I hijacked Apple's Neural Engine -- the chip built for Siri and photo filters.
Reverse-engineered the private APIs and trained a full LLM on it.
Zero fan noise. Zero GPU. Just the Neural Engine doing what nobody thought it could.
Your Mac has one too.
Reverse-engineered the private APIs and trained a full LLM on it.
Zero fan noise. Zero GPU. Just the Neural Engine doing what nobody thought it could.
Your Mac has one too.

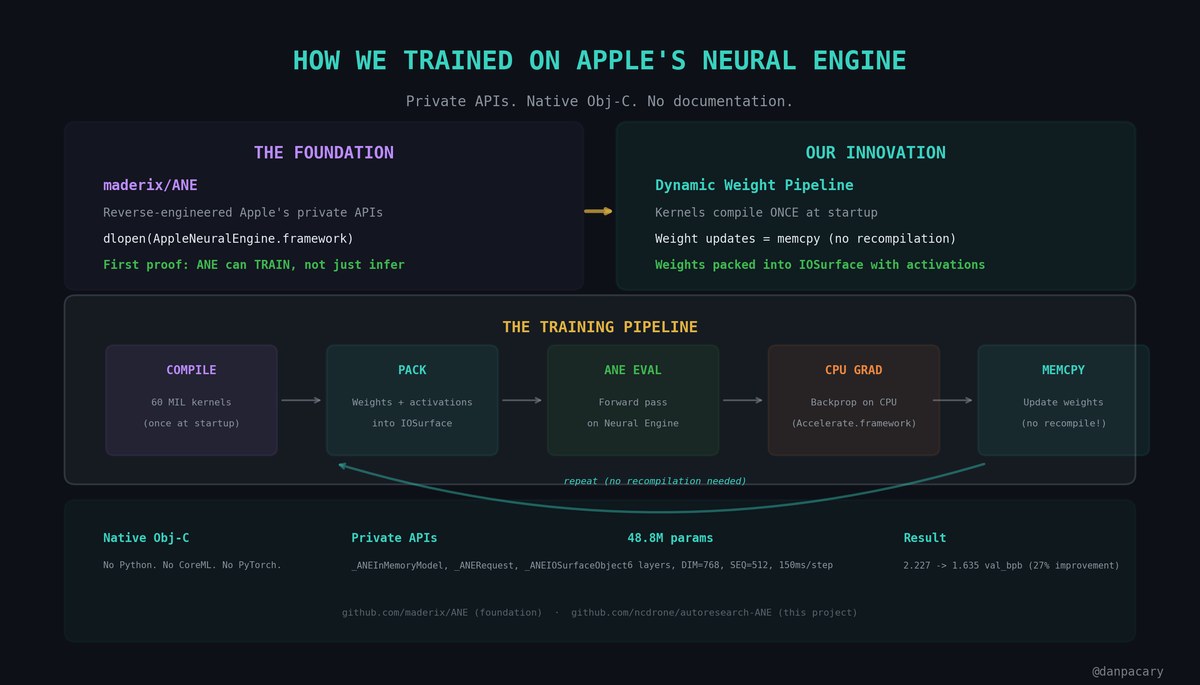
Apple's Neural Engine is in every Apple Silicon Mac. But Apple never documented it for training -- only inference.
We ported native ANE code from maderix (.github.com/maderix/ANE) who reverse-engineered the private APIs. Direct hardware access. Obj-C. No CoreML.
Then built a dynamic weight pipeline: kernels compile once, weight updates are just memcpy.
We ported native ANE code from maderix (.github.com/maderix/ANE) who reverse-engineered the private APIs. Direct hardware access. Obj-C. No CoreML.
Then built a dynamic weight pipeline: kernels compile once, weight updates are just memcpy.
