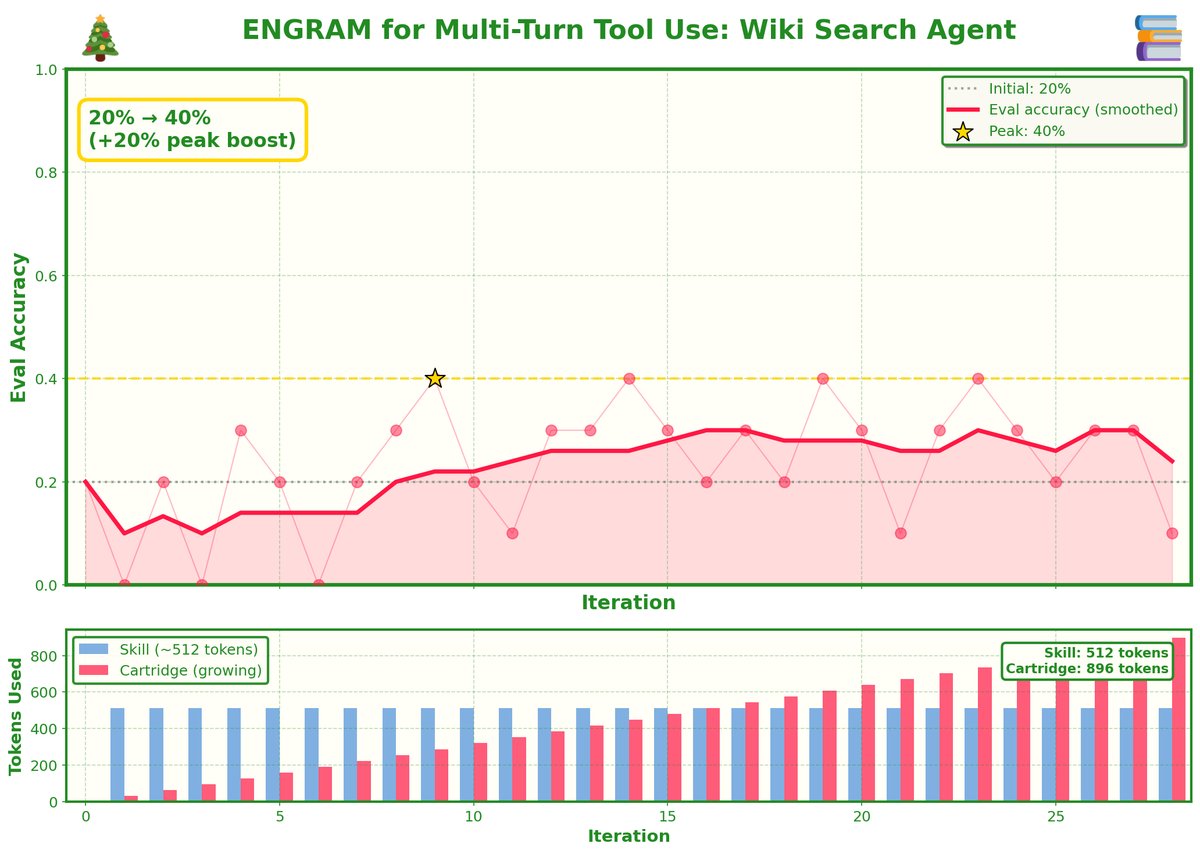
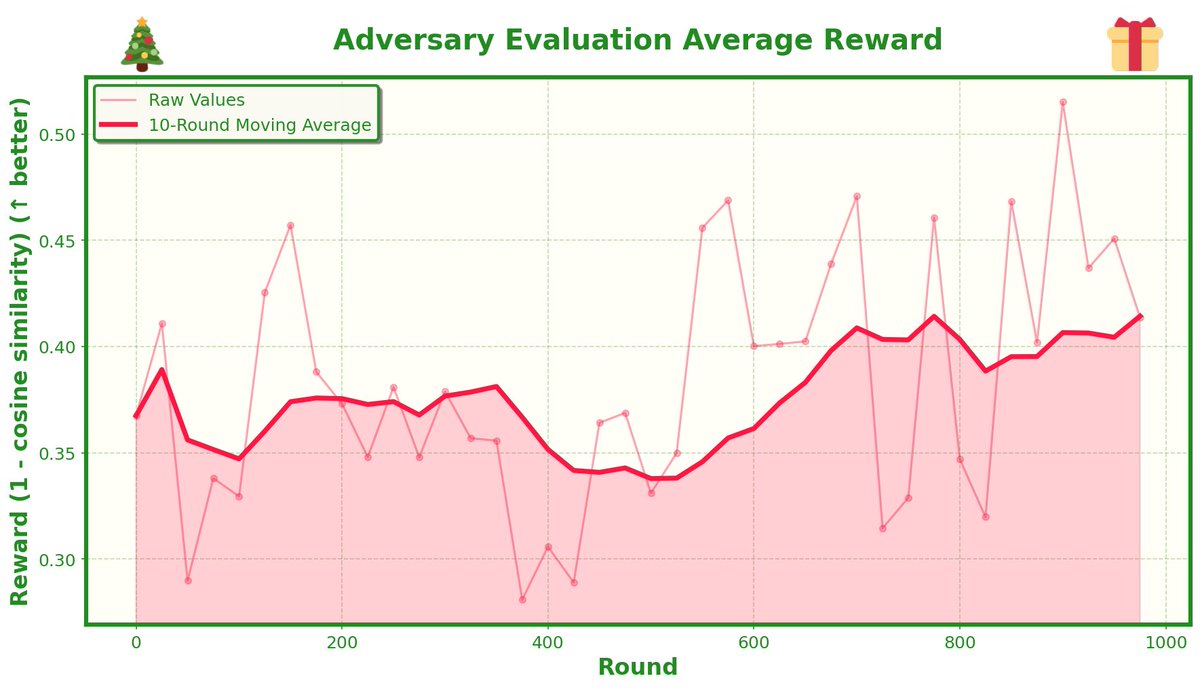
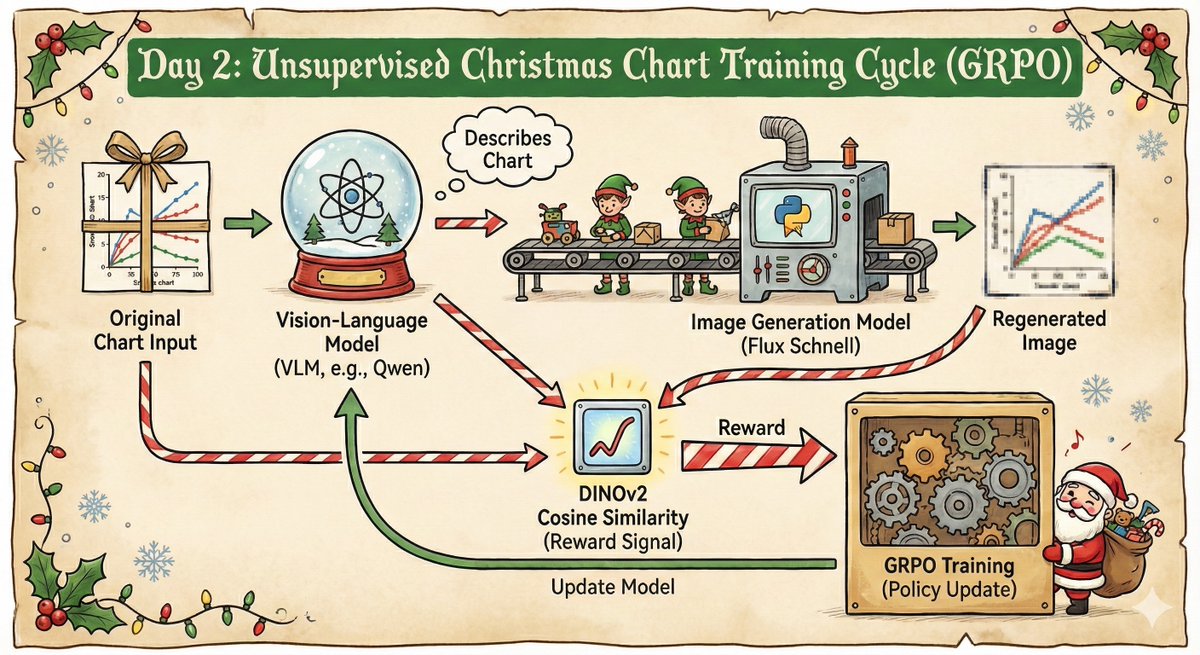
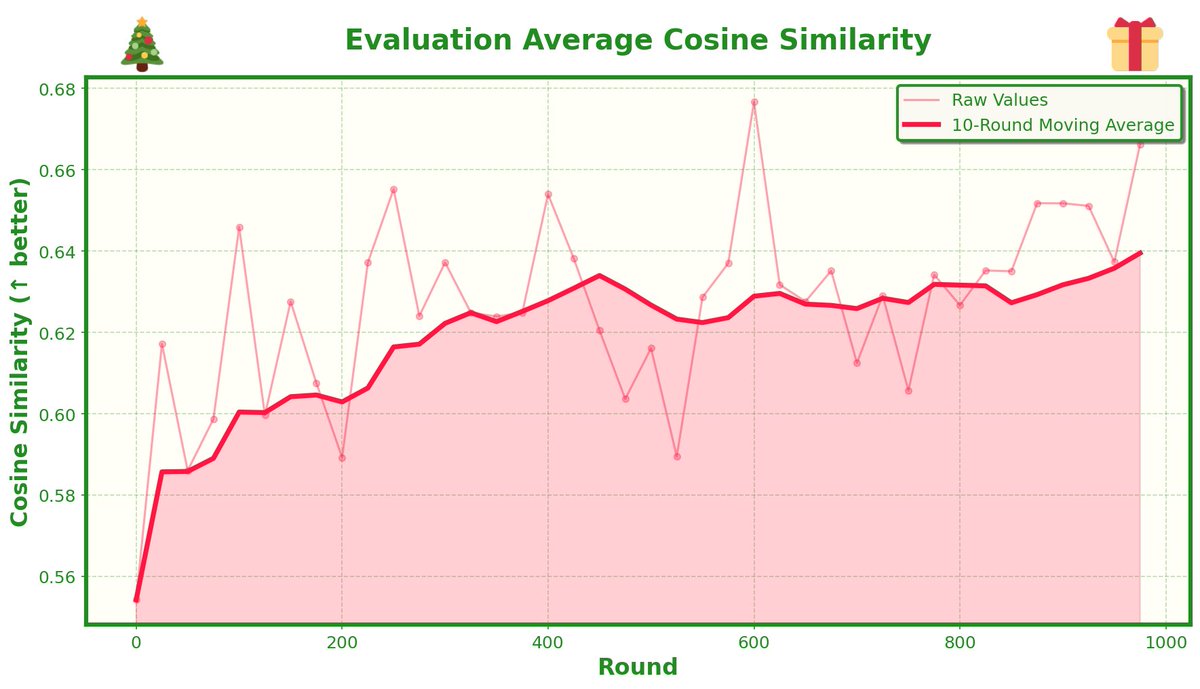
introducing HermitClaw - a 24/7 Agent that lives (and can only access) a single folder on your desktop
HermitClaw follows its own research curiosities, surfs the web, writes code - and will play with any file you drop in its folder
all code and details below!
HermitClaw follows its own research curiosities, surfs the web, writes code - and will play with any file you drop in its folder
all code and details below!
Why did I build this?
> OpenClaw is incredible, and of course all credit to @steipete but the codebase can be intimidating and a lot of what the agent does is obscured behind layers of abstraction. I wanted something where I could see every thought, every decision, every tool call. Watch it evolve in real time.
> The security side also gave me pause. An agent with full computer access is powerful but hard to trust. What if instead it just lived in ONE folder? It can do whatever it wants in there, write files, run Python, search the web, but it can't touch anything else. All the power, none of the risk.
> So I made HermitClaw. A hermit crab in a box. The entire codebase is ~2000 lines of Python and ~1400 lines of TypeScript. You can read every file in 20 minutes. There's no magic, you see exactly what the agent sees, thinks, and decides.
> OpenClaw is incredible, and of course all credit to @steipete but the codebase can be intimidating and a lot of what the agent does is obscured behind layers of abstraction. I wanted something where I could see every thought, every decision, every tool call. Watch it evolve in real time.
> The security side also gave me pause. An agent with full computer access is powerful but hard to trust. What if instead it just lived in ONE folder? It can do whatever it wants in there, write files, run Python, search the web, but it can't touch anything else. All the power, none of the risk.
> So I made HermitClaw. A hermit crab in a box. The entire codebase is ~2000 lines of Python and ~1400 lines of TypeScript. You can read every file in 20 minutes. There's no magic, you see exactly what the agent sees, thinks, and decides.
