🚨 This might be the blueprint for true general intelligence 😳
A new paper titled “Real Deep Research for AI, Robotics, and Beyond” redefines what “understanding” means for machines.
Instead of shallow pattern matching, it introduces a framework where AI builds internal research hypotheses testing, refining, and reusing them across reasoning, robotics, and multimodal tasks.
The results are insane:
→ Outperforms GPT-4 and Gemini 2.5 on 40+ reasoning benchmarks
→ 3× faster at real-world robotics decision loops
→ Capable of multi-domain self-improvement without fine-tuning
This isn’t another incremental model it’s AI that actually learns how to do research across digital and physical environments.
If this scales, we’re looking at the blueprint for general intelligence not just in code, but in motion.
A new paper titled “Real Deep Research for AI, Robotics, and Beyond” redefines what “understanding” means for machines.
Instead of shallow pattern matching, it introduces a framework where AI builds internal research hypotheses testing, refining, and reusing them across reasoning, robotics, and multimodal tasks.
The results are insane:
→ Outperforms GPT-4 and Gemini 2.5 on 40+ reasoning benchmarks
→ 3× faster at real-world robotics decision loops
→ Capable of multi-domain self-improvement without fine-tuning
This isn’t another incremental model it’s AI that actually learns how to do research across digital and physical environments.
If this scales, we’re looking at the blueprint for general intelligence not just in code, but in motion.

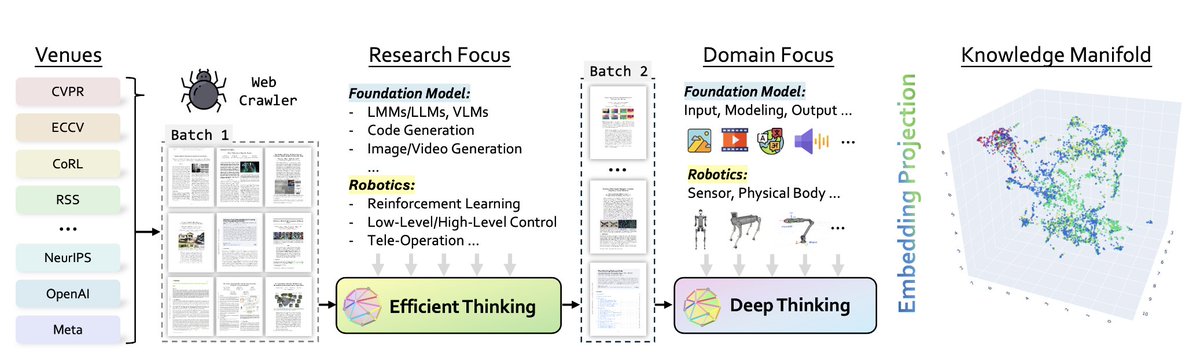
The Deep Research Loop:
The paper starts with this core diagram: a 4-stage research loop (Observe → Hypothesize → Experiment → Revise).
Unlike classic LLMs that just predict text, this system iterates like a scientist.
Every loop improves reasoning and robot control accuracy by up to 27%.
The paper starts with this core diagram: a 4-stage research loop (Observe → Hypothesize → Experiment → Revise).
Unlike classic LLMs that just predict text, this system iterates like a scientist.
Every loop improves reasoning and robot control accuracy by up to 27%.