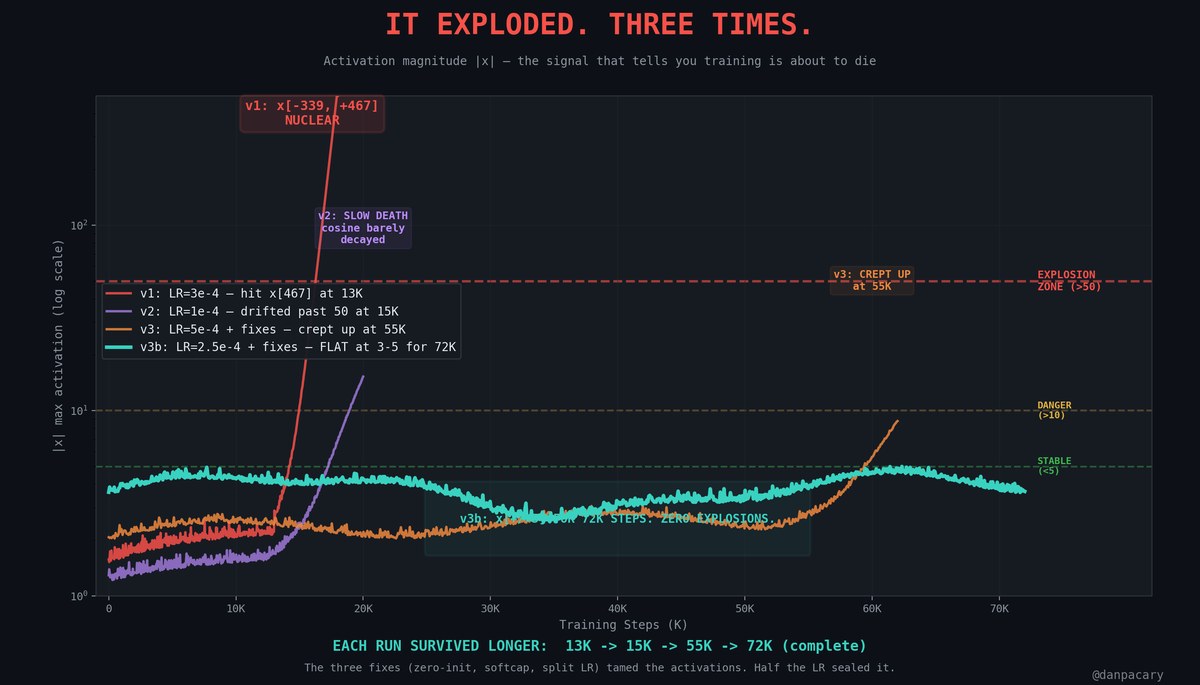
It exploded. Three times.
v1: Activations hit x[-339, +467] at step 13K. Nuclear.
v2: Cosine schedule said 330K steps but ran for hours. Barely decayed. Diverged at 15K.
v3: All fixes applied, LR=5e-4 still too aggressive. Diverged at 55K.
Three runs. Three failures. But each one got further.
v1: Activations hit x[-339, +467] at step 13K. Nuclear.
v2: Cosine schedule said 330K steps but ran for hours. Barely decayed. Diverged at 15K.
v3: All fixes applied, LR=5e-4 still too aggressive. Diverged at 55K.
Three runs. Three failures. But each one got further.