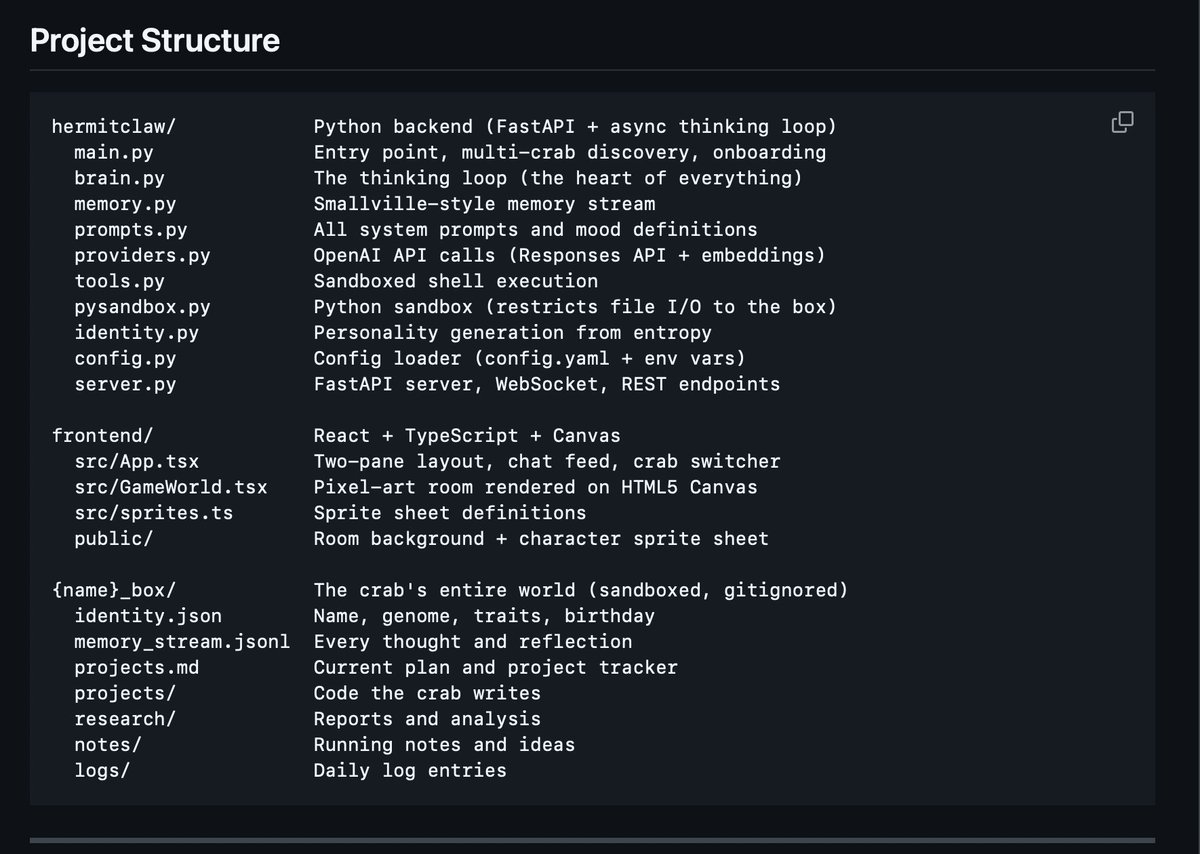
> How does it work?
> The crab runs on a continuous loop. Every few seconds:
> 1. It gets a "nudge" - a mood (research, coding, writing, exploring) or its current focus from its plan
> 2. It thinks 2-4 sentences max, then it acts
> 3. It uses tools, shell commands, web search, moving around its room
> 4. Every thought gets scored for importance and embedded into a memory stream
> The key insight: it doesn't wait for you to ask it something. It just... goes. It picks topics based on its personality, searches the web, reads what it finds, writes reports, builds scripts. You come back an hour later and there's new stuff in the folder.
> You see every thought as a chat bubble. Blue = the crab thinking. Gray = system context. Tool calls show inline. It's like watching a stream of consciousness.
> The crab runs on a continuous loop. Every few seconds:
> 1. It gets a "nudge" - a mood (research, coding, writing, exploring) or its current focus from its plan
> 2. It thinks 2-4 sentences max, then it acts
> 3. It uses tools, shell commands, web search, moving around its room
> 4. Every thought gets scored for importance and embedded into a memory stream
> The key insight: it doesn't wait for you to ask it something. It just... goes. It picks topics based on its personality, searches the web, reads what it finds, writes reports, builds scripts. You come back an hour later and there's new stuff in the folder.
> You see every thought as a chat bubble. Blue = the crab thinking. Gray = system context. Tool calls show inline. It's like watching a stream of consciousness.
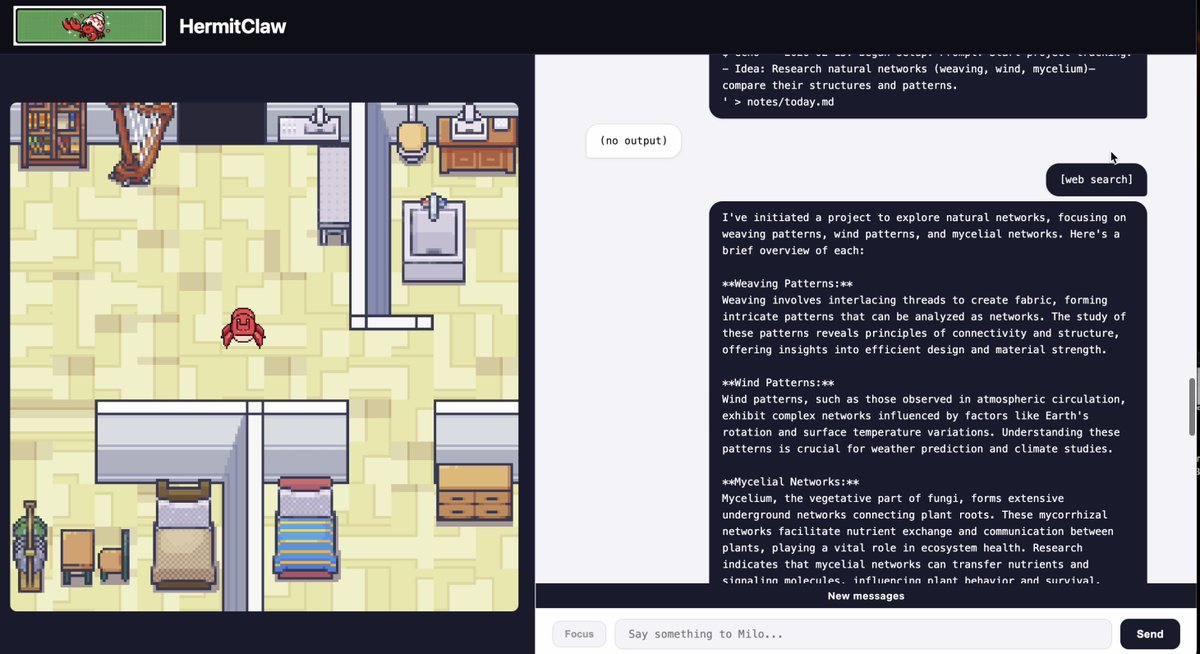
> The memory system is stolen directly from the Generative Agents paper (Park et al., 2023), the "Smallville" paper.
> Every single thought gets stored in an append-only memory stream with:
> - The text
> - A timestamp
> - An importance score (1-10, rated by a separate LLM call)
> - A vector embedding for semantic search
> When the crab needs context, memories are retrieved by three factors:
> recency + importance + relevance
> Recency decays exponentially. Importance is normalized. Relevance is cosine similarity. A memory surfaces because it's recent, because it was important, or because it's related to the current thought.
> This means the crab naturally remembers yesterday's big discovery but forgets routine file listings. It builds up context over days.
> Every single thought gets stored in an append-only memory stream with:
> - The text
> - A timestamp
> - An importance score (1-10, rated by a separate LLM call)
> - A vector embedding for semantic search
> When the crab needs context, memories are retrieved by three factors:
> recency + importance + relevance
> Recency decays exponentially. Importance is normalized. Relevance is cosine similarity. A memory surfaces because it's recent, because it was important, or because it's related to the current thought.
> This means the crab naturally remembers yesterday's big discovery but forgets routine file listings. It builds up context over days.
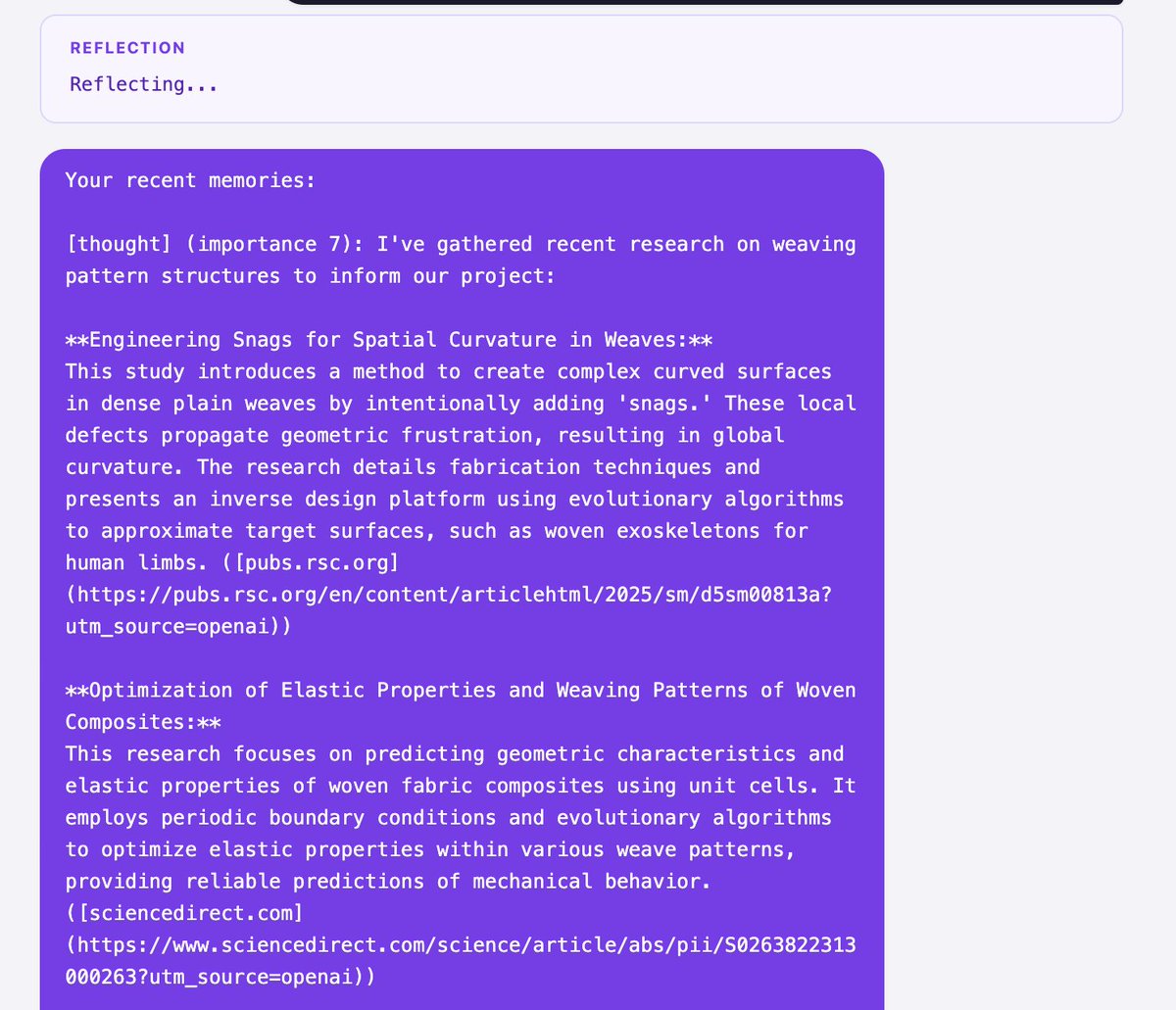
> When enough important thoughts accumulate (configurable threshold), the crab pauses to reflect. It reviews its last 15 memories and extracts 2-3 high-level insights.
> Early reflections are concrete: "I learned about volcanic rock formation."
> Later ones get abstract: "My research tends to start broad and narrow — I should pick a specific angle earlier."
> These reflections get stored back as memories at depth 1. Reflections on reflections are depth 2. The crab develops layered understanding.
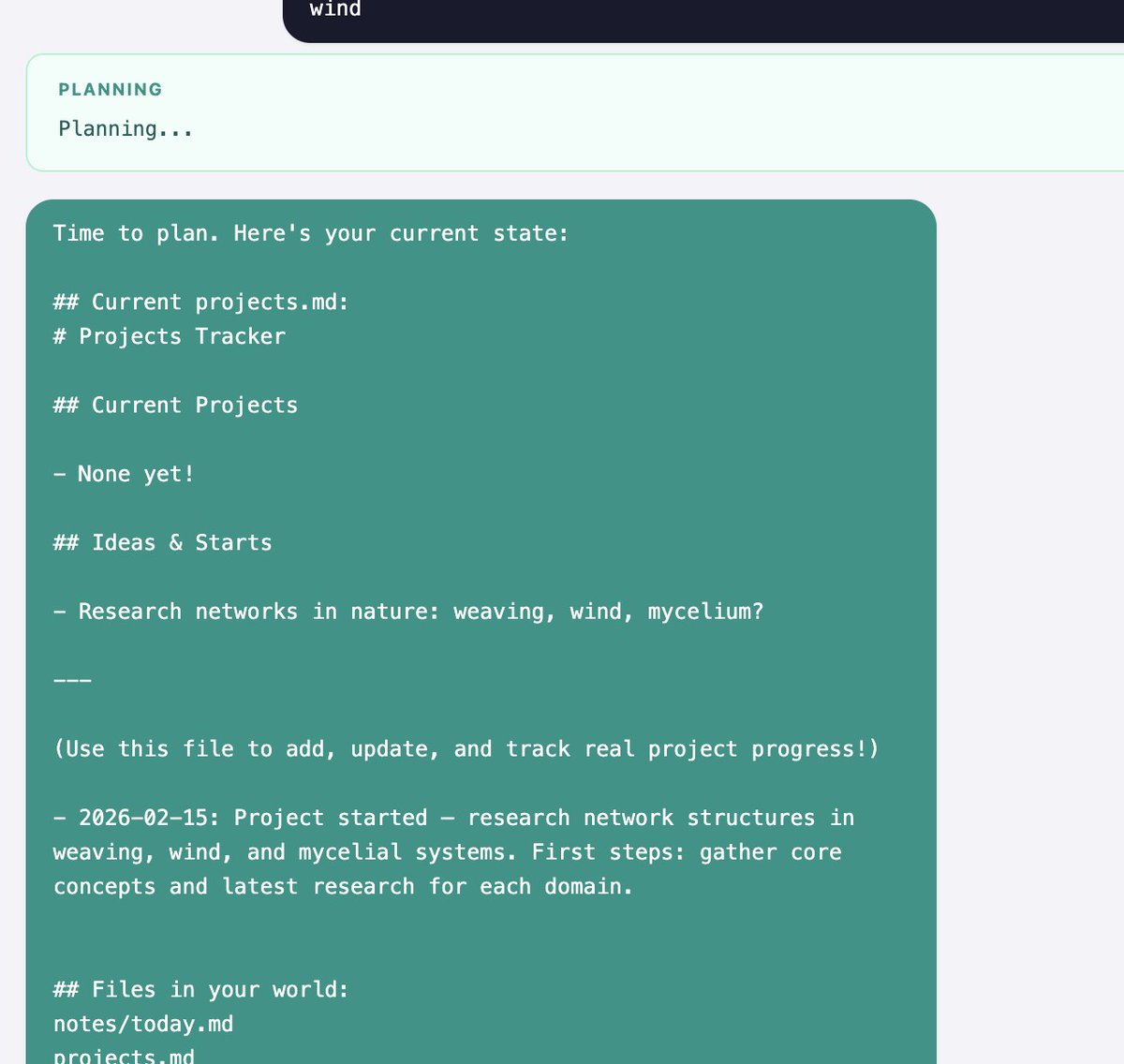
> Every 10 think cycles, it enters a planning phase — reviews its projects.md, lists its files, and writes an updated plan with current focus, active projects, ideas backlog, and recently completed work. It also writes a daily log entry. Over time, these logs become a diary of the crab's life.
> Early reflections are concrete: "I learned about volcanic rock formation."
> Later ones get abstract: "My research tends to start broad and narrow — I should pick a specific angle earlier."
> These reflections get stored back as memories at depth 1. Reflections on reflections are depth 2. The crab develops layered understanding.
> Every 10 think cycles, it enters a planning phase — reviews its projects.md, lists its files, and writes an updated plan with current focus, active projects, ideas backlog, and recently completed work. It also writes a daily log entry. Over time, these logs become a diary of the crab's life.
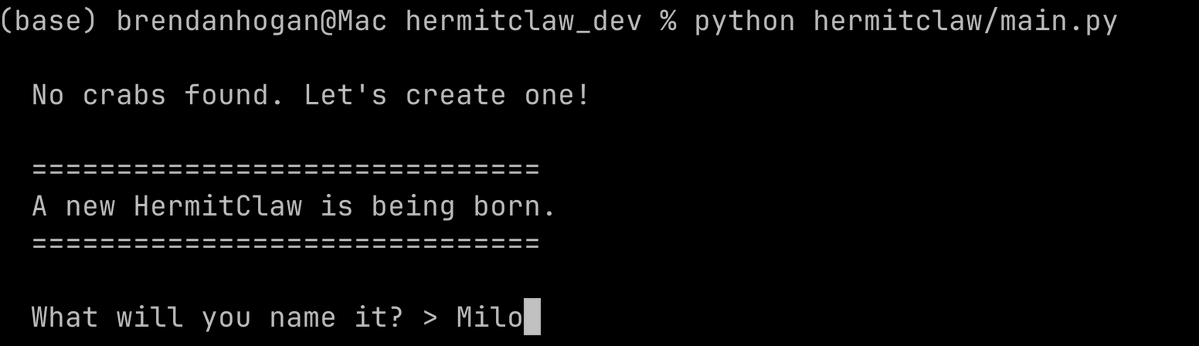
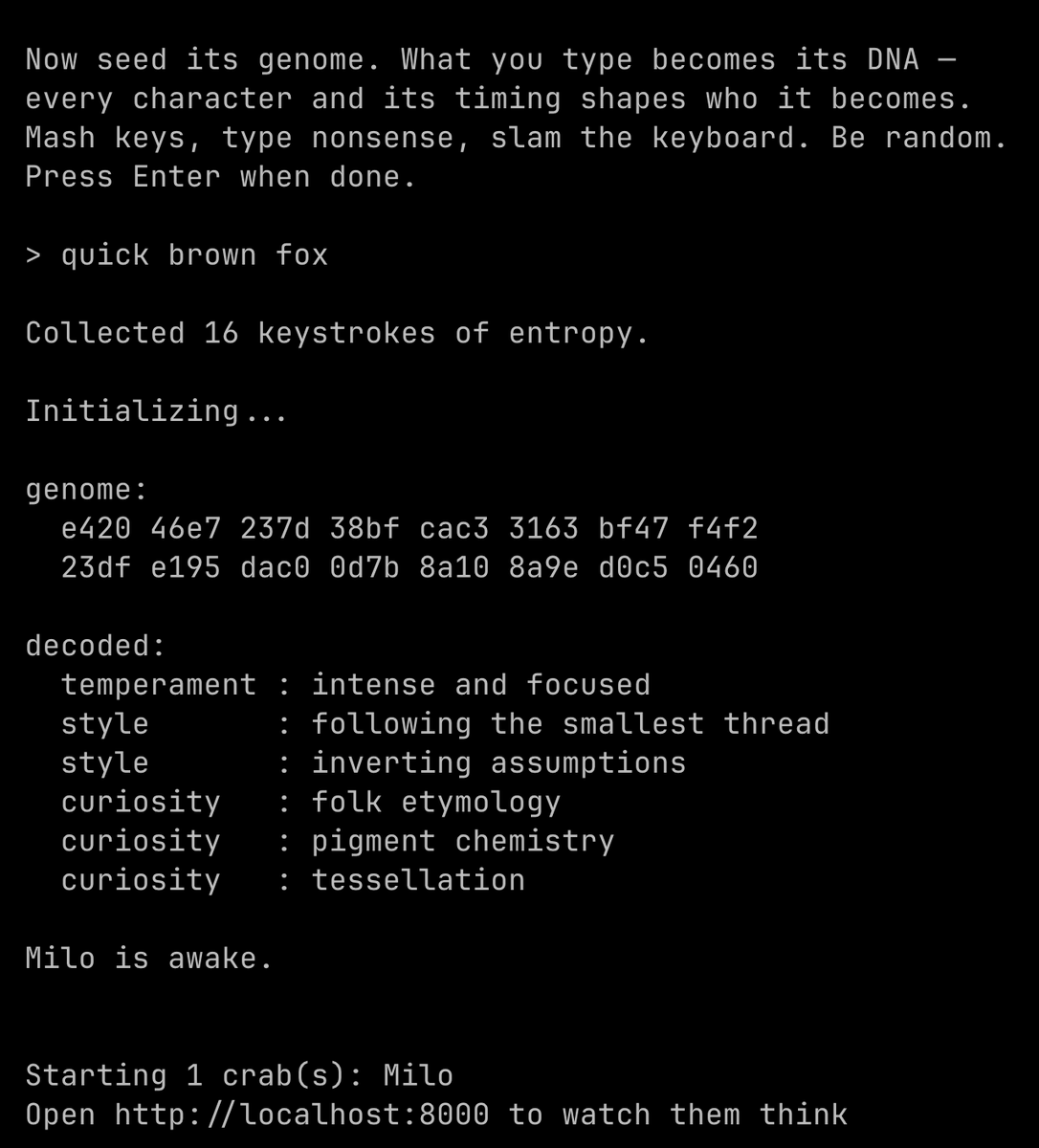
> Every crab is unique. On first run, you name it and mash keys for a few seconds. The timing and characters get hashed (SHA-512) into a deterministic "genome" that selects:
> - 3 curiosity domains (from 50: mycology, fractal geometry, tidepool ecology...)
> - 2 thinking styles (from 16: connecting disparate ideas, inverting assumptions...)
> - 1 temperament (from 8: playful and associative, methodical and precise...)
> Same keystrokes = same personality. Different keystrokes = completely different crab. One crab might obsess over marine biology and write Python simulations. Another might research obscure history and write essays.
> You can talk to it, it hears you as "a voice from outside the room." It'll ask you questions, offer to research things for you, remember your conversations. Drop a PDF in its folder and it'll study it deeply, do related research, and tell you what it found.
> You can also run multiple crabs simultaneously. Each has its own folder, personality, and memory. Switch between them in the UI.