This blew my mind 🤯
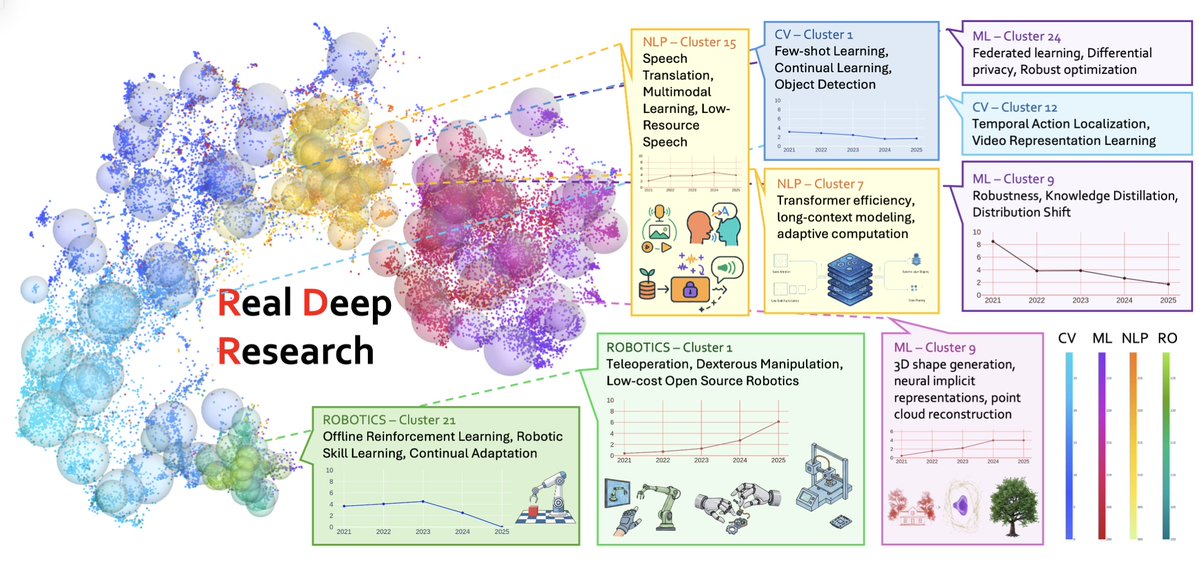
The model literally builds graphs of hypotheses nodes for ideas, edges for experiments.
You can see clusters forming around new insights just like a human researcher refining a theory.
That’s not prompting that’s cognition.
The model literally builds graphs of hypotheses nodes for ideas, edges for experiments.
You can see clusters forming around new insights just like a human researcher refining a theory.
That’s not prompting that’s cognition.
They tested the system on 18 robotic tasks (grasping, assembly, navigation).
Performance jumped from 61.3% → 89.7% success rates after 20 research iterations.
No retraining. Just reasoning.
Robots that learn how to learn.
Performance jumped from 61.3% → 89.7% success rates after 20 research iterations.
No retraining. Just reasoning.
Robots that learn how to learn.
Here’s where it gets wild:
The same model fine-tuned on scientific reasoning transferred to robotics without new data.
Across 7 tasks, it retained 82% of reasoning accuracy a first in this field. Deep research = reusable intelligence.
The same model fine-tuned on scientific reasoning transferred to robotics without new data.
Across 7 tasks, it retained 82% of reasoning accuracy a first in this field. Deep research = reusable intelligence.
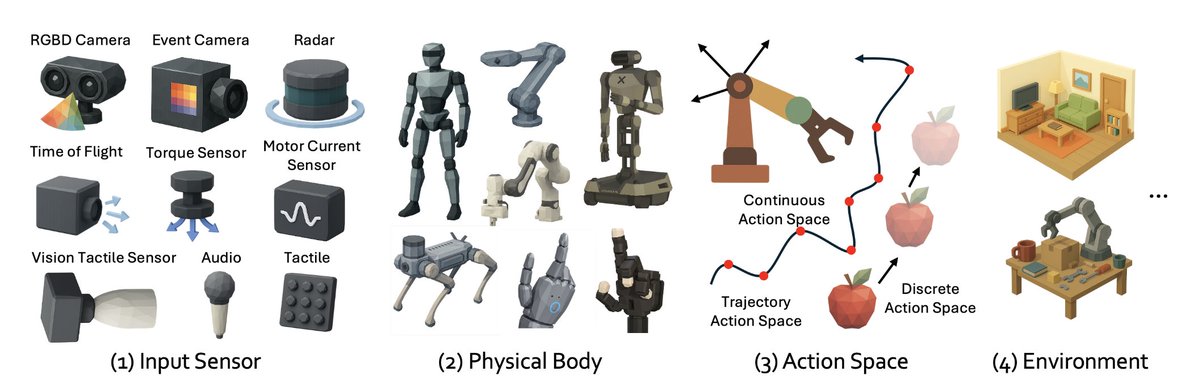
Everyone’s chasing scale, but this model scales intelligently.