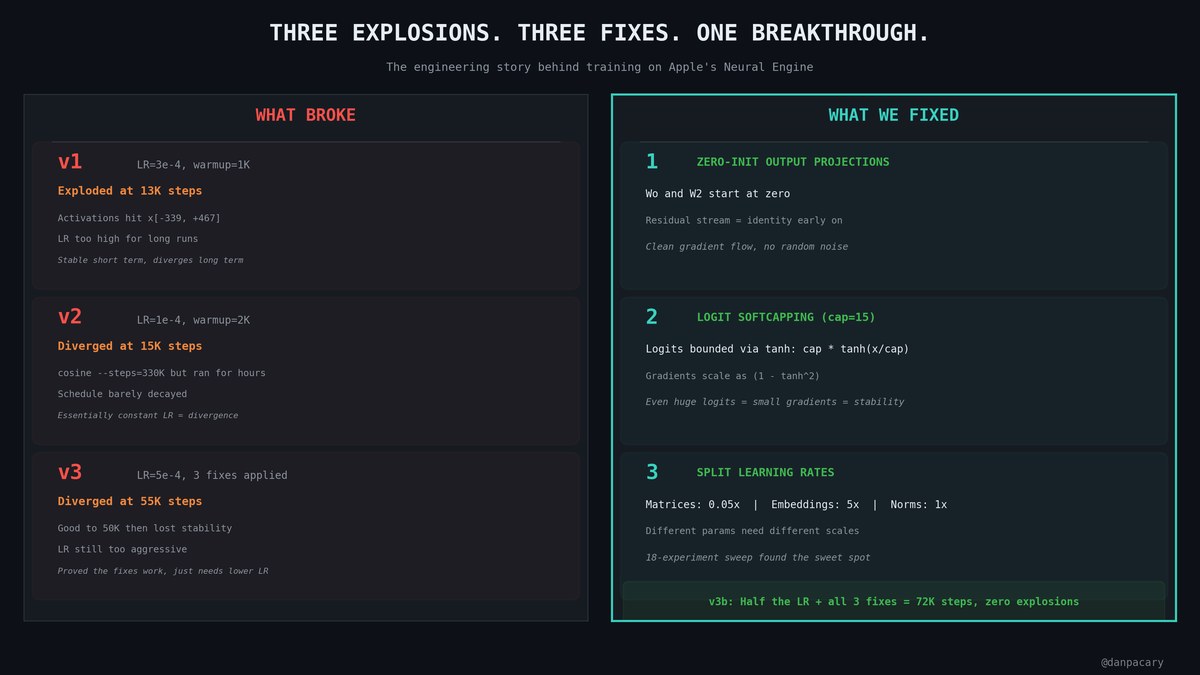
Three things we found that actually worked:
1. Zero-init output projections -- clean gradient flow
2. Logit softcapping (cap=15) -- same technique Claude uses. Gradients can't explode.
3. Split learning rates -- matrices 0.05x, embeddings 5x. 18-experiment sweep found the sweet spot.
Half the LR + all three fixes = v3b.
1. Zero-init output projections -- clean gradient flow
