Introducing Lab: A full-stack platform for training your own agentic models
Build, evaluate and train on your own environments at scale without managing the underlying infrastructure.
Giving everyone their own frontier AI lab.
Build, evaluate and train on your own environments at scale without managing the underlying infrastructure.
Giving everyone their own frontier AI lab.
We are not inspired by a future where a few labs control the intelligence layer
So we built a platform to give everyone access to the tools of the frontier lab
If you are an AI company, you can now be your own AI lab
If you are an AI engineer, you can now be an AI researcher
So we built a platform to give everyone access to the tools of the frontier lab
If you are an AI company, you can now be your own AI lab
If you are an AI engineer, you can now be an AI researcher
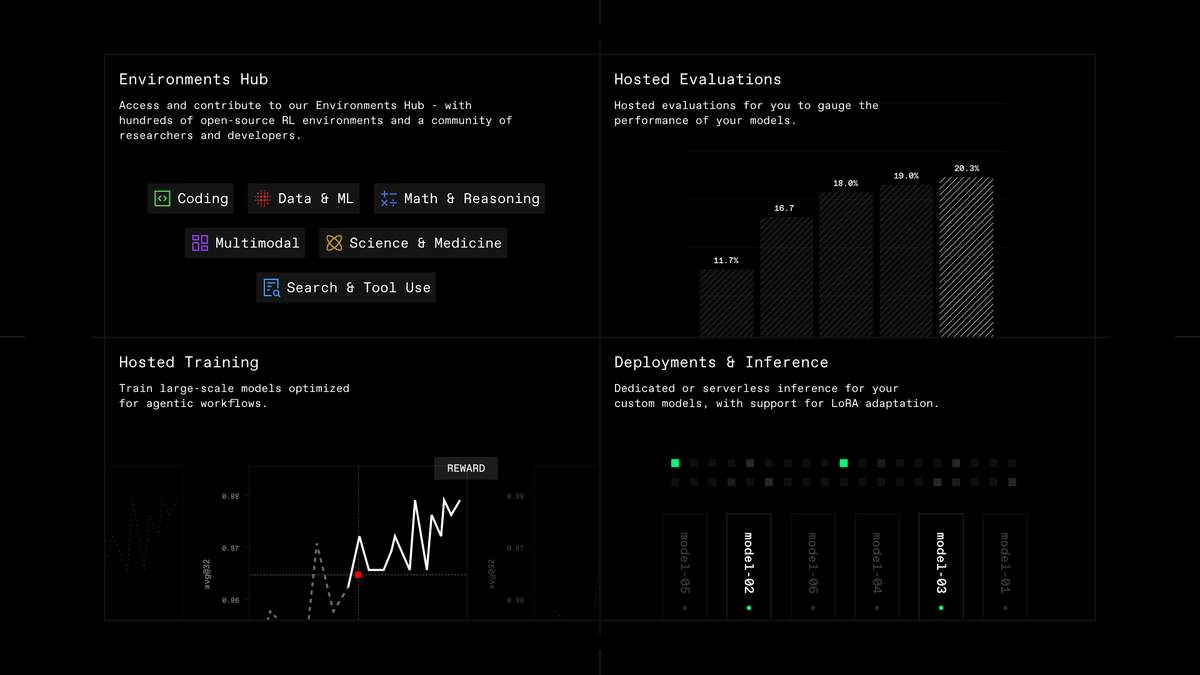
Lab unifies everything you need for post-training research into one platform
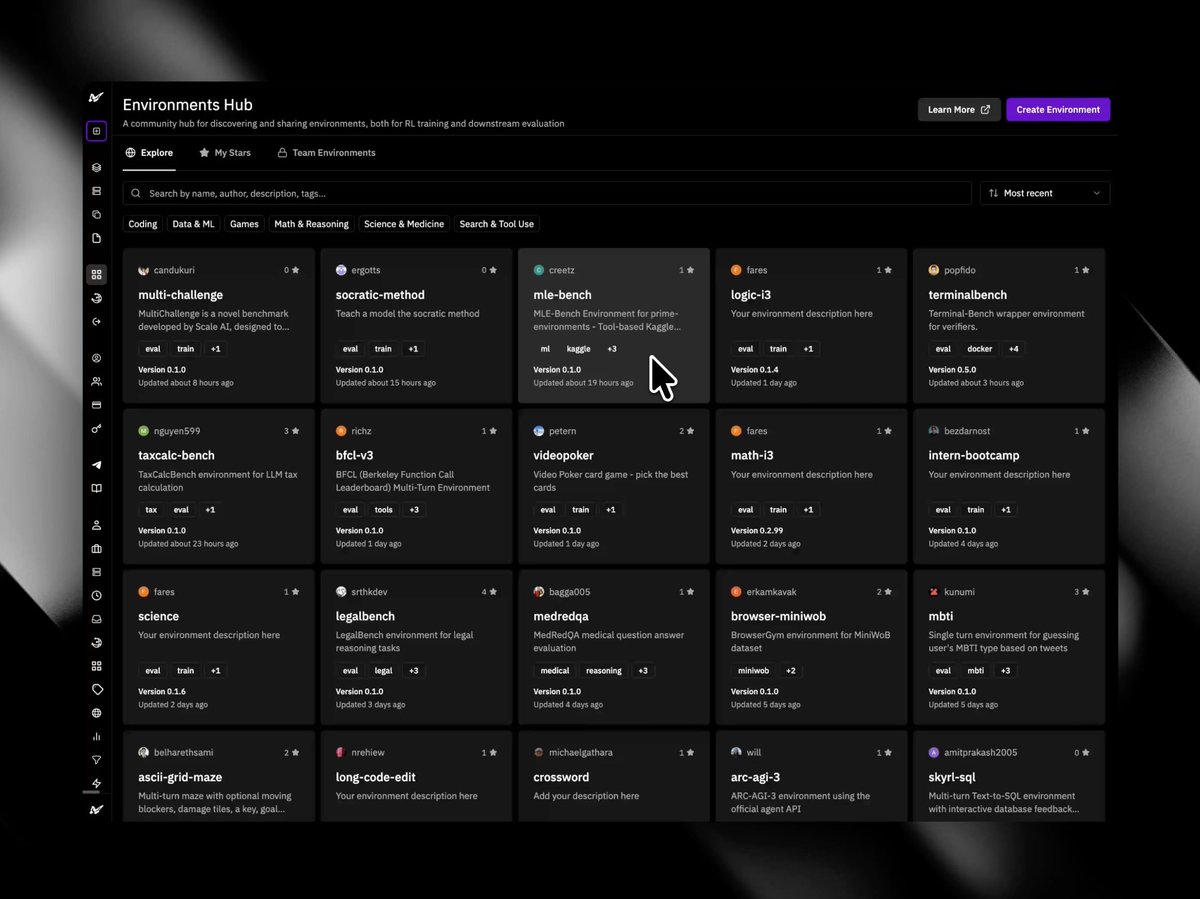
+ Environments Hub
