 GLM-5.2 leads GLM-5.1 by a wide margin across various domains, including coding, tool usage, reasoning, and general knowledge.
GLM-5.2 leads GLM-5.1 by a wide margin across various domains, including coding, tool usage, reasoning, and general knowledge. 
 SOTA on SWE-Bench Pro (58.4): GLM-5.1 delivers significant leaps in coding and agentic performance.
SOTA on SWE-Bench Pro (58.4): GLM-5.1 delivers significant leaps in coding and agentic performance. 
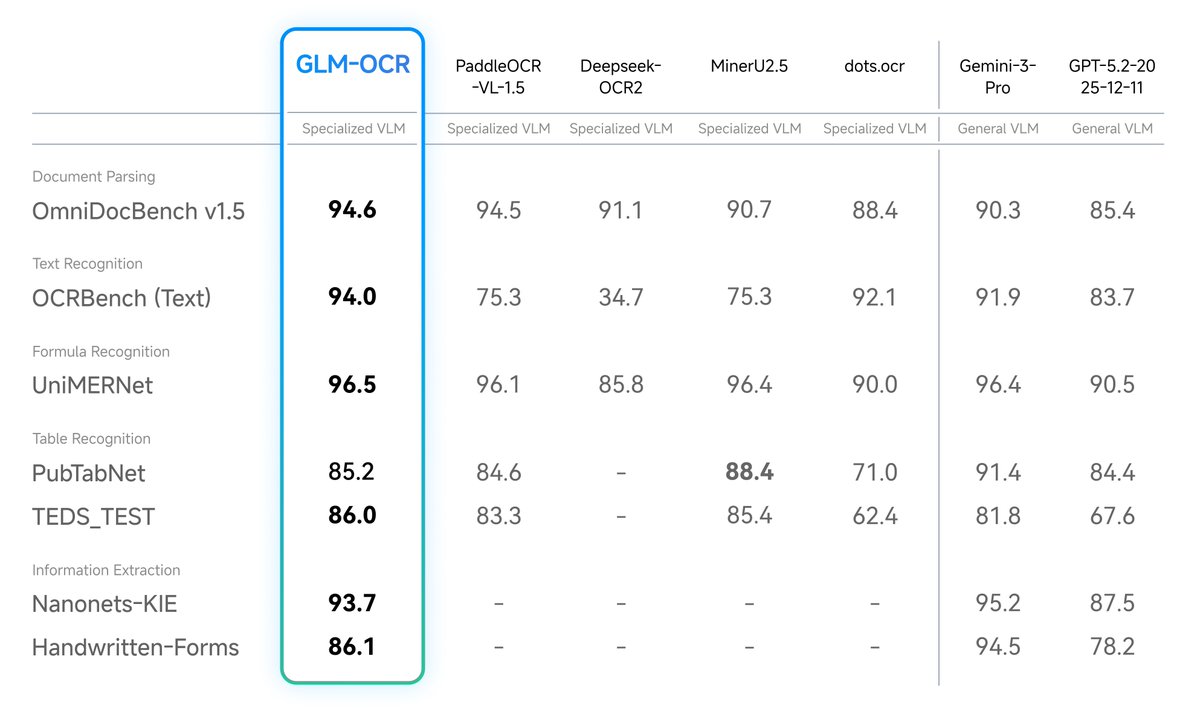 Optimized for real-world scenarios: It handles complex tables, code-heavy docs, official seals, and other challenging elements where traditional OCR fails.
Optimized for real-world scenarios: It handles complex tables, code-heavy docs, official seals, and other challenging elements where traditional OCR fails. 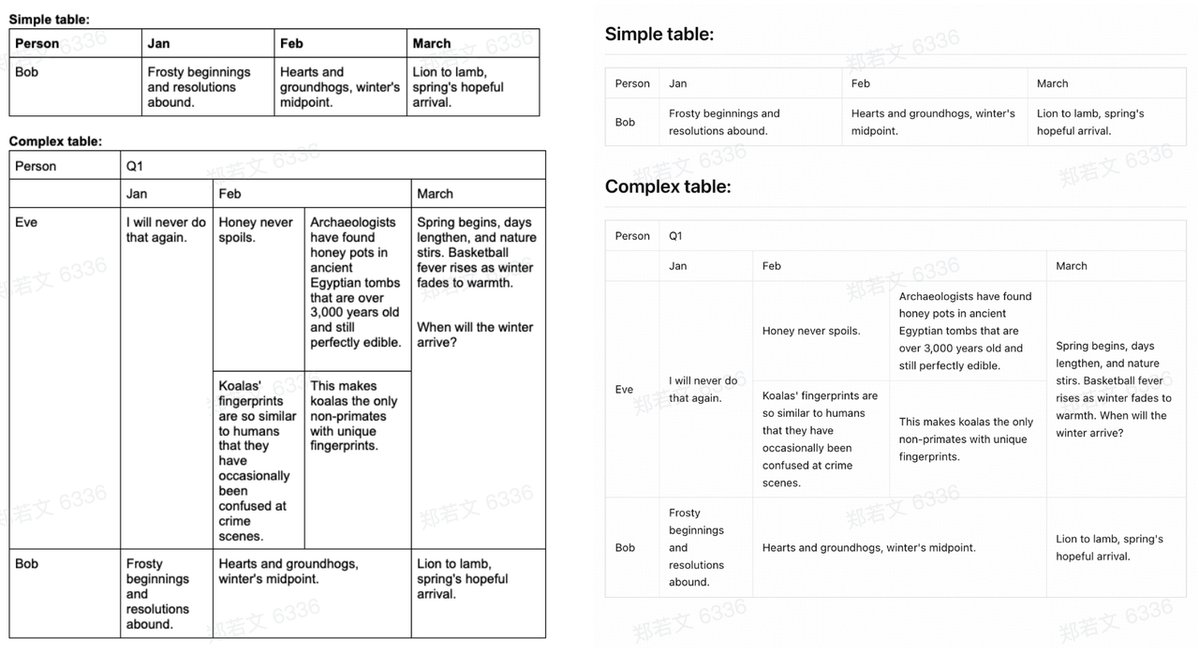