2. Logit softcapping (cap=15) -- same technique Claude uses. Gradients can't explode.
3. Split learning rates -- matrices 0.05x, embeddings 5x. 18-experiment sweep found the sweet spot.
Half the LR + all three fixes = v3b.
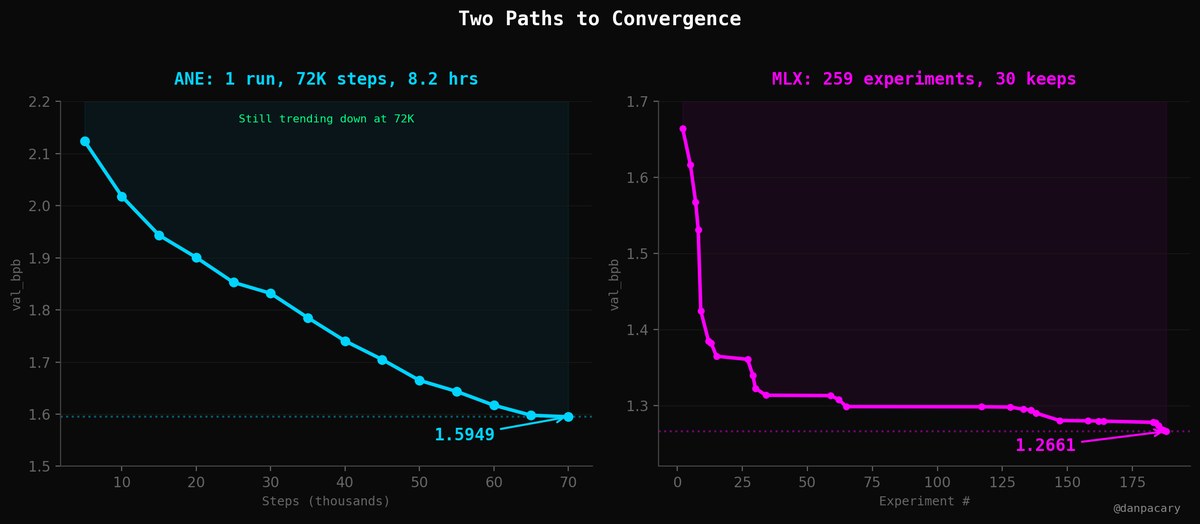
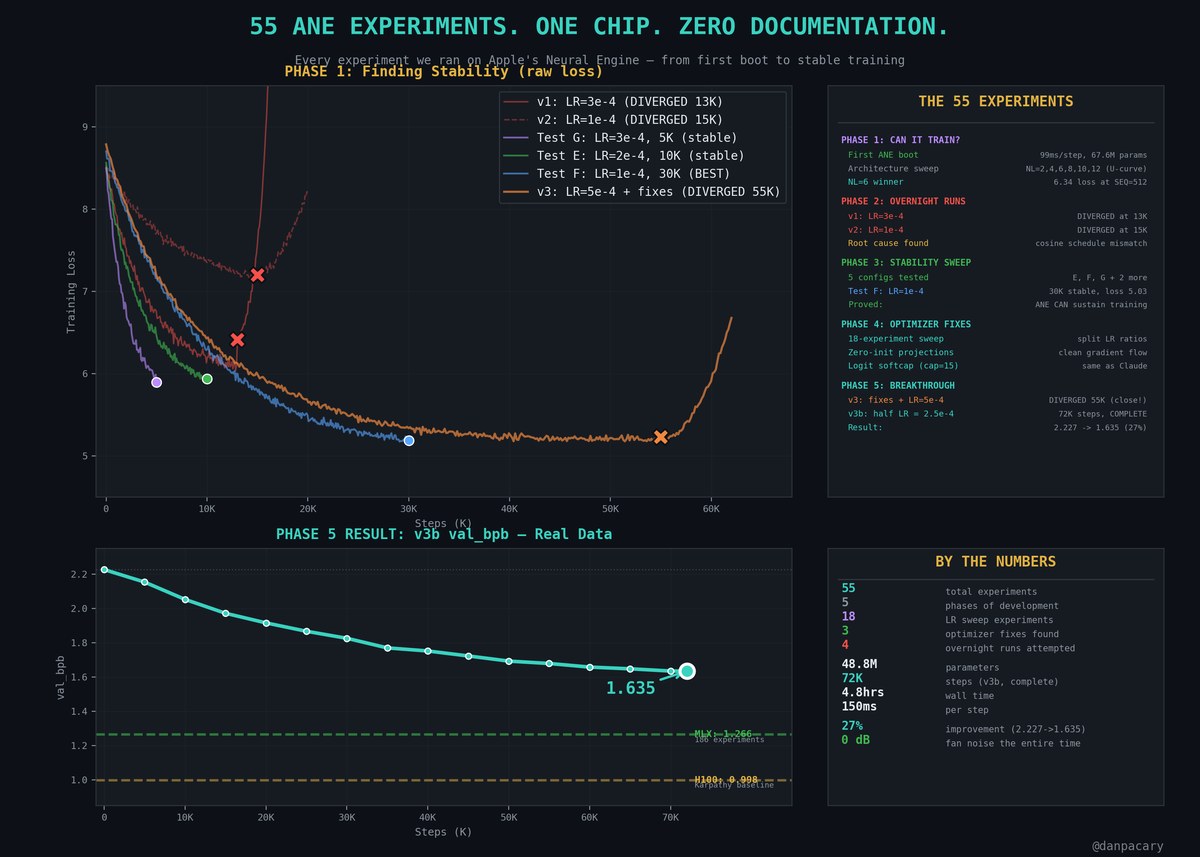
55 experiments over a few weeks. Here's what it came down to.