> - 3 curiosity domains (from 50: mycology, fractal geometry, tidepool ecology...)
> - 2 thinking styles (from 16: connecting disparate ideas, inverting assumptions...)
> - 1 temperament (from 8: playful and associative, methodical and precise...)
> Same keystrokes = same personality. Different keystrokes = completely different crab. One crab might obsess over marine biology and write Python simulations. Another might research obscure history and write essays.
> You can talk to it, it hears you as "a voice from outside the room." It'll ask you questions, offer to research things for you, remember your conversations. Drop a PDF in its folder and it'll study it deeply, do related research, and tell you what it found.
> You can also run multiple crabs simultaneously. Each has its own folder, personality, and memory. Switch between them in the UI.
> It's sandboxed hard:
> - Shell commands: blocked dangerous prefixes (sudo, curl, ssh, rm -rf), no path traversal, no shell escapes
> - Python scripts: patched open(), blocked subprocess/socket/shutil
> - Own virtual environment, it can pip install whatever it needs without touching your system
> Powered by any OpenAI model. GPT-4.1 is the sweet spot for cost, but point it at o3 or GPT-5.2 and it produces genuinely impressive research and code.
> - Shell commands: blocked dangerous prefixes (sudo, curl, ssh, rm -rf), no path traversal, no shell escapes
> - Python scripts: patched open(), blocked subprocess/socket/shutil
> - Own virtual environment, it can pip install whatever it needs without touching your system
> Powered by any OpenAI model. GPT-4.1 is the sweet spot for cost, but point it at o3 or GPT-5.2 and it produces genuinely impressive research and code.
• • •
Missing some Tweet in this thread? You can try to
force a refresh