+ Hosted Evaluations
+ Hosted Training
+ Deployments & Inference
Without needing to worry about the costs of massive GPU clusters or the headaches of low-level algorithm details
+ Environments Hub
+ Hosted Evaluations
+ Hosted Training
+ Deployments & Inference
Without needing to worry about the costs of massive GPU clusters or the headaches of low-level algorithm details
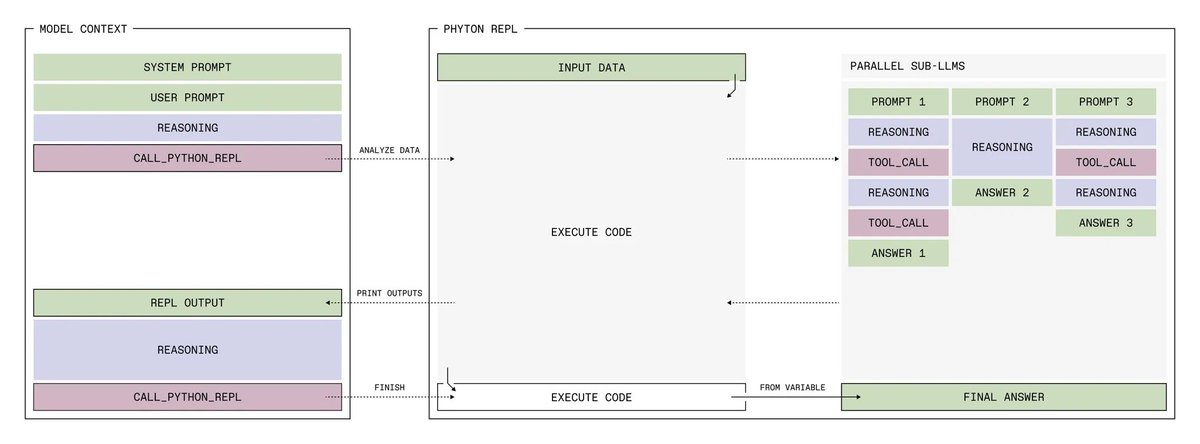
Lab is built around environments, which include:
+ A dataset of tasks
+ A harness for the model
+ A rubric to score performance
Use environments to train models with RL, evaluate capabilities, generate synthetic data, optimize prompts, experiment with agent harnesses and more.
+ A dataset of tasks
+ A harness for the model
+ A rubric to score performance
Use environments to train models with RL, evaluate capabilities, generate synthetic data, optimize prompts, experiment with agent harnesses and more.
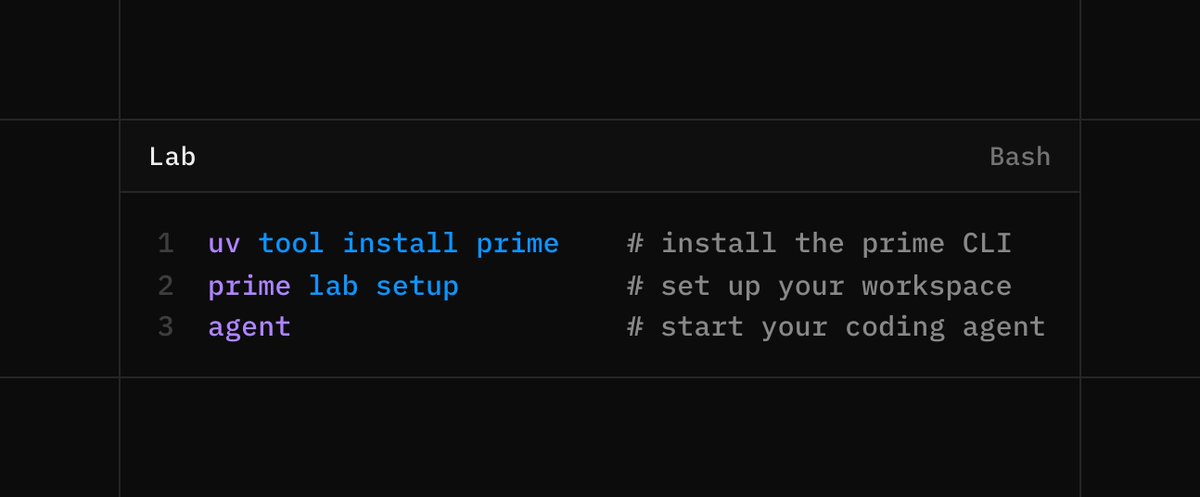
Just run `prime lab setup` and start your coding agent to set up your own AI lab.
