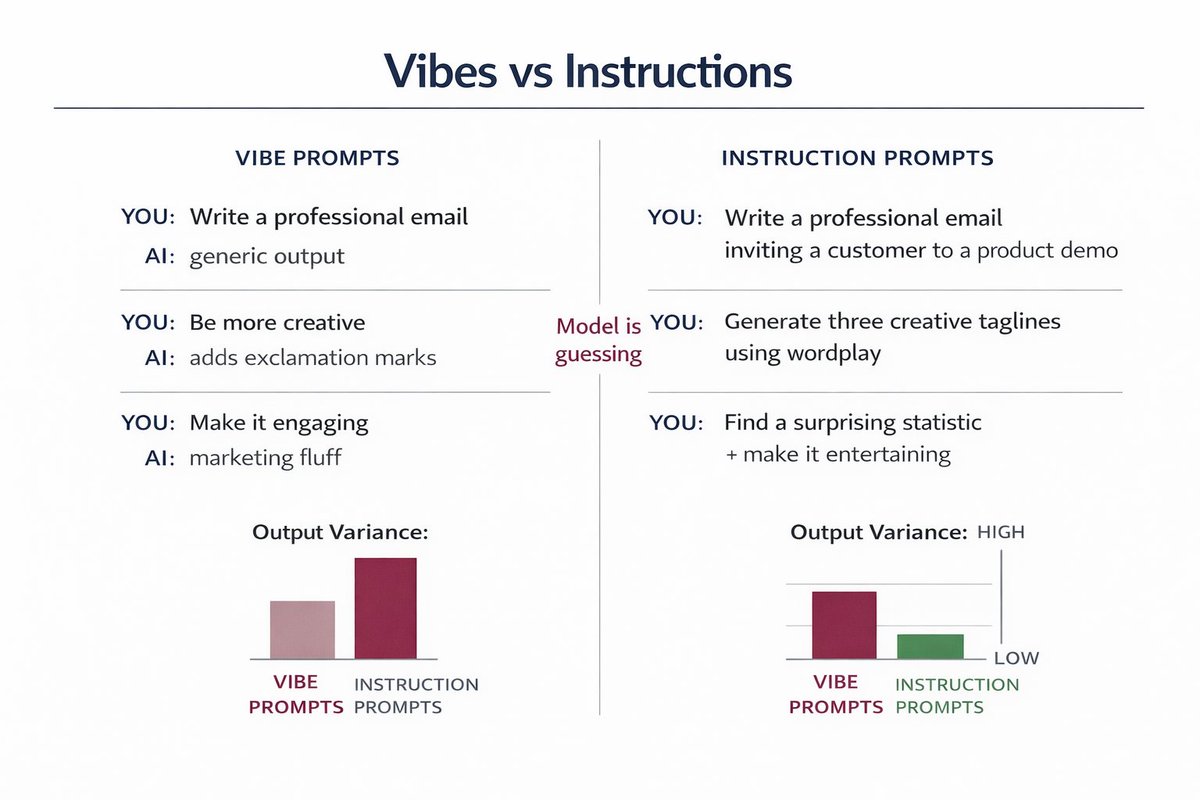
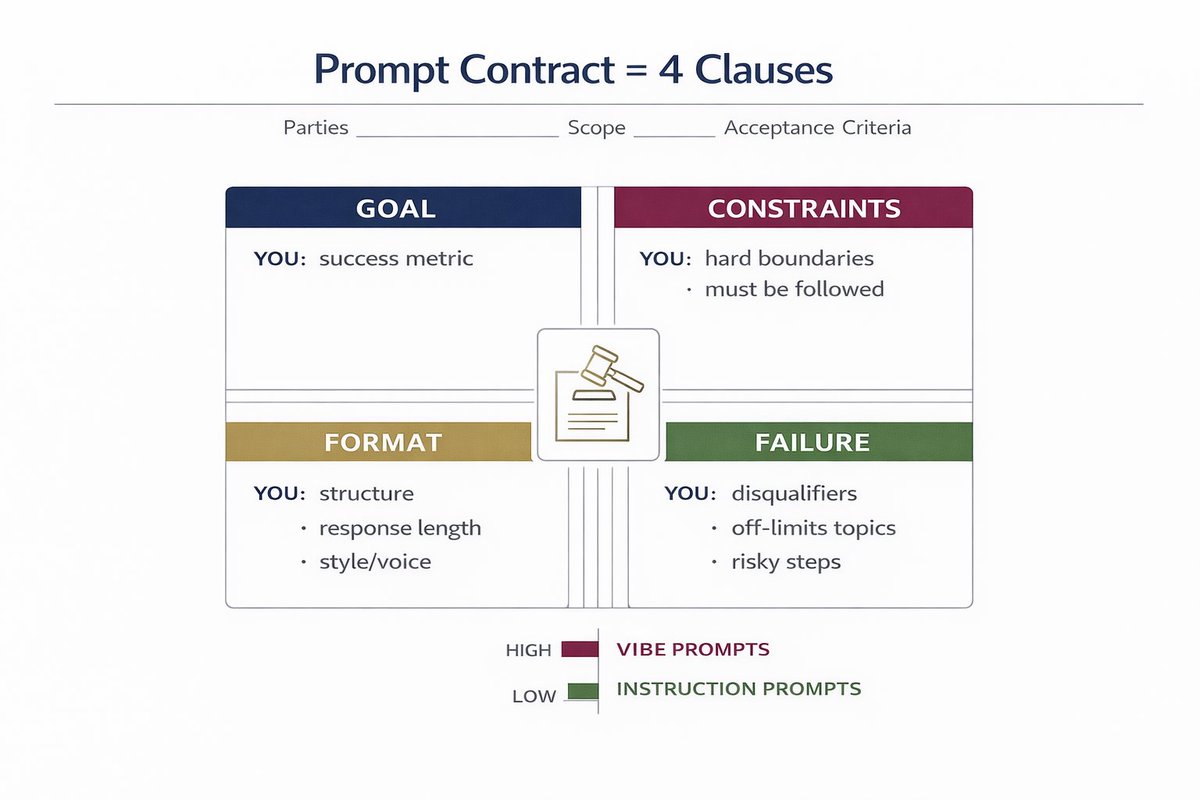
After interviewing 12 AI researchers from OpenAI, Anthropic, and Google, I noticed they all use the same 10 prompts.
Not the ones you see on X and LinkedIn.
These are the prompts that actually ship products, publish papers, and break benchmarks.
Here's what they told me ↓
Not the ones you see on X and LinkedIn.
These are the prompts that actually ship products, publish papers, and break benchmarks.
Here's what they told me ↓

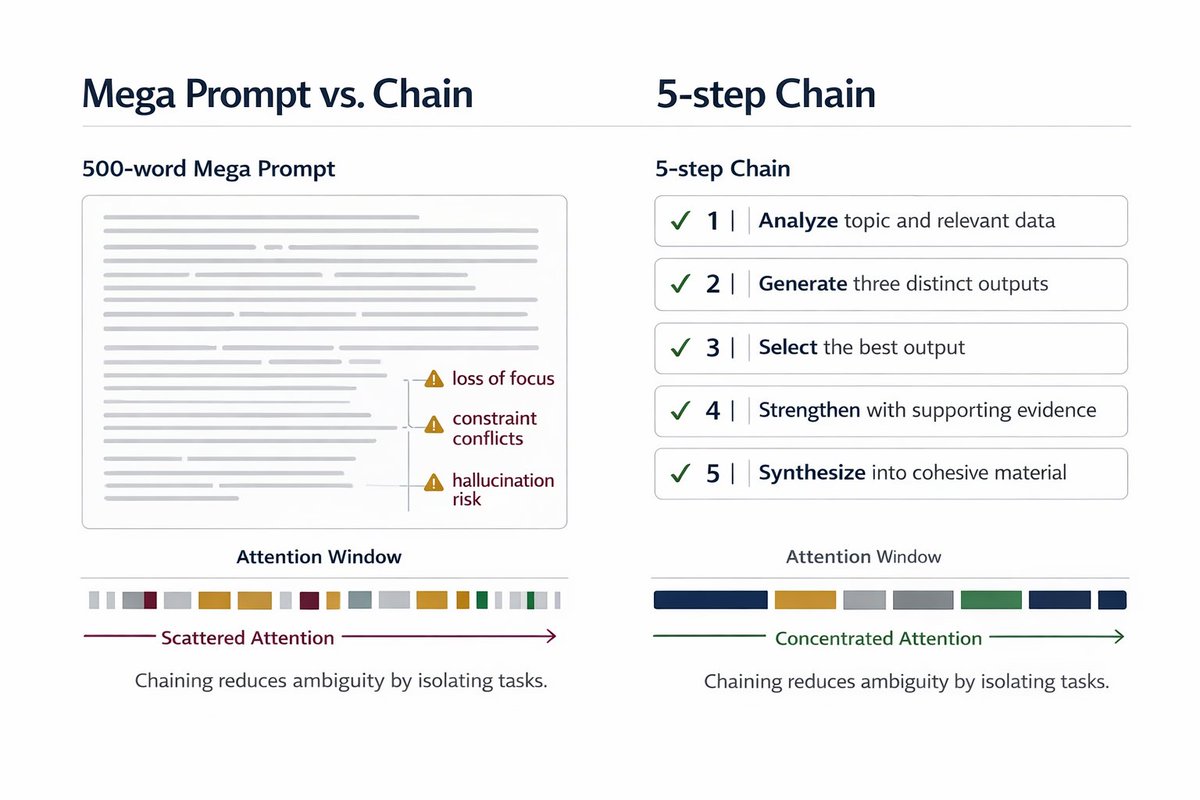
1. The "Show Your Work" Prompt
"Walk me through your reasoning step-by-step before giving the final answer."
This prompt forces the model to externalize its logic. Catches errors before they compound.
"Walk me through your reasoning step-by-step before giving the final answer."
This prompt forces the model to externalize its logic. Catches errors before they compound.
2. The "Adversarial Interrogation"
"Now argue against your previous answer. What are the 3 strongest counterarguments?"
Models are overconfident by default. This forces intellectual honesty.
"Now argue against your previous answer. What are the 3 strongest counterarguments?"