2.227 -> 1.635 val_bpb. 27% improvement. 72K steps in 4.8 hours.
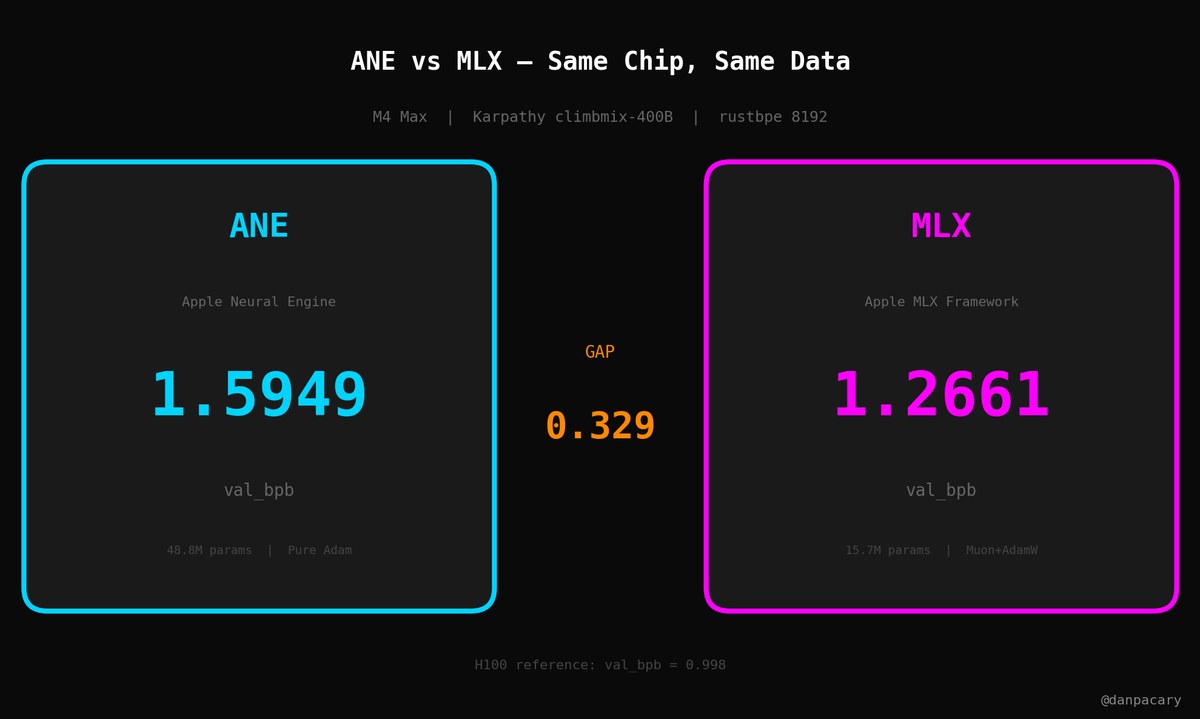
This is part of a bigger project -- we're training the same model on 3 accelerators on the same Mac and benchmarking against Karpathy's H100 baseline (0.998).
ANE ended up with the biggest improvement of the three.
2.227 -> 1.635 val_bpb. 27% improvement. 72K steps in 4.8 hours.
This is part of a bigger project -- we're training the same model on 3 accelerators on the same Mac and benchmarking against Karpathy's H100 baseline (0.998).
ANE ended up with the biggest improvement of the three.
When MLX trains on the GPU, the fans scream. You feel the heat. Activity Monitor shows 97% GPU.