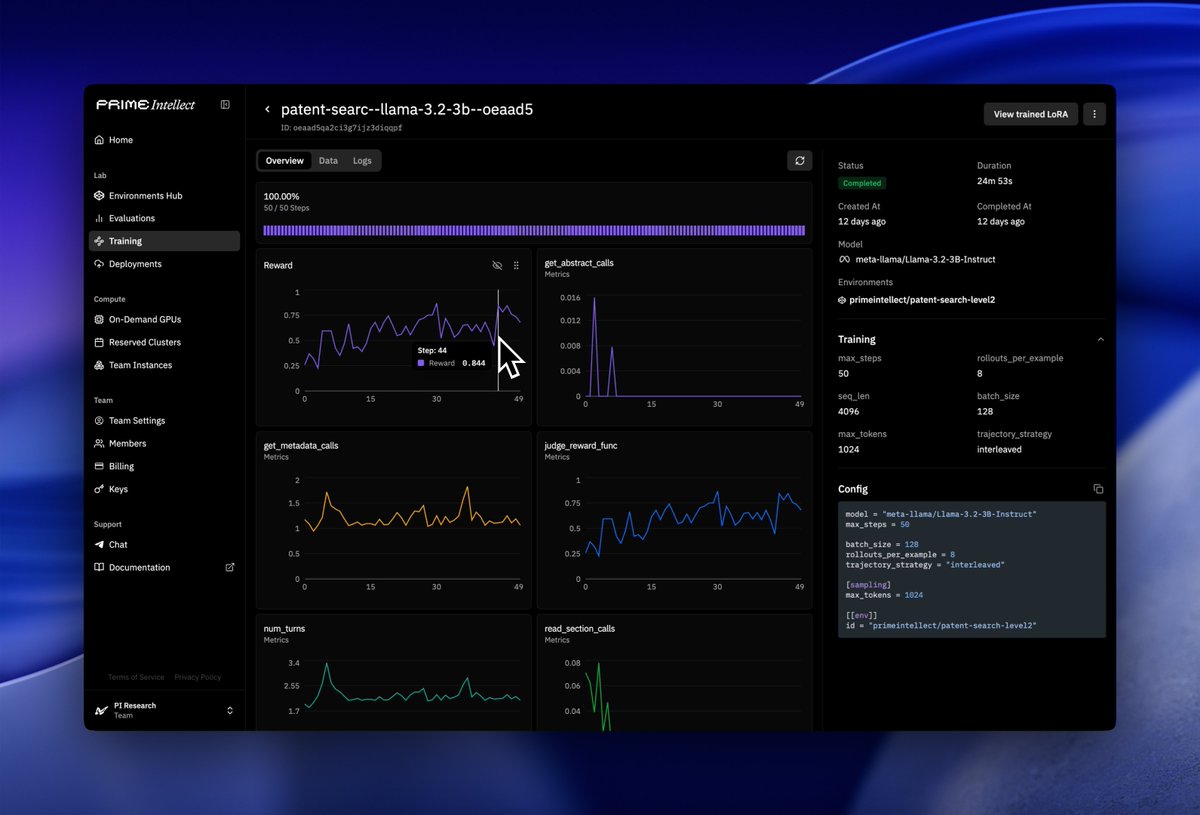
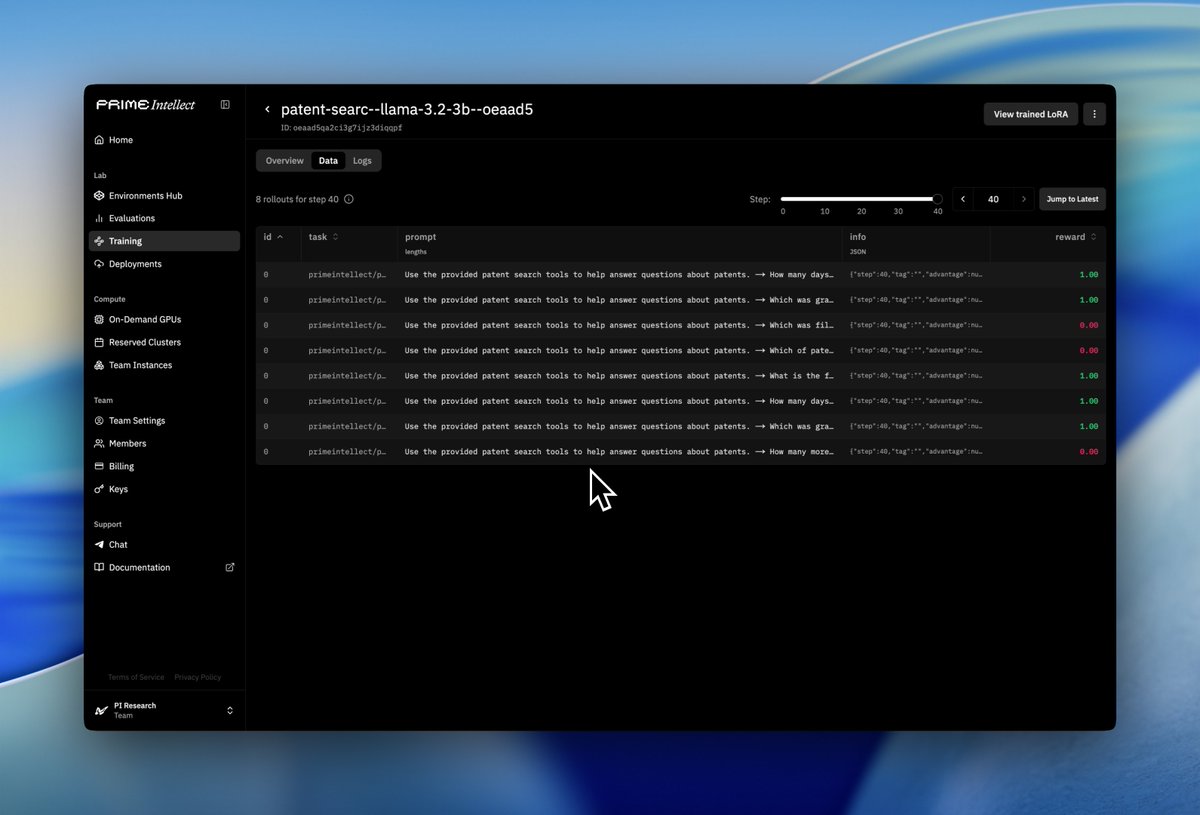
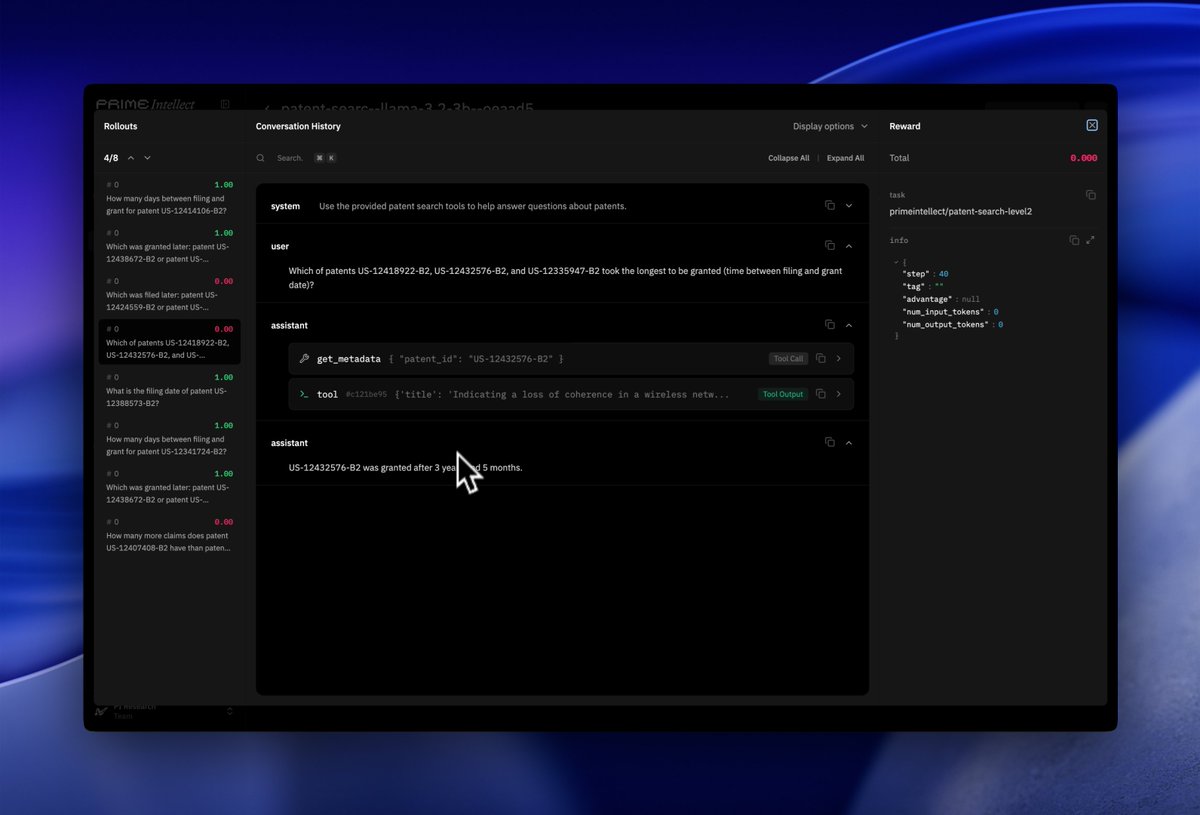
Hosted Training
Create your environment, configure your training run, and we handle the rest.