Models are overconfident by default. This forces intellectual honesty.
3. The "Constraint Forcing" Prompt
"You have exactly 3 sentences and must cite 2 specific sources. No hedging language."
Vagueness is the enemy of useful output. Hard constraints = crisp results.
"You have exactly 3 sentences and must cite 2 specific sources. No hedging language."
Vagueness is the enemy of useful output. Hard constraints = crisp results.
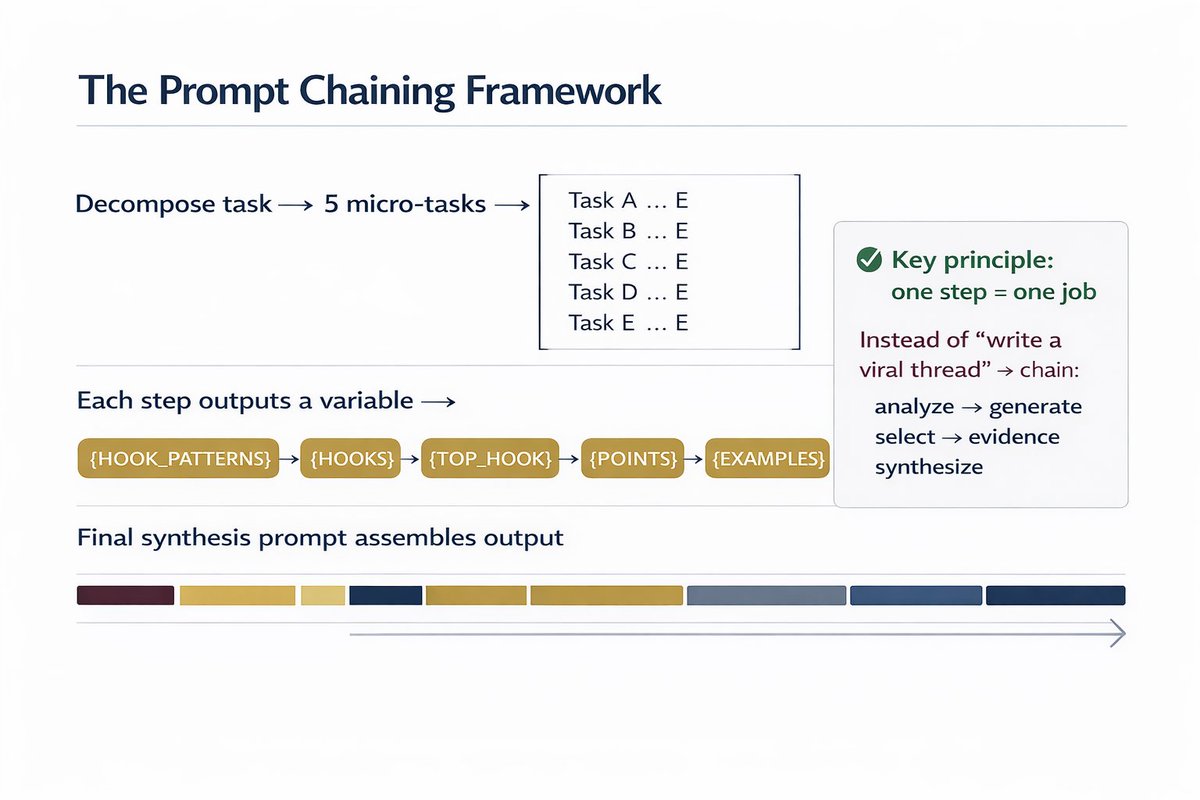
4. The "Format Lock"
"Respond in valid JSON with these exact keys: {analysis, confidence_score, methodology, limitations}."
Structured output = parseable output. You can't build systems on prose.
"Respond in valid JSON with these exact keys: {analysis, confidence_score, methodology, limitations}."
Structured output = parseable output. You can't build systems on prose.
5. The "Expertise Assignment"
"You are a [specific role] with 15 years experience in [narrow domain]. You would never say [common mistake]. You always [specific habit]."
Generic AI = generic output. Specific persona = specific expertise.
"You are a [specific role] with 15 years experience in [narrow domain]. You would never say [common mistake]. You always [specific habit]."
Generic AI = generic output. Specific persona = specific expertise.
6. The "Thinking Budget"
"Take 500 words to think through this problem before answering. Show all dead ends."
More tokens = better reasoning. Dead ends reveal model understanding.
"Take 500 words to think through this problem before answering. Show all dead ends."
More tokens = better reasoning. Dead ends reveal model understanding.
7. The "Comparison Protocol"
"Compare approach A vs B across these 5 dimensions: [speed, accuracy, cost, complexity, maintenance]. Use a table."
Forces structured analysis. Tables > paragraphs for technical decisions.
"Compare approach A vs B across these 5 dimensions: [speed, accuracy, cost, complexity, maintenance]. Use a table."
Forces structured analysis. Tables > paragraphs for technical decisions.
8. The "Uncertainty Quantification"
"Rate your confidence 0-100 for each claim. Flag anything below 70 as speculative."
Hallucinations are less dangerous when labeled. Confidence scoring is mandatory.
"Rate your confidence 0-100 for each claim. Flag anything below 70 as speculative."
Hallucinations are less dangerous when labeled. Confidence scoring is mandatory.
9. The "Edge Case Hunter"
"What are 5 inputs that would break this approach? Be adversarial."
Models miss edge cases humans would catch. Forcing adversarial thinking reveals brittleness.
"What are 5 inputs that would break this approach? Be adversarial."
Models miss edge cases humans would catch. Forcing adversarial thinking reveals brittleness.
10. The "Chain of Verification"
"First, answer the question. Second, list 3 ways your answer could be wrong. Third, verify each concern and update your answer."
Self-correction built into the prompt. Models fix their own mistakes.
"First, answer the question. Second, list 3 ways your answer could be wrong. Third, verify each concern and update your answer."
Self-correction built into the prompt. Models fix their own mistakes.
Your premium AI bundle to 10x your business
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Weekly updates
Start your free trial👇
godofprompt.ai/complete-ai-bu…
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Weekly updates
Start your free trial👇
godofprompt.ai/complete-ai-bu…
That's a wrap:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
https://twitter.com/1643695629665722379/status/2021873227363152090
• • •
Missing some Tweet in this thread? You can try to
force a refresh