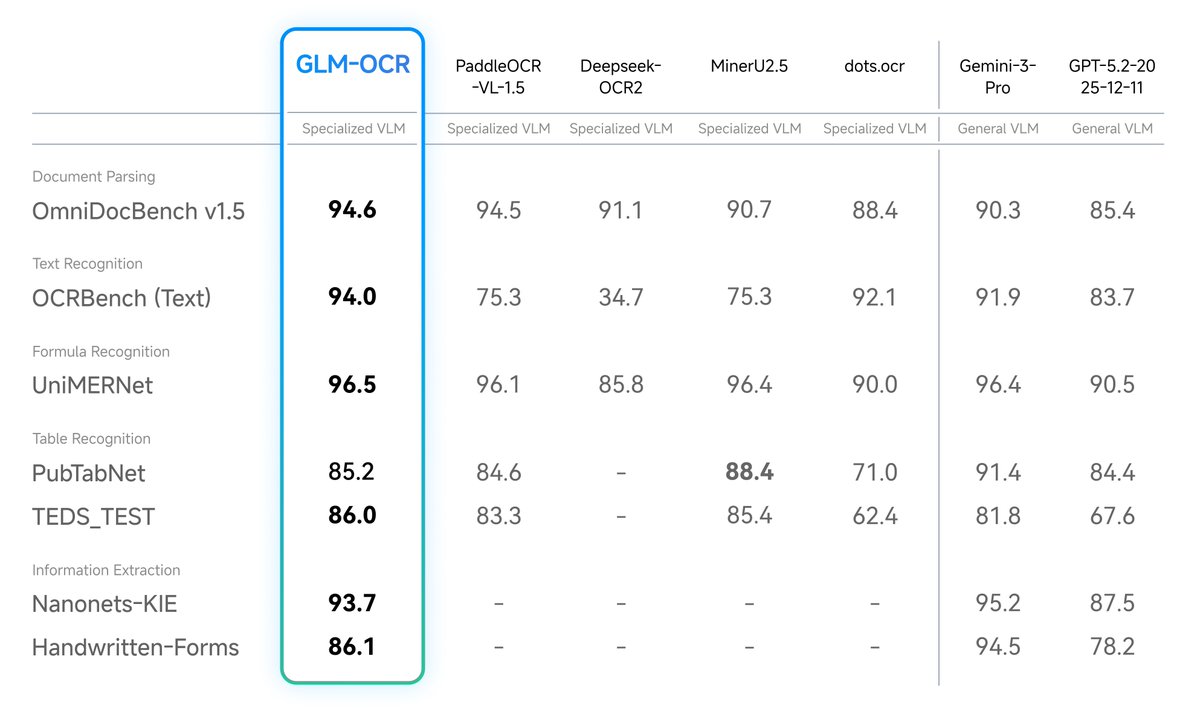
Optimized for real-world scenarios: It handles complex tables, code-heavy docs, official seals, and other challenging elements where traditional OCR fails.
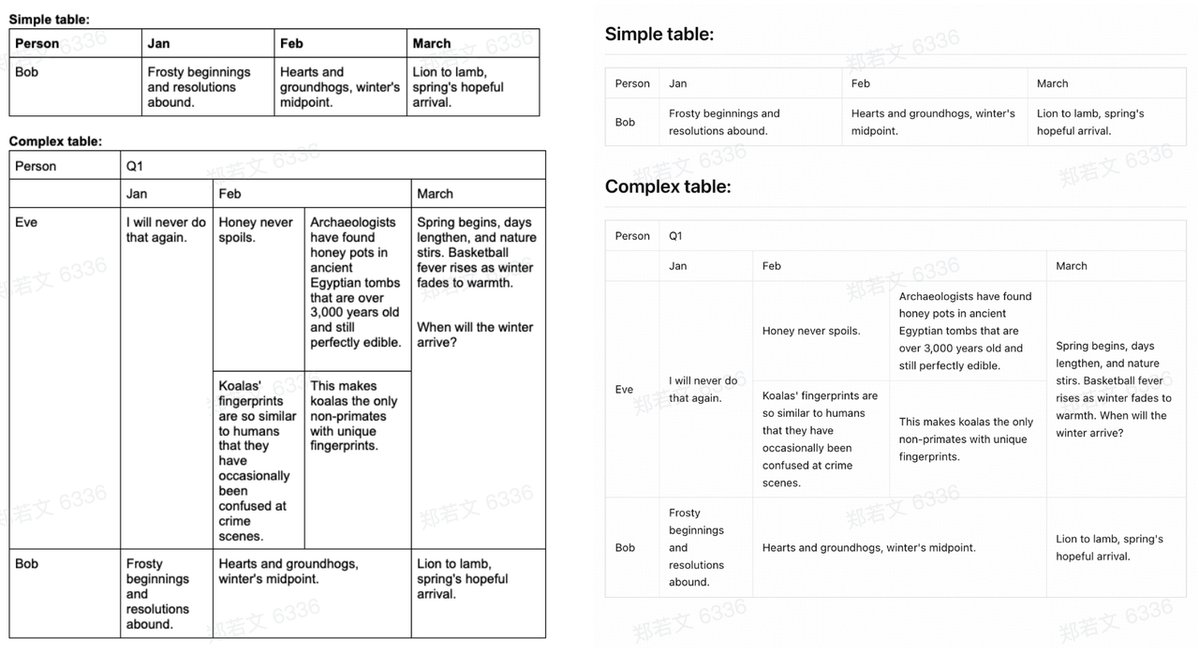
The model integrates the CogViT visual encoder pre-trained on large-scale image–text data, a lightweight cross-modal connector with efficient token downsampling, and a GLM-0.5B language decoder. Combined with