No worrying about managing infrastructure, GPUs, or low-level algorithms.
We’re launching with agentic RL, and adding support for SFT and other algorithms in the near future.
Create your environment, configure your training run, and we handle the rest.
No worrying about managing infrastructure, GPUs, or low-level algorithms.
We’re launching with agentic RL, and adding support for SFT and other algorithms in the near future.
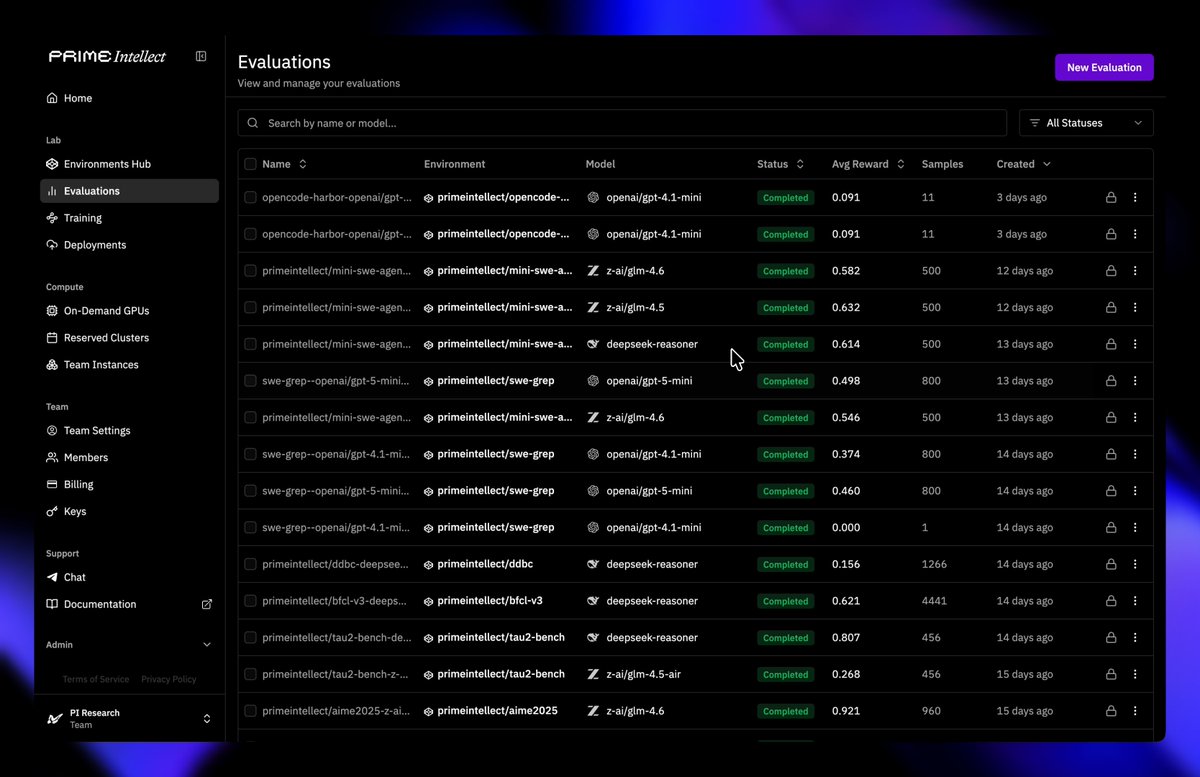
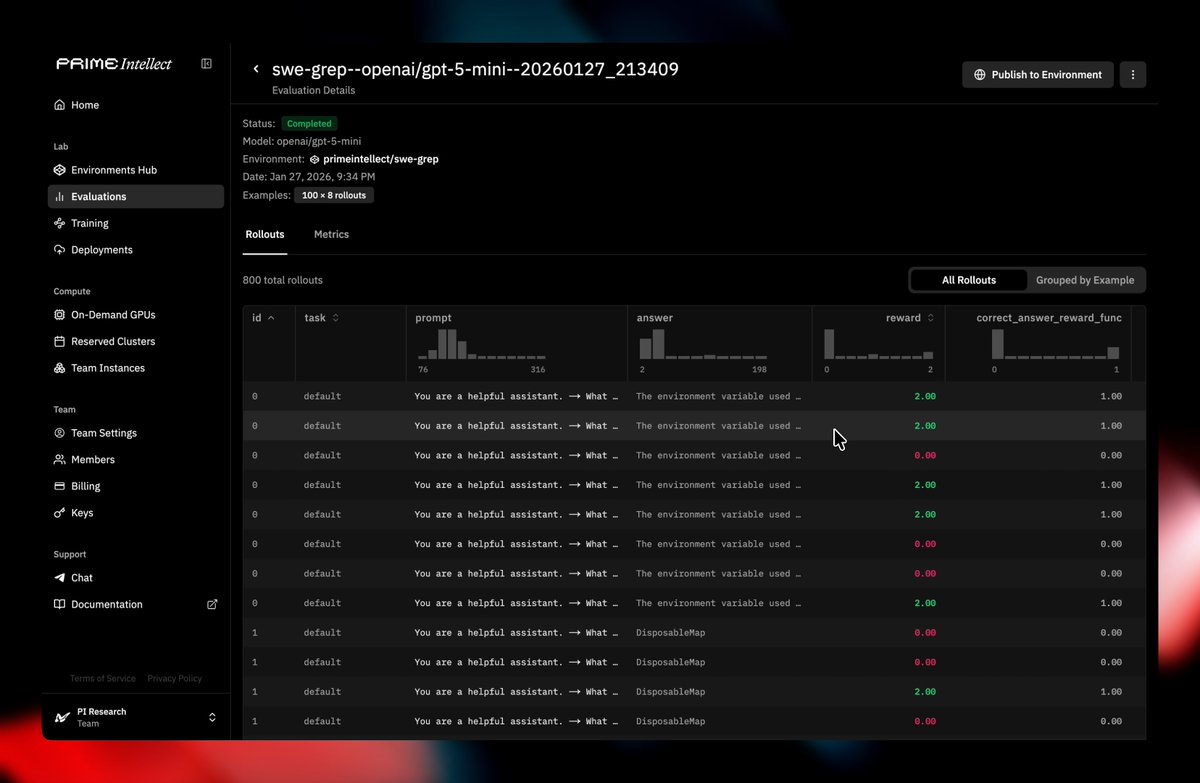
