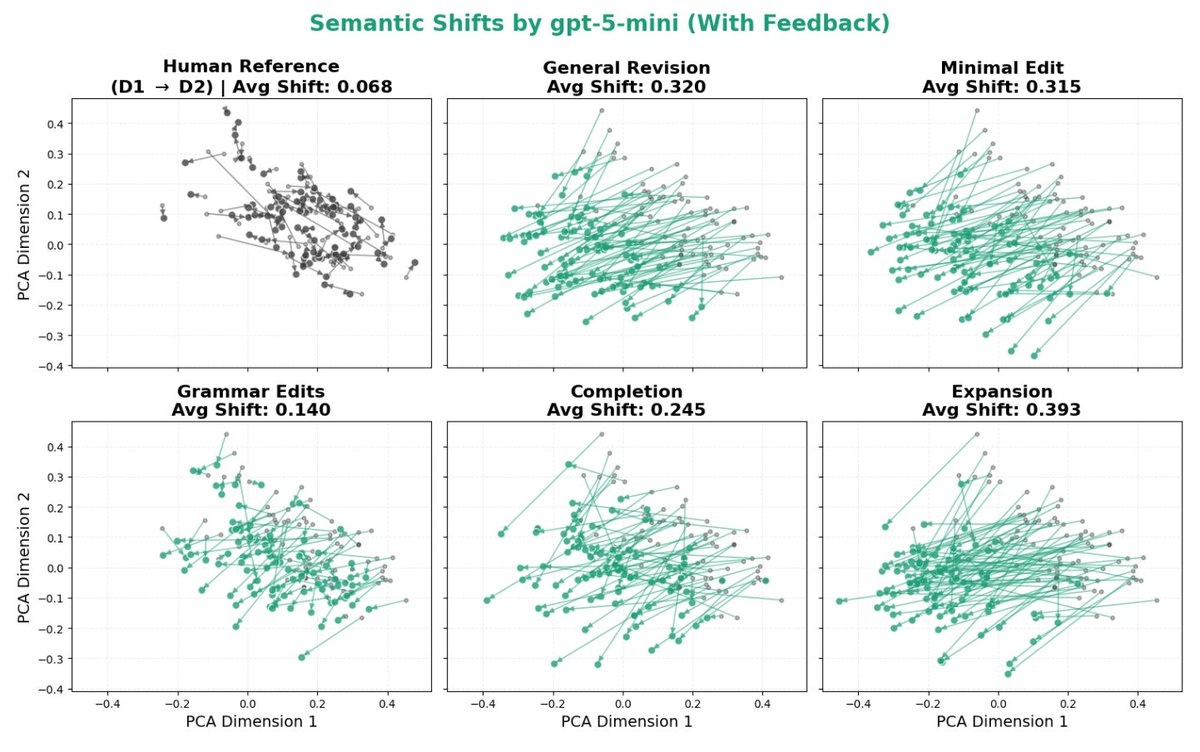
The paper I’ve been most obsessed with lately is finally out: nbcnews.com/tech/tech-news…! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
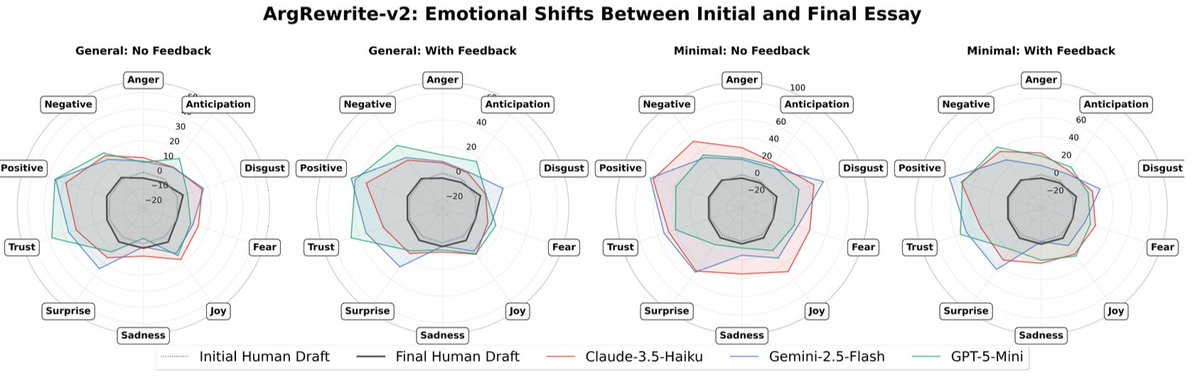
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
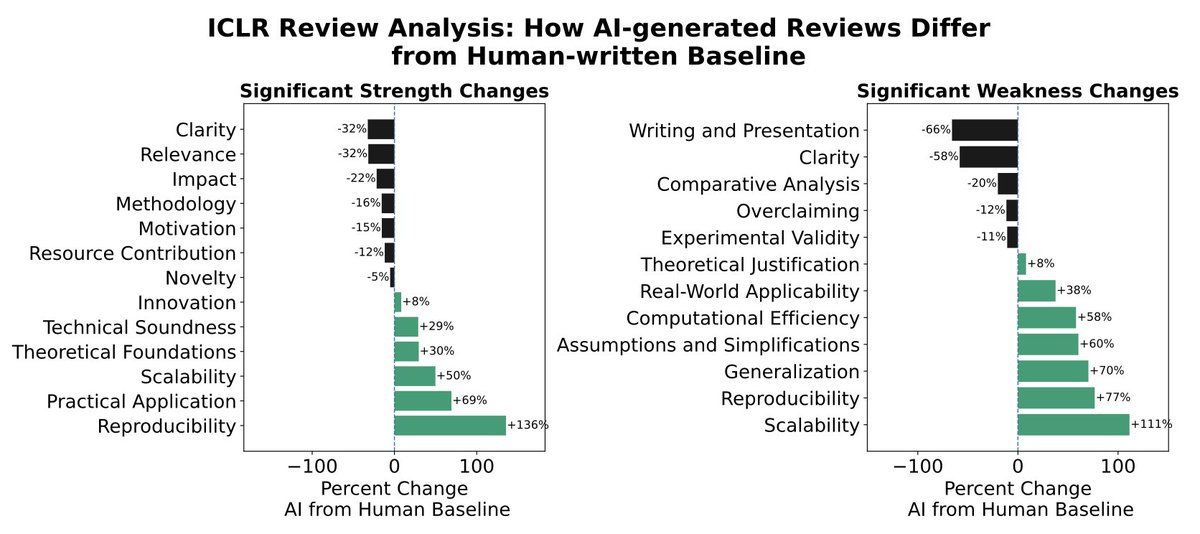
This is a problem, because LLM-generated text is already infiltrating a lot of our cultural and scientific institutions. For example, we look at the 21% of ICLR 2026 reviews that were found to be LLM-generated, and find that they actually focus on different scientific criteria than human reviews! e.g. LLMs increase focus on scalability by +111% vs. humans.