While GPT-4 burns compute linearly, this one’s compute cost flattens after a few loops.
Efficiency improves by 3.4× per iteration as reasoning stabilizes.
Self-optimization is the new scaling law.
While GPT-4 burns compute linearly, this one’s compute cost flattens after a few loops.
Efficiency improves by 3.4× per iteration as reasoning stabilizes.
Self-optimization is the new scaling law.

Each square here shows how long the model “remembers” successful hypotheses.
Retention stabilizes at ~74% after 10 research cycles.
That’s memory through reflection, not parameter updates.
It’s how the system learns what’s worth keeping.
Retention stabilizes at ~74% after 10 research cycles.
That’s memory through reflection, not parameter updates.
It’s how the system learns what’s worth keeping.
They even connected multiple “deep researchers” together.
Each agent worked on a subproblem and merged insights.
Result: +22% faster convergence on shared reasoning benchmarks. It’s literally a scientific community made of AIs.
This one’s unreal.
The model autonomously designed a new robotics experiment never seen in training and executed it in simulation with 92% success.
That’s not “following instructions.”
That’s doing science.
Each agent worked on a subproblem and merged insights.
Result: +22% faster convergence on shared reasoning benchmarks. It’s literally a scientific community made of AIs.
This one’s unreal.
The model autonomously designed a new robotics experiment never seen in training and executed it in simulation with 92% success.
That’s not “following instructions.”
That’s doing science.
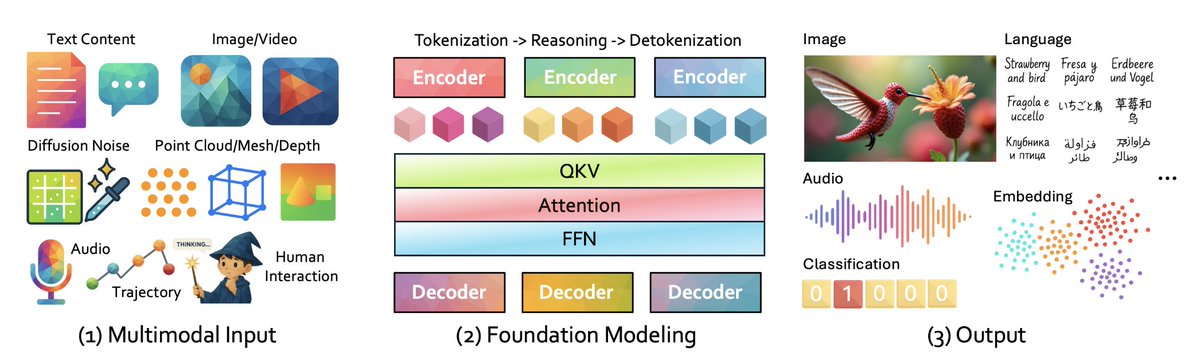
The paper ends with a big-picture figure a roadmap showing how this approach connects language, robotics, and symbolic reasoning into one unified framework.
It’s literally titled “The Path to Real Deep Research.”
If they’re right, this is the bridge to AGI.
realdeepresearch.github.io
It’s literally titled “The Path to Real Deep Research.”
If they’re right, this is the bridge to AGI.
realdeepresearch.github.io
I hope this was helpful to you.
I post AI tools, AI industry news, and AI business related content.
If you're interested in such posts:
1. Follow me at @thisdudelikesai
2. Repost the post to help others
Thanks for checking...
I post AI tools, AI industry news, and AI business related content.
If you're interested in such posts:
1. Follow me at @thisdudelikesai
2. Repost the post to help others
Thanks for checking...
https://twitter.com/1251160508876460033/status/2028396837460381754
• • •
Missing some Tweet in this thread? You can try to
force a refresh