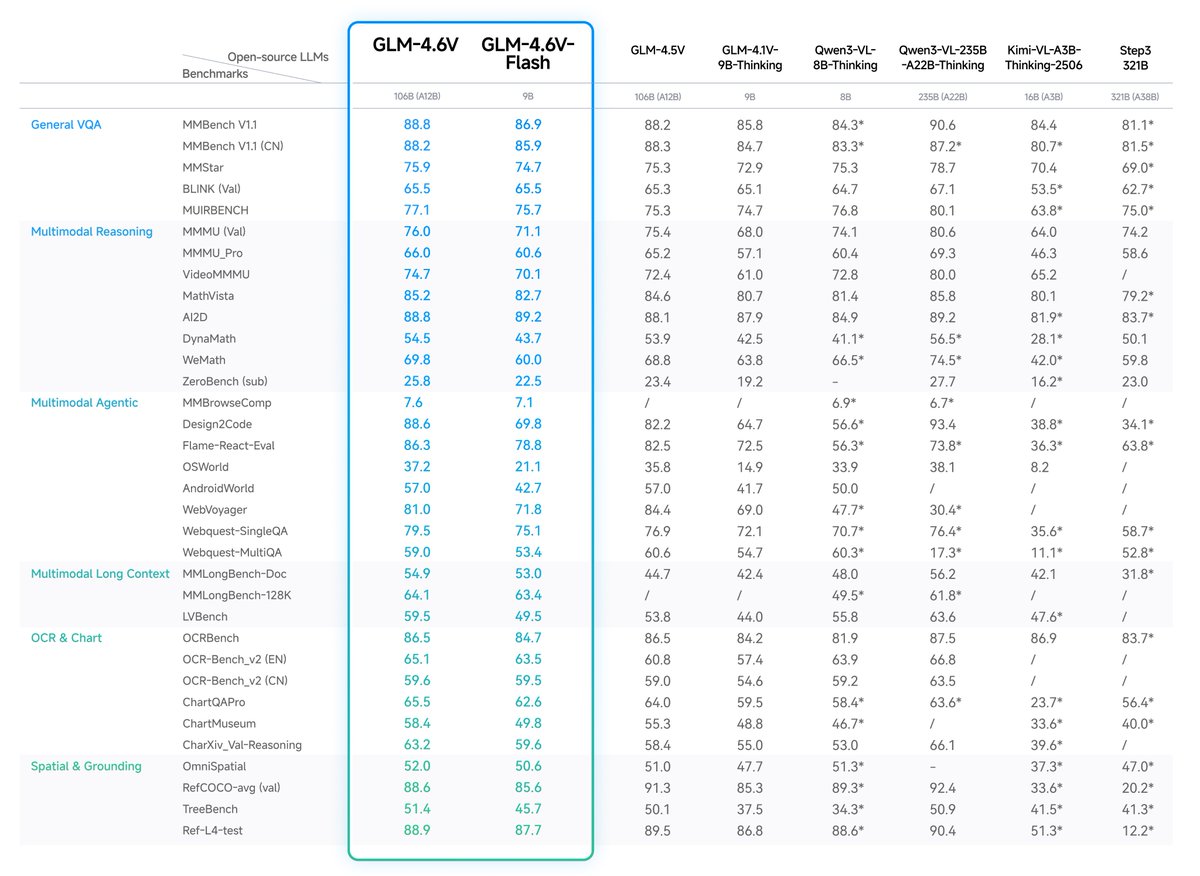 GLM-4.6V can accept multimodal inputs of various types and automatically generate high-quality, structured image-text interleaved content.
GLM-4.6V can accept multimodal inputs of various types and automatically generate high-quality, structured image-text interleaved content.
 Through efficient hybrid training, GLM-4.5V is equipped to handle diverse types of visual content, achieving comprehensive visual reasoning across all scenarios, including:
Through efficient hybrid training, GLM-4.5V is equipped to handle diverse types of visual content, achieving comprehensive visual reasoning across all scenarios, including: