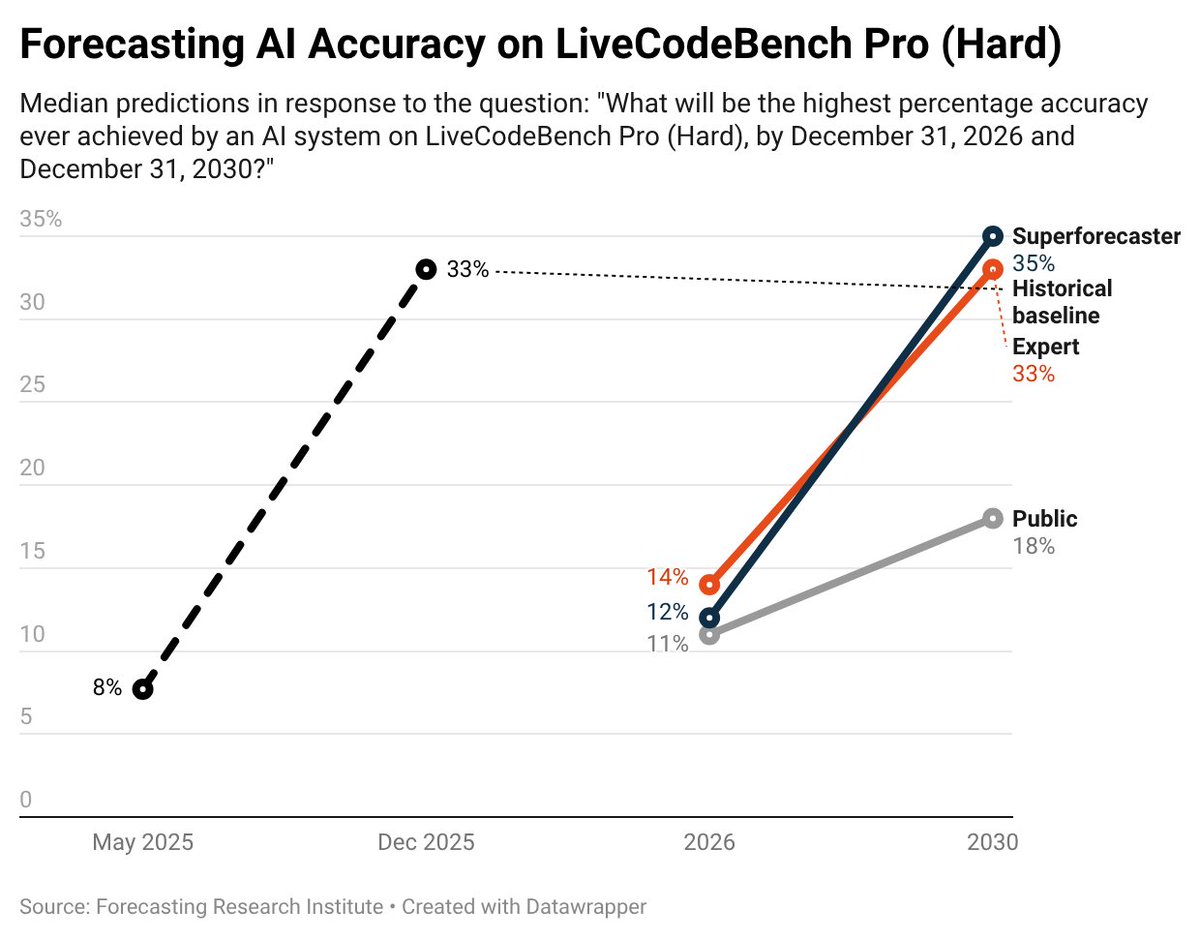
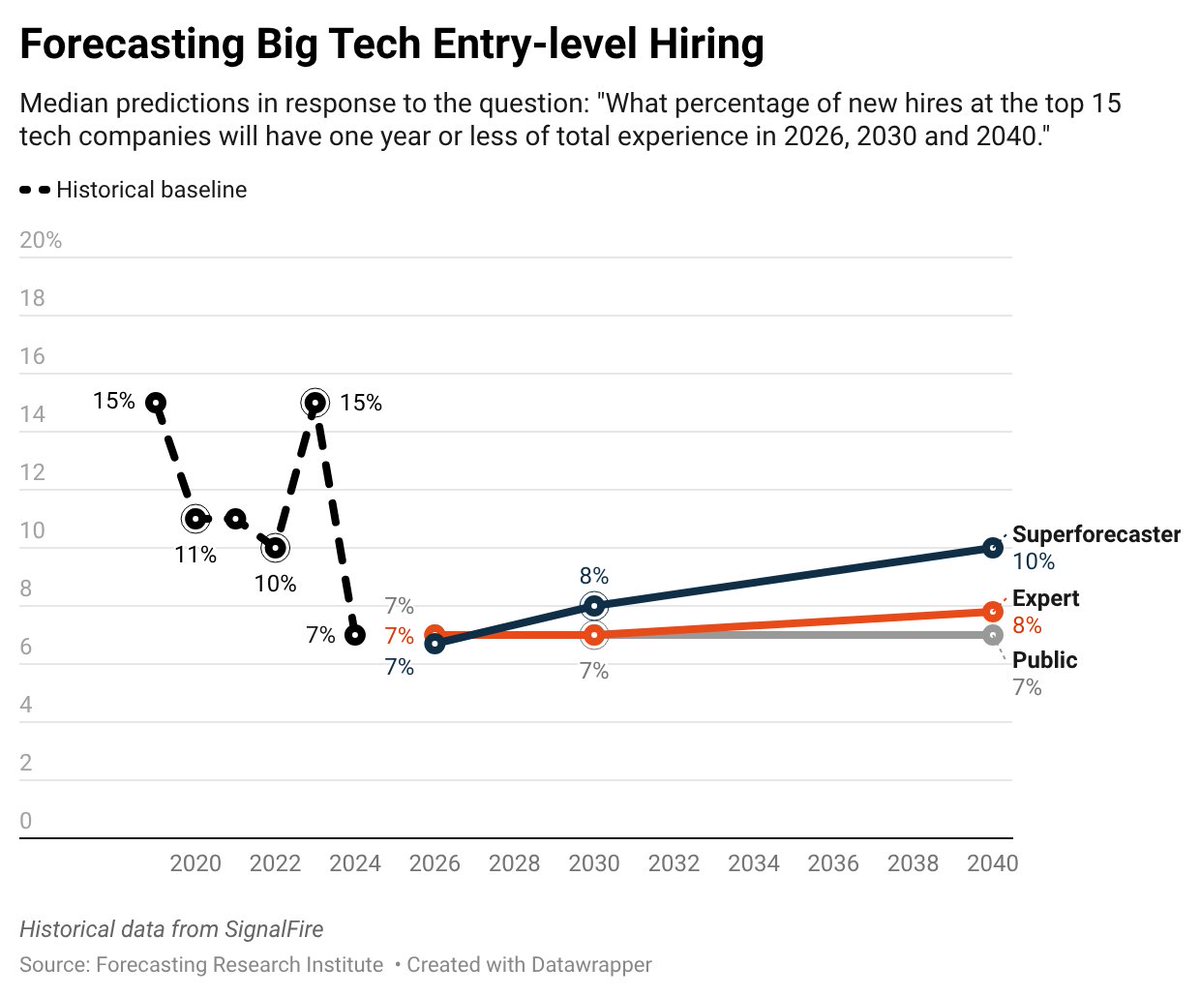
We completed the most comprehensive study of how economists and AI experts think AI will affect the U.S. economy.
They predict major AI progress—but no dramatic break from economic trends: GDP growth rates similar to today's and a moderate decline in labor force participation.
However, when asked to consider what would happen in a world with extremely rapid progress in AI capabilities by 2030, they predict significant economic impacts by 2050:
• Annualized GDP growth of 3.5% (compared to 2.4% in 2025)
• A labor force participation rate of 55% (roughly 10 million fewer jobs)
• 80% of wealth held by the top 10% (highest since 1939)
🧵 Here's what we found:
They predict major AI progress—but no dramatic break from economic trends: GDP growth rates similar to today's and a moderate decline in labor force participation.
However, when asked to consider what would happen in a world with extremely rapid progress in AI capabilities by 2030, they predict significant economic impacts by 2050:
• Annualized GDP growth of 3.5% (compared to 2.4% in 2025)
• A labor force participation rate of 55% (roughly 10 million fewer jobs)
• 80% of wealth held by the top 10% (highest since 1939)
🧵 Here's what we found:

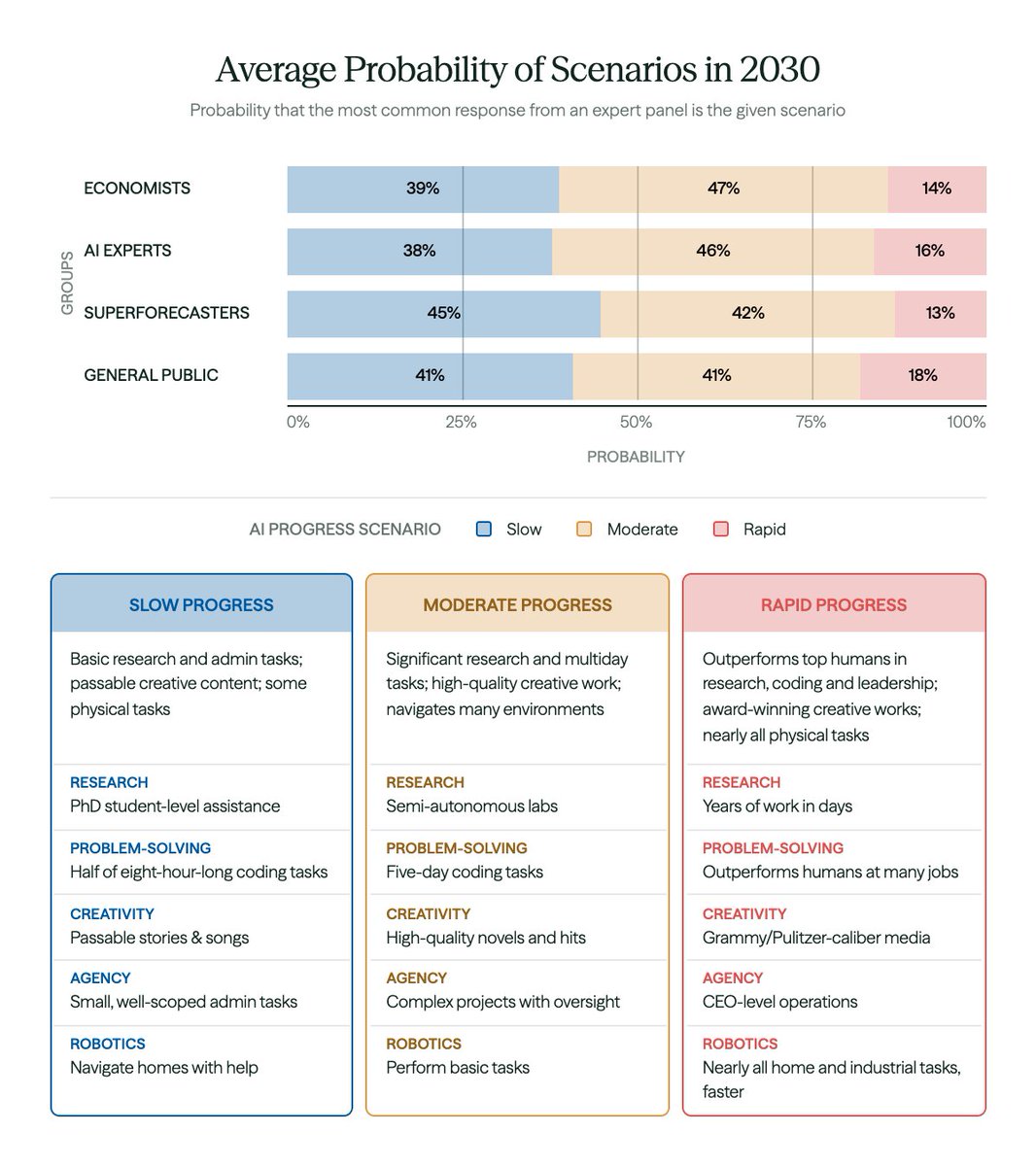
Economists expect substantial AI progress by 2030.
When asked to assign probabilities to slow, moderate, and rapid AI progress scenarios, they predict a:
• 39% chance of a slow progress scenario
• 47% chance of a moderate progress scenario
• 14% chance of a rapid progress scenario
Economists’ 61% chance of moderate or rapid AI progress by 2030 is roughly in line with other respondent groups (AI experts, superforecasters, and the general public).
As you can see below, even moderate progress is a significant advance from present-day AI capabilities.
When asked to assign probabilities to slow, moderate, and rapid AI progress scenarios, they predict a:
• 39% chance of a slow progress scenario
• 47% chance of a moderate progress scenario
• 14% chance of a rapid progress scenario
Economists’ 61% chance of moderate or rapid AI progress by 2030 is roughly in line with other respondent groups (AI experts, superforecasters, and the general public).
As you can see below, even moderate progress is a significant advance from present-day AI capabilities.
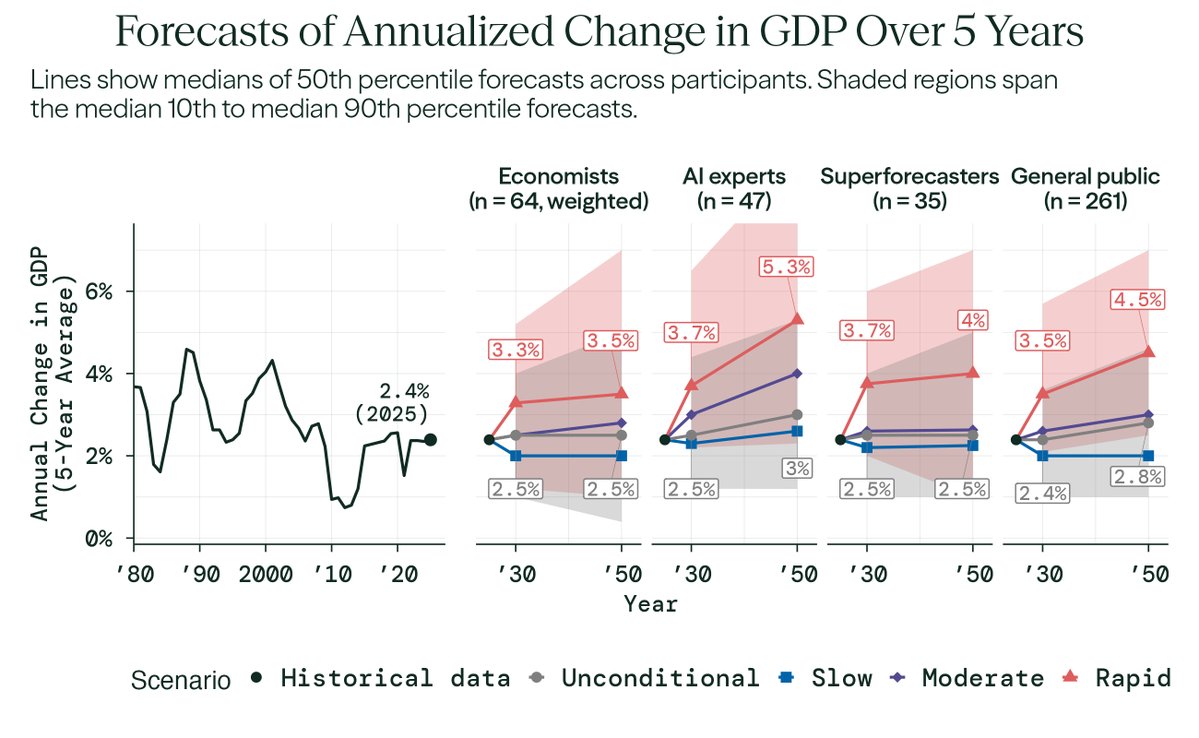