Hosted Evaluations
+ Run evals using our hosted inference, sandboxes, and more
+ Visualize results and raw outputs
+ Share results on the Environments Hub
+ Run evals using our hosted inference, sandboxes, and more
+ Visualize results and raw outputs
+ Share results on the Environments Hub
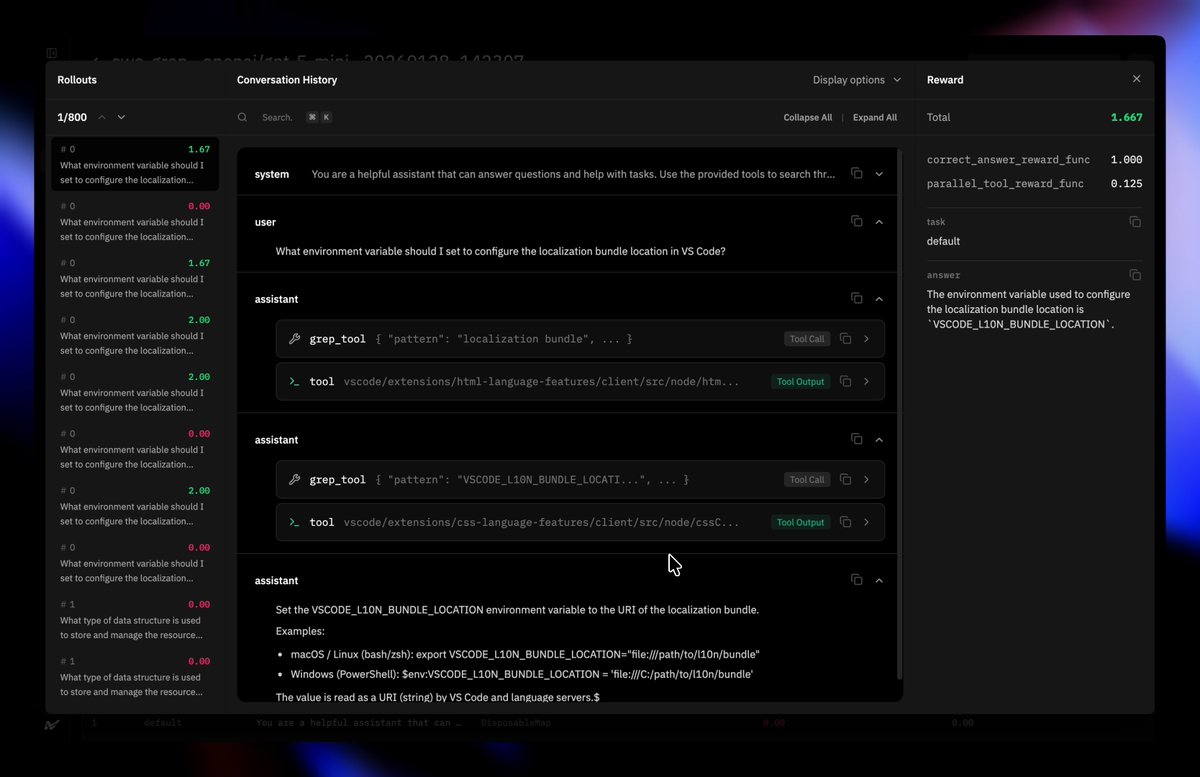
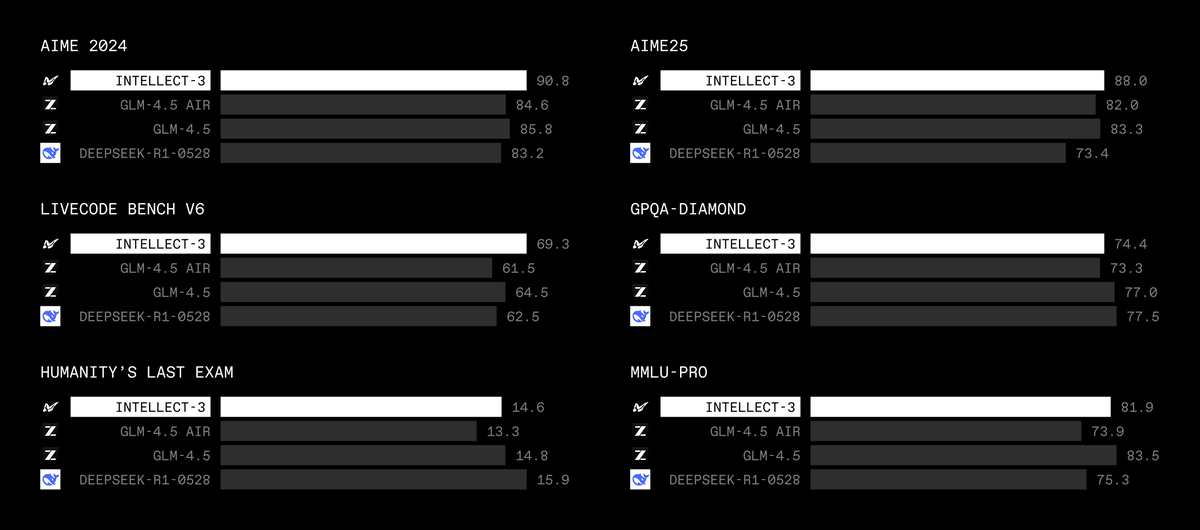
Beyond our own INTELLECT-3 model, Lab lets you run reinforcement learning on a wide range of open models.
From Nvidia, Arcee, Hugging Face, Allen AI, Z AI, Qwen, and many more launching soon.
We’re also launching with experimental multimodality support.
From Nvidia, Arcee, Hugging Face, Allen AI, Z AI, Qwen, and many more launching soon.
We’re also launching with experimental multimodality support.
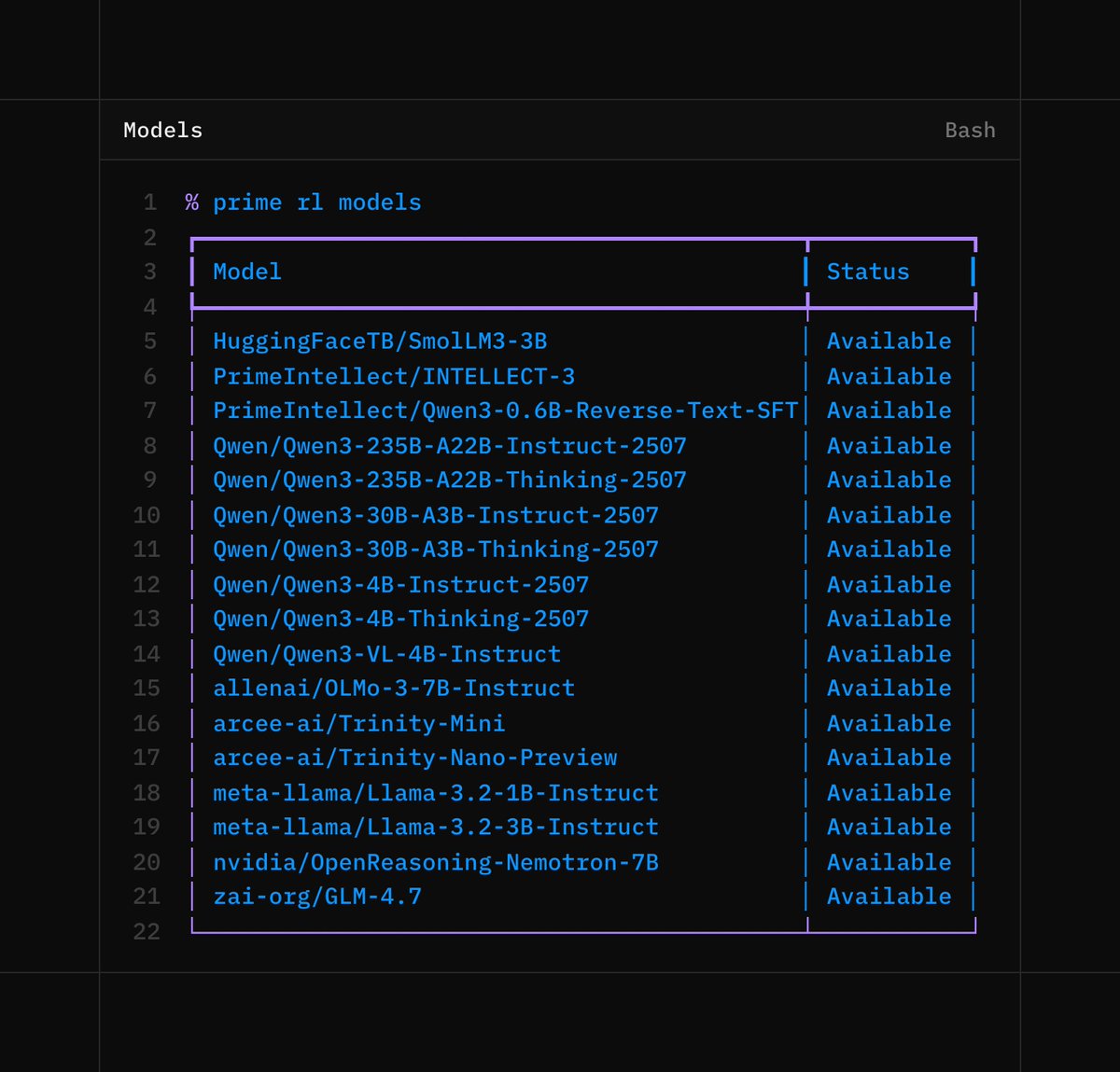
Deployments & Inference
Large-scale production deployments of your fine-tuned models on shared hardware
Built to evolve towards a future of continual learning, where models learn in production as training and inference collapse into a single loop.
