
idk what I’m doing half the time. but sometimes I design systems for constrained compute
current curiosity: apple silicon / local ai
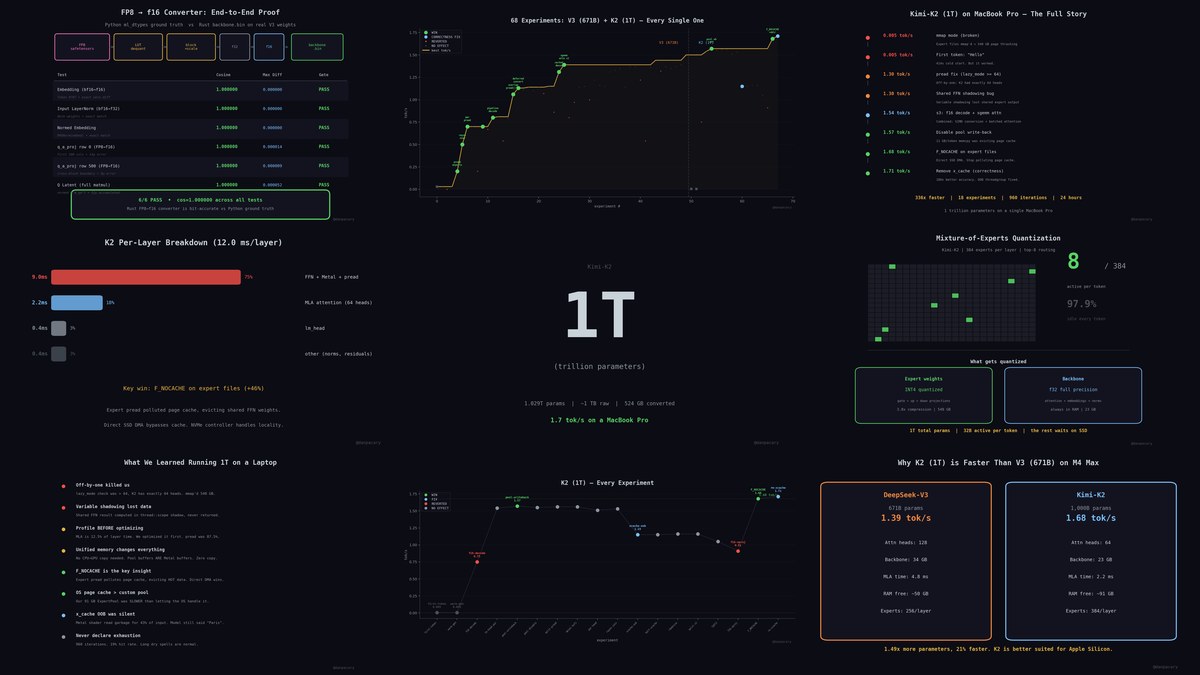 How did we get here?
How did we get here? 
 I built a bash script that runs Claude Opus in headless mode. (sound familiar?)
I built a bash script that runs Claude Opus in headless mode. (sound familiar?)
 Before today, the largest validated ANE training was ~600M params.
Before today, the largest validated ANE training was ~600M params.
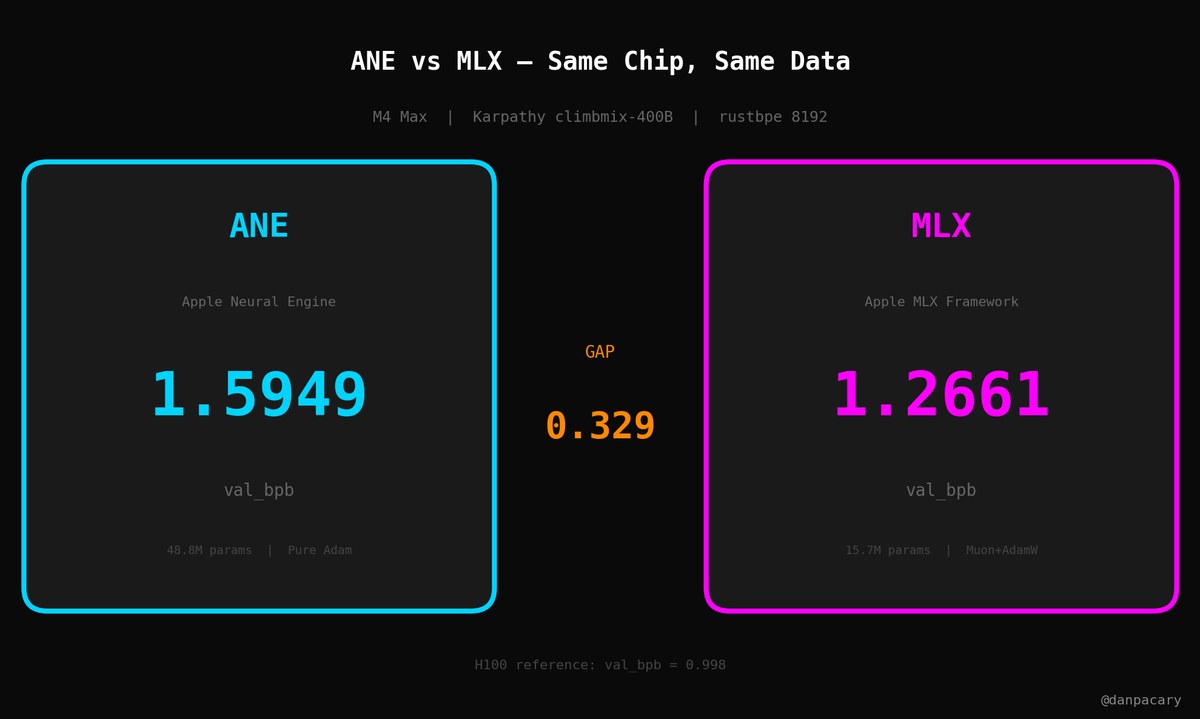 Two very different paths to convergence.