a two-stage pipeline of layout analysis and parallel recognition based on PP-DocLayout-V3, GLM-OCR delivers robust and high-quality OCR performance across diverse document layouts.
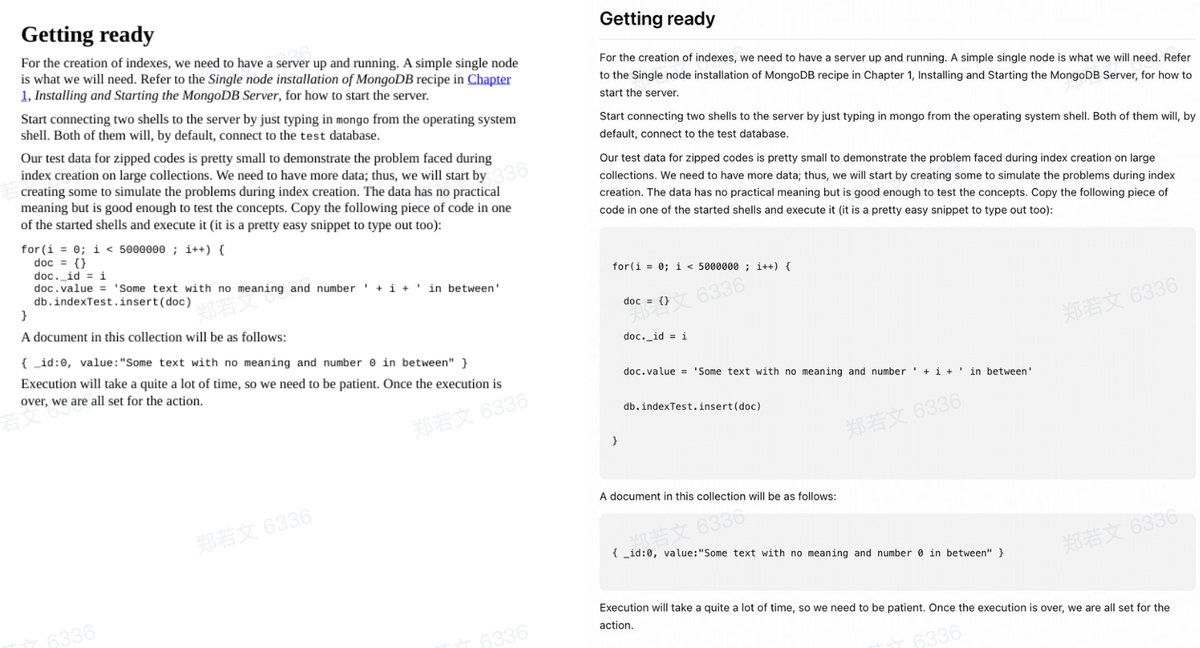
GLM-OCR achieves a throughput of 1.86 pages/second for PDF documents and 0.67 images/second for images, significantly outperforming comparable models.

• • •
Missing some Tweet in this thread? You can try to
force a refresh