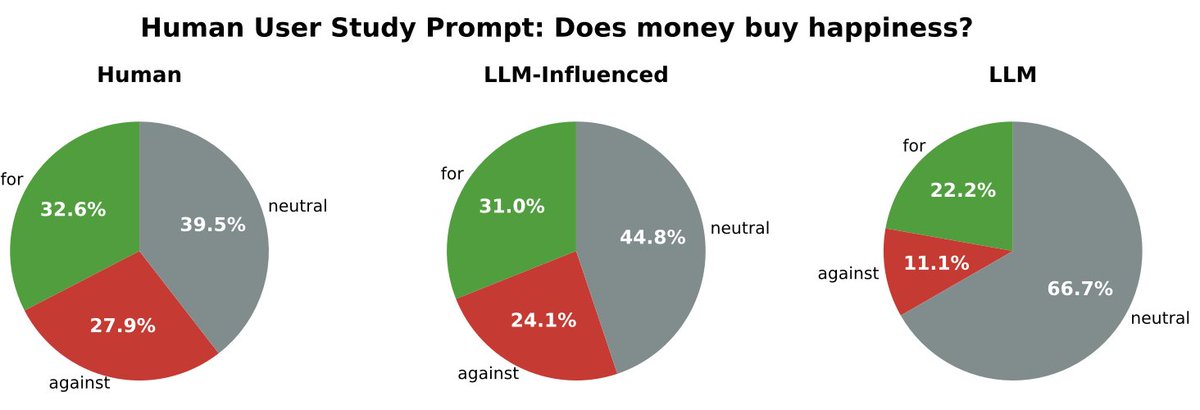
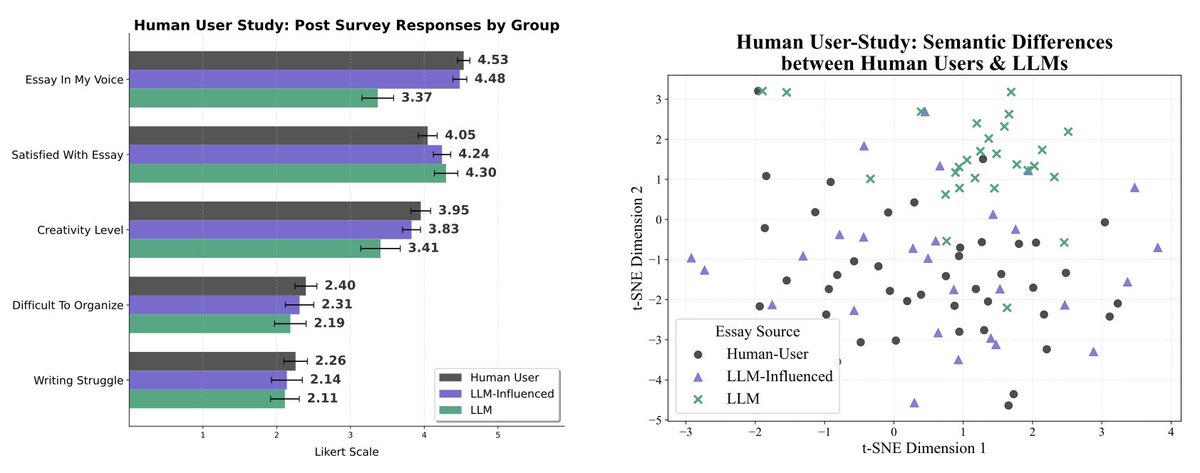
You might say "well, I’m so good at prompting LLMs, I’m not going to be subject to these issues". So, we conduct a human user study to see how people naturally interact with LLMs to produce a piece of writing, and find that even when allowed to repeatedly prompt the LLM to refine an essay as they see fit, people that rely heavily on LLMs produce writing that argues for significantly different conclusions.
So how are LLMs actually changing human writing? Aside from producing a 70% increase in the proportion of essays that take a neutral stance rather than actually expressing an opinion, we find that LLMs generate text that is both more emotional, as well as more analytical, logical, and statistical. What does this mean? My theory is that LLMs trained with RLHF at a large scale end up learning to write in ways that many many people will give a thumbs up to; and this ends up being both emotional and argumentative language. The ‘clickbait’ of language.

Why am I obsessed with this? LLMs do not preserve our intentions or diversity of thought in writing, and they’re already being adopted en masse. More than 1 billion people worldwide use them on a weekly basis. Existing work has shown that for individual scientists, using LLMs to generate papers increases your productivity and impact, even though it constricts science’s overall focus. In our study we show that even though participants who rely on LLMs say their writing is significantly less creative and not in their voice, they are paradoxically equally satisfied with the output. So, the adoption of LLMs is not going to slow any time soon. But it’s already affecting our cultural institutions and the way we conduct science. We urgently need more research into how massive, widespread LLM adoption will affect our science, politics, and culture.
This is joint work with @marwaabdulhai @isadorcw @yanming_wan @jzl86 and @maxhkw.
Project page: sites.google.com/view/llmwritin…
Paper: arxiv.org/abs/2603.18161
Project page: sites.google.com/view/llmwritin…
Paper: arxiv.org/abs/2603.18161
• • •
Missing some Tweet in this thread? You can try to
force a refresh