Two very different paths to convergence.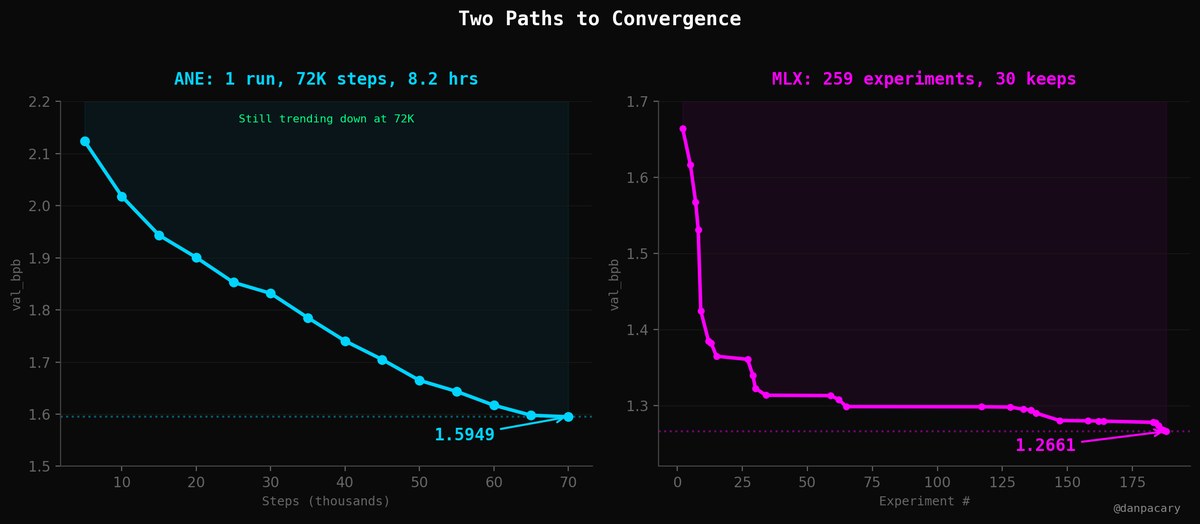
 Apple's Neural Engine is in every Apple Silicon Mac. But Apple never documented it for training -- only inference.
Apple's Neural Engine is in every Apple Silicon Mac. But Apple never documented it for training -- only inference.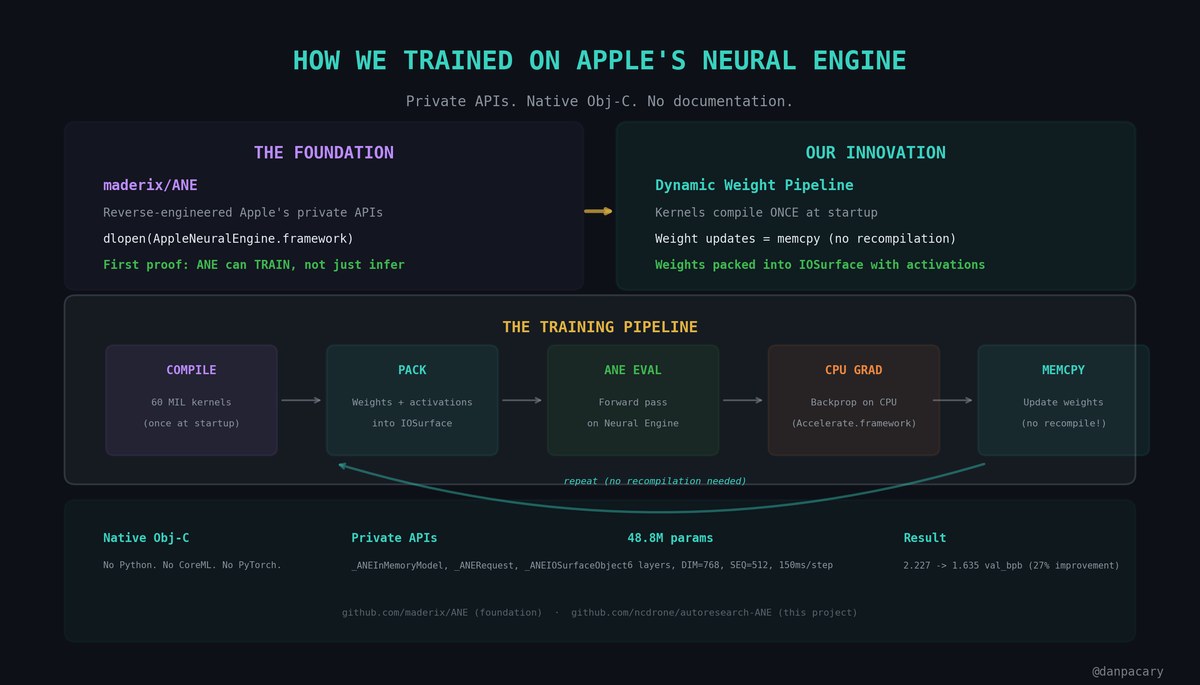
 OpenAI and Apollo Research ran a test.
OpenAI and Apollo Research ran a test.