Large-scale production deployments of your fine-tuned models on shared hardware
Built to evolve towards a future of continual learning, where models learn in production as training and inference collapse into a single loop.
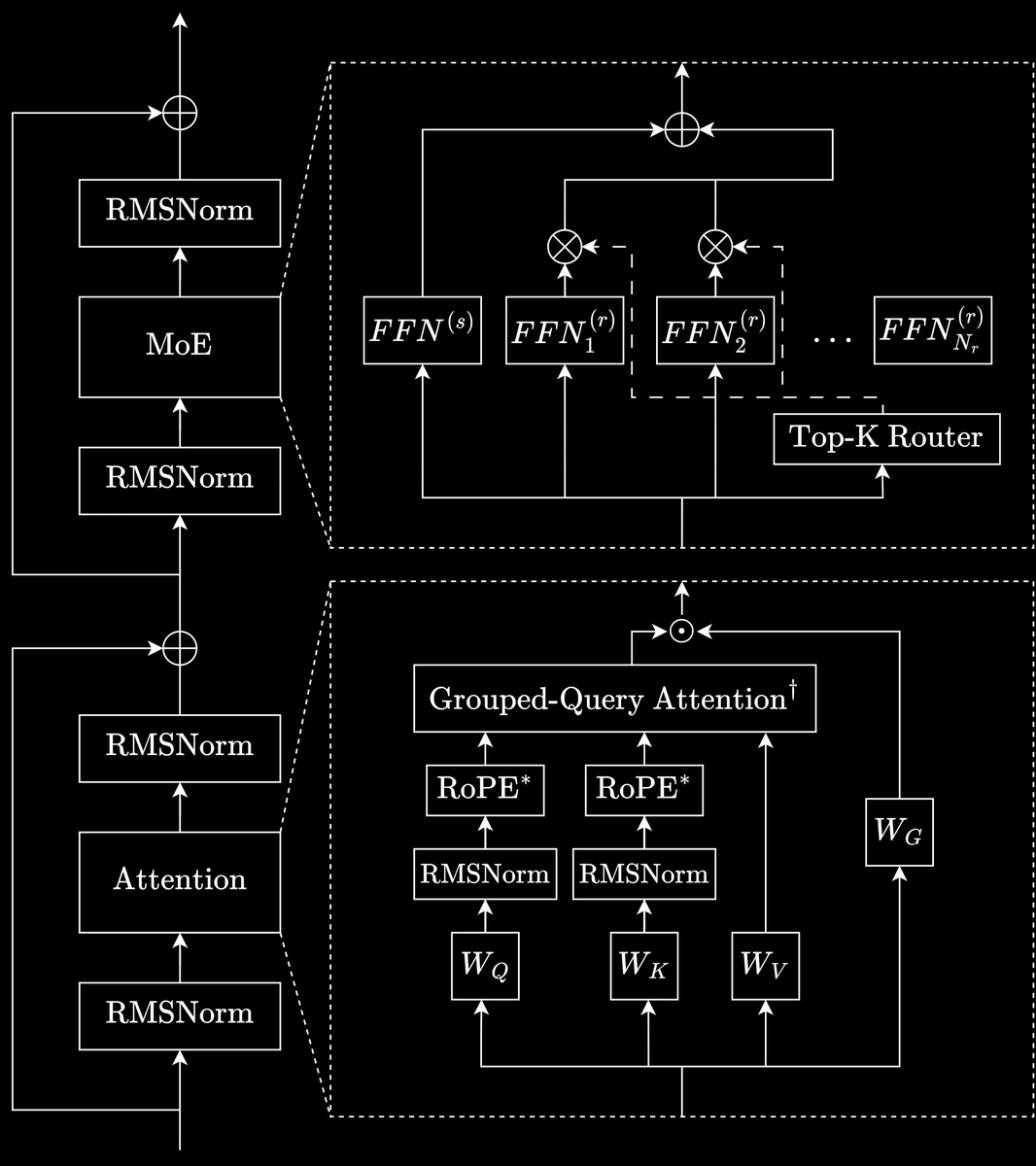
Infrastructure
Lab is built on the same stack we used to train INTELLECT-3.
Each run gets a dedicated orchestrator, with multi-tenant LoRA for training and inference.
Enabling shared hardware across runs, high efficiency, per-token pricing.
Lab is built on the same stack we used to train INTELLECT-3.
Each run gets a dedicated orchestrator, with multi-tenant LoRA for training and inference.
Enabling shared hardware across runs, high efficiency, per-token pricing.
https://x.com/PrimeIntellect/status/1993895068290388134?s=20
Over the past few weeks in private beta, more than 3,000 RL runs were completed by individuals and companies from around the world.
Starting today, we’re opening it up to everyone.
Starting today, we’re opening it up to everyone.
• • •
Missing some Tweet in this thread? You can try to
force a refresh