When ANE trains -- silence. Cool to the touch. Invisible to the OS.
And they run at the same time. Two models training on the same MacBook. Zero interference. 50+ hours of compute in about 19 hours wall time.
When ANE trains -- silence. Cool to the touch. Invisible to the OS.
And they run at the same time. Two models training on the same MacBook. Zero interference. 50+ hours of compute in about 19 hours wall time.
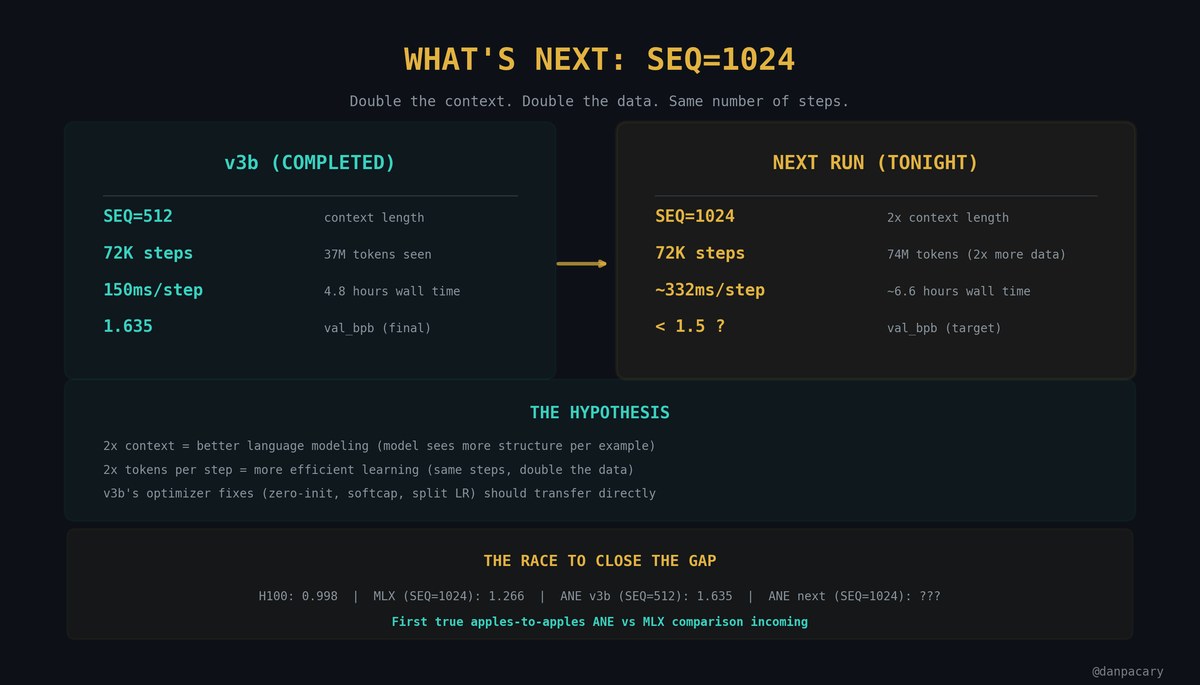
This afternoon: SEQ=1024.
v3b ran at SEQ=512. MLX runs at 1024. Double context = better language modeling.
72K steps at SEQ=1024 = 74M tokens (2x data). Target: sub-1.3.
First real apples-to-apples ANE vs MLX comparison.
Same chip. Same data. Same context length.
check it out .github.com/ncdrone/autoresearch-ANE
v3b ran at SEQ=512. MLX runs at 1024. Double context = better language modeling.
72K steps at SEQ=1024 = 74M tokens (2x data). Target: sub-1.3.
First real apples-to-apples ANE vs MLX comparison.
Same chip. Same data. Same context length.
check it out .github.com/ncdrone/autoresearch-ANE
• • •
Missing some Tweet in this thread? You can try to
force a refresh