
Assistant Professor leading the Social RL Lab https://t.co/ykwfJG84Bj @uwcse and Staff Research Scientist at @GoogleAI.
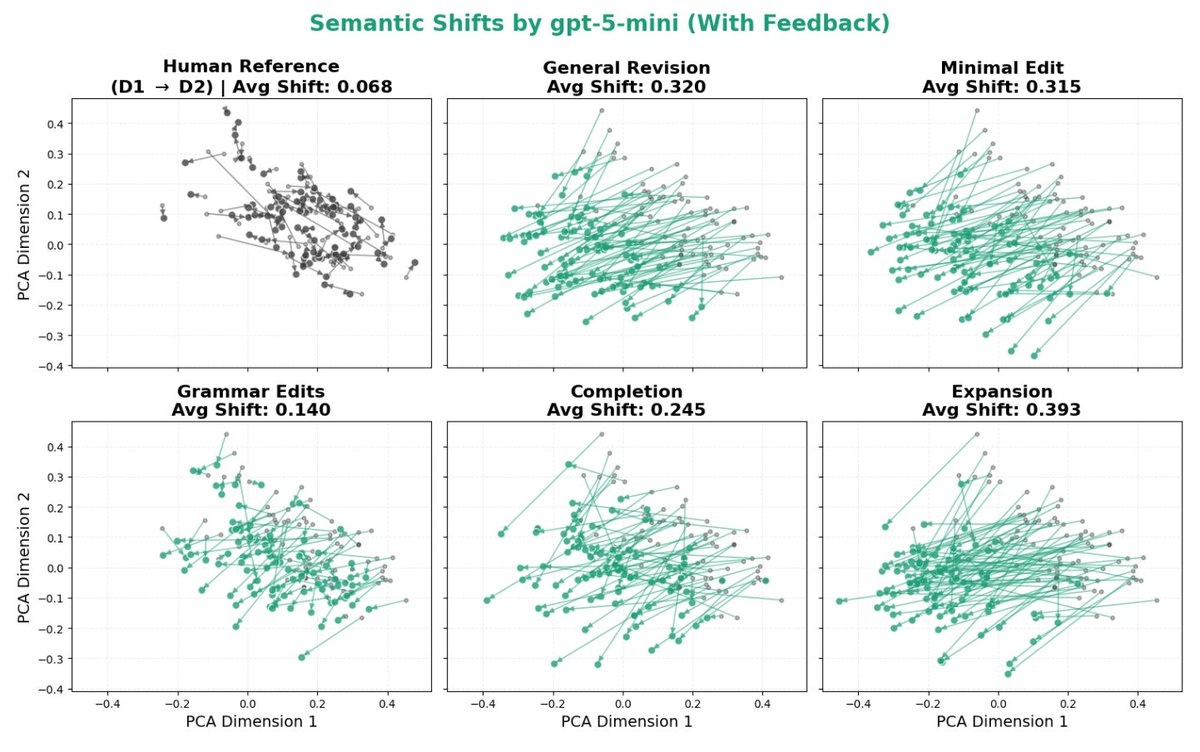 This is a problem, because LLM-generated text is already infiltrating a lot of our cultural and scientific institutions. For example, we look at the 21% of ICLR 2026 reviews that were found to be LLM-generated, and find that they actually focus on different scientific criteria than human reviews! e.g. LLMs increase focus on scalability by +111% vs. humans.
This is a problem, because LLM-generated text is already infiltrating a lot of our cultural and scientific institutions. For example, we look at the 21% of ICLR 2026 reviews that were found to be LLM-generated, and find that they actually focus on different scientific criteria than human reviews! e.g. LLMs increase focus on scalability by +111% vs. humans.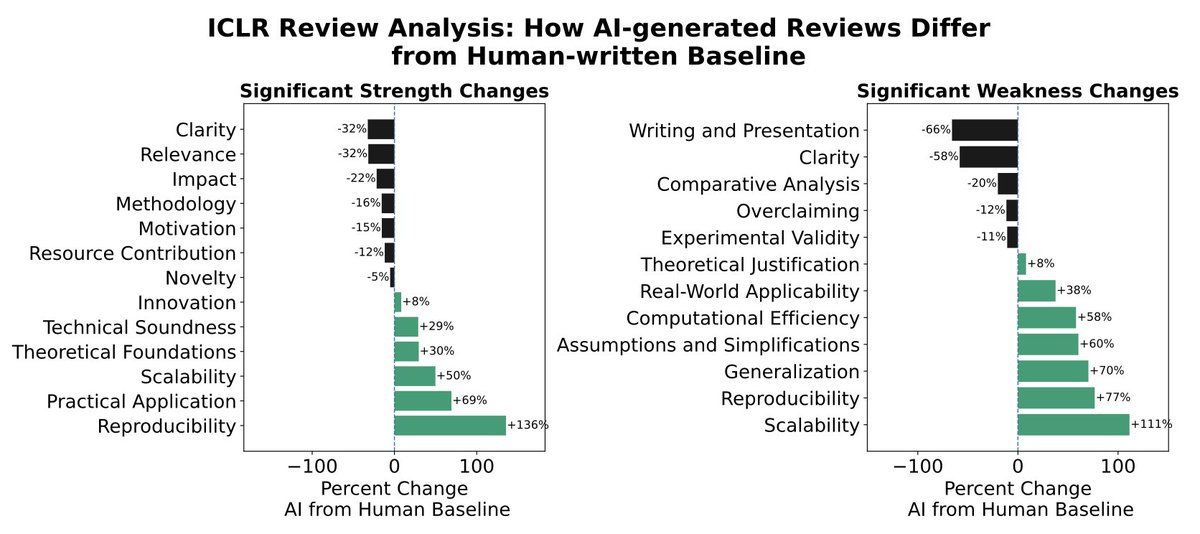

 2) ...by learning from cues like sentiment and conversation length that are implicit in the text itself. We show this is more effective than relying on explicit labeling of human preferences.
2) ...by learning from cues like sentiment and conversation length that are implicit in the text itself. We show this is more effective than relying on explicit labeling of human preferences.