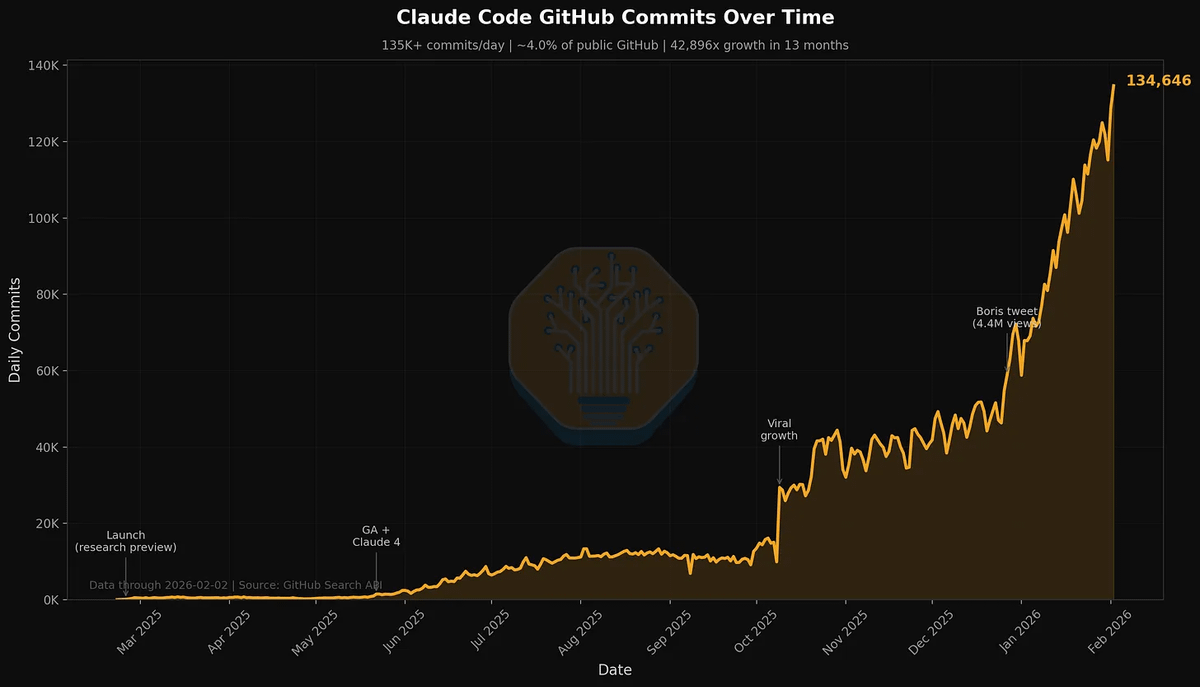
SemiAnalysis just published data showing 4% of all public GitHub commits are now authored by Claude Code.
their projection: 20%+ by year-end 2026.
in the same week, Goldman Sachs revealed it embedded Anthropic engineers for 6 months to build autonomous accounting agents.
a thread on the week ai stopped being a tool and started being a coworker:
their projection: 20%+ by year-end 2026.
in the same week, Goldman Sachs revealed it embedded Anthropic engineers for 6 months to build autonomous accounting agents.
a thread on the week ai stopped being a tool and started being a coworker:
let's start with the Goldman story because it's the one that should make every back-office professional pause.
Goldman's CIO told CNBC they were "surprised" at how capable Claude was beyond coding. accounting, compliance, client onboarding, KYC, AML.
his exact framing: "digital co-workers for professions that are scaled, complex, and very process intensive."
not chatbots answering FAQs. autonomous agents parsing trade records, applying regulatory rules, routing approvals.
they started with an ai coding tool called Devin. then realized Claude's reasoning engine works the same way on rules-based financial tasks as it does on code.
the quiet part: Goldman's CEO already announced plans to constrain headcount growth during the shift. no mass layoffs yet. but "slower headcount growth" is how corporations say "we're replacing the next hire, not the current one."
Goldman's CIO told CNBC they were "surprised" at how capable Claude was beyond coding. accounting, compliance, client onboarding, KYC, AML.
his exact framing: "digital co-workers for professions that are scaled, complex, and very process intensive."
not chatbots answering FAQs. autonomous agents parsing trade records, applying regulatory rules, routing approvals.
they started with an ai coding tool called Devin. then realized Claude's reasoning engine works the same way on rules-based financial tasks as it does on code.
the quiet part: Goldman's CEO already announced plans to constrain headcount growth during the shift. no mass layoffs yet. but "slower headcount growth" is how corporations say "we're replacing the next hire, not the current one."
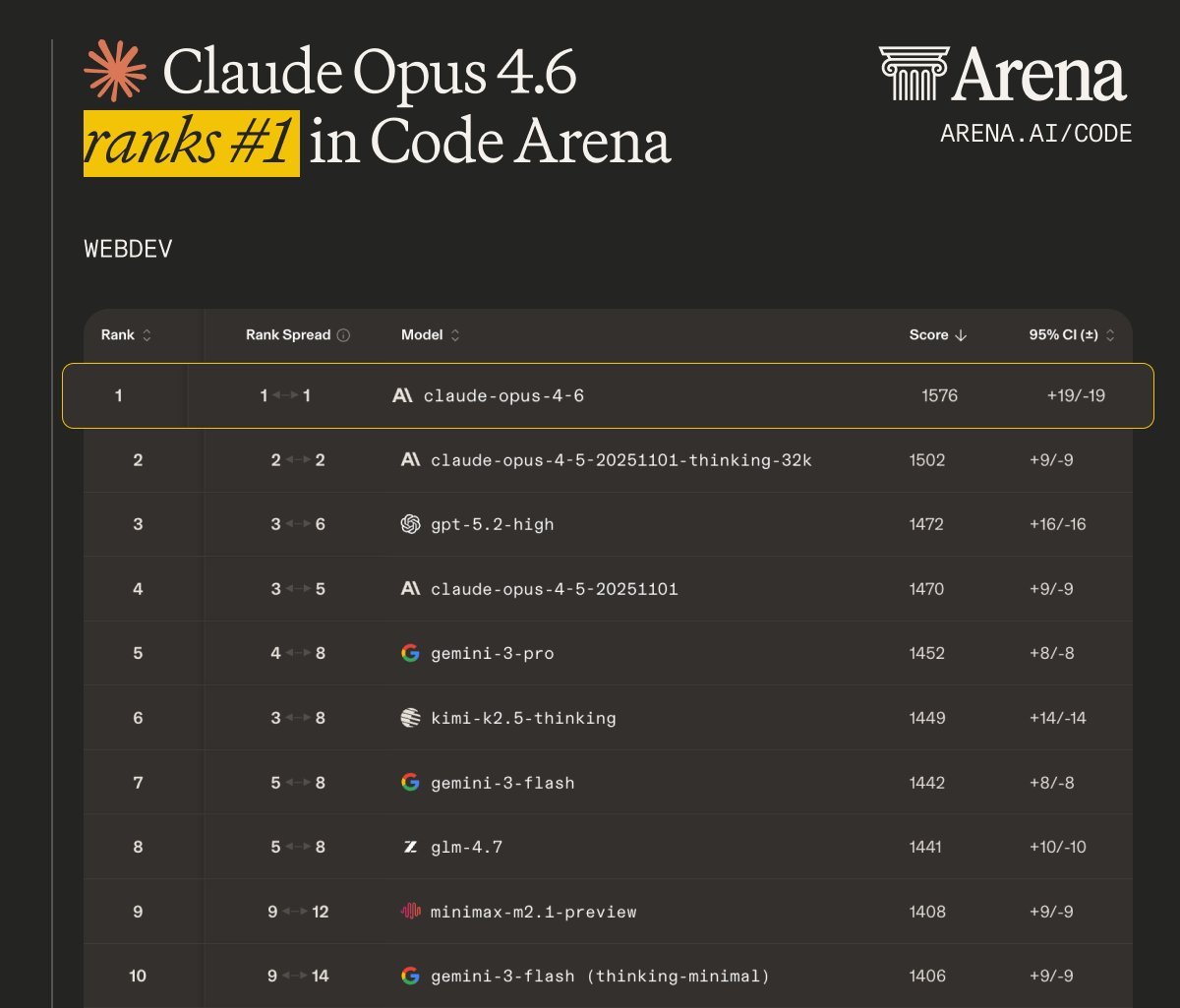
now the SemiAnalysis numbers.
4% of GitHub public commits. Claude Code. right now. not projected. not theoretical. measured.
the tool has been live for roughly a year. it went from research preview to mass platform impact faster than almost any dev tool in history.
and that 20% projection isn't hype math. SemiAnalysis tracks autonomous task horizons doubling every 4-7 months. each doubling unlocks more complex work: snippet completion at 30 minutes, module refactoring at 4.8 hours, full audits at multi-day horizons.
the implication isn't "developers are getting faster." it's that the definition of "developer" is expanding to include anyone who can describe a problem clearly.
4% of GitHub public commits. Claude Code. right now. not projected. not theoretical. measured.
the tool has been live for roughly a year. it went from research preview to mass platform impact faster than almost any dev tool in history.
and that 20% projection isn't hype math. SemiAnalysis tracks autonomous task horizons doubling every 4-7 months. each doubling unlocks more complex work: snippet completion at 30 minutes, module refactoring at 4.8 hours, full audits at multi-day horizons.
the implication isn't "developers are getting faster." it's that the definition of "developer" is expanding to include anyone who can describe a problem clearly.
the model race itself has turned into something i've never seen before.
on February 5, Anthropic and OpenAI released new flagship models on the same day. Claude Opus 4.6 and GPT-5.3-Codex. simultaneously.
Opus 4.6 took #1 on the Vals Index with 71.71% average accuracy and #1 on the Artificial Analysis Intelligence Index. SOTA on FinanceAgent, ProofBench, TaxEval, SWE-Bench.
GPT-5.3-Codex fired back with top scores on SWE-Bench Pro and TerminalBench 2.0, plus a claimed 2.09x token efficiency improvement.
this isn't annual model releases anymore. it's weekly leapfrogging. the gap between "best model" and "second best" now lasts days, not months.
on February 5, Anthropic and OpenAI released new flagship models on the same day. Claude Opus 4.6 and GPT-5.3-Codex. simultaneously.
Opus 4.6 took #1 on the Vals Index with 71.71% average accuracy and #1 on the Artificial Analysis Intelligence Index. SOTA on FinanceAgent, ProofBench, TaxEval, SWE-Bench.
GPT-5.3-Codex fired back with top scores on SWE-Bench Pro and TerminalBench 2.0, plus a claimed 2.09x token efficiency improvement.
this isn't annual model releases anymore. it's weekly leapfrogging. the gap between "best model" and "second best" now lasts days, not months.
but the real signal isn't the models. it's who's building the infrastructure around them.
Apple shipped Xcode 26.3 with native agentic coding support. Claude Agent and OpenAI Codex now work directly inside Xcode. one click to add. swap between agents mid-project.
Apple redesigned its developer documentation to be readable by ai agents.
read that again. Apple is designing docs for ai to read, not just humans.
the company that spent decades perfecting human-facing interfaces is now optimizing for machine-facing ones.
Apple shipped Xcode 26.3 with native agentic coding support. Claude Agent and OpenAI Codex now work directly inside Xcode. one click to add. swap between agents mid-project.
Apple redesigned its developer documentation to be readable by ai agents.
read that again. Apple is designing docs for ai to read, not just humans.
the company that spent decades perfecting human-facing interfaces is now optimizing for machine-facing ones.
OpenAI launched "Frontier," an enterprise platform for managing ai agents the way companies manage employees.
onboarding processes. performance feedback loops. review cycles.
HP, Oracle, State Farm, Uber already signed on.
Accenture is training 30,000 professionals on Claude. the largest enterprise deployment so far, targeting financial services, life sciences, healthcare, and public sector.
the language has shifted. nobody at these companies is saying "ai assistant" anymore. they're saying "digital workforce."
onboarding processes. performance feedback loops. review cycles.
HP, Oracle, State Farm, Uber already signed on.
Accenture is training 30,000 professionals on Claude. the largest enterprise deployment so far, targeting financial services, life sciences, healthcare, and public sector.
the language has shifted. nobody at these companies is saying "ai assistant" anymore. they're saying "digital workforce."
meanwhile, the unverified but plausible claims from this week's briefing paint an even wilder picture:
reportedly, racks of Mac Minis in China are hosting ai agents as "24/7 employees." ElevenLabs is pushing voice-enabled agents that make phone calls autonomously. OpenAI is supposedly requiring all employees to code via agents by March 31, banning direct use of editors and terminals.
i can't confirm all of these yet. but the verified stuff alone, Goldman embedding ai accountants, 4% of GitHub already automated, Apple redesigning docs for machines, tells you the trajectory is real even if some individual claims aren't.
reportedly, racks of Mac Minis in China are hosting ai agents as "24/7 employees." ElevenLabs is pushing voice-enabled agents that make phone calls autonomously. OpenAI is supposedly requiring all employees to code via agents by March 31, banning direct use of editors and terminals.
i can't confirm all of these yet. but the verified stuff alone, Goldman embedding ai accountants, 4% of GitHub already automated, Apple redesigning docs for machines, tells you the trajectory is real even if some individual claims aren't.
the financial infrastructure is reacting in real time.
memory chip prices reportedly surged 80-90% in Q1. global chip sales projected to hit $1 trillion this year.
the compute demand from agentic ai isn't theoretical. it's already straining supply chains.
and with terrestrial resistance to data center construction growing (New York lawmakers reportedly introduced a moratorium bill), the pressure is building for creative solutions. orbital compute. alternative energy. distributed processing.
the physical world is scrambling to keep up with the virtual one.
memory chip prices reportedly surged 80-90% in Q1. global chip sales projected to hit $1 trillion this year.
the compute demand from agentic ai isn't theoretical. it's already straining supply chains.
and with terrestrial resistance to data center construction growing (New York lawmakers reportedly introduced a moratorium bill), the pressure is building for creative solutions. orbital compute. alternative energy. distributed processing.
the physical world is scrambling to keep up with the virtual one.
the broader pattern from this week:
ai stopped being a product category and became an employment category.
Goldman doesn't want a "Claude product." it wants Claude employees.
Apple doesn't want ai features. it wants ai-native development.
OpenAI isn't selling an api. it's selling Frontier, a platform to manage your agent headcount.
the abstraction layer between "tool" and "worker" collapsed in a single week.
ai stopped being a product category and became an employment category.
Goldman doesn't want a "Claude product." it wants Claude employees.
Apple doesn't want ai features. it wants ai-native development.
OpenAI isn't selling an api. it's selling Frontier, a platform to manage your agent headcount.
the abstraction layer between "tool" and "worker" collapsed in a single week.
and because no week in 2026 is complete without the absurd:
bonobos were reportedly found to identify pretend objects, further proving symbolic thought isn't unique to humans.
and in China, a blackout was allegedly caused by a farmer trying to transport a pig via drone across mountainous terrain. the pig hit power lines.
we've been saying the singularity will arrive "when pigs fly."
apparently it just did.
bonobos were reportedly found to identify pretend objects, further proving symbolic thought isn't unique to humans.
and in China, a blackout was allegedly caused by a farmer trying to transport a pig via drone across mountainous terrain. the pig hit power lines.
we've been saying the singularity will arrive "when pigs fly."
apparently it just did.
Your premium AI bundle to 10x your business
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Weekly updates
Start your free trial👇
godofprompt.ai/complete-ai-bu…
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Weekly updates
Start your free trial👇
godofprompt.ai/complete-ai-bu…
• • •
Missing some Tweet in this thread? You can try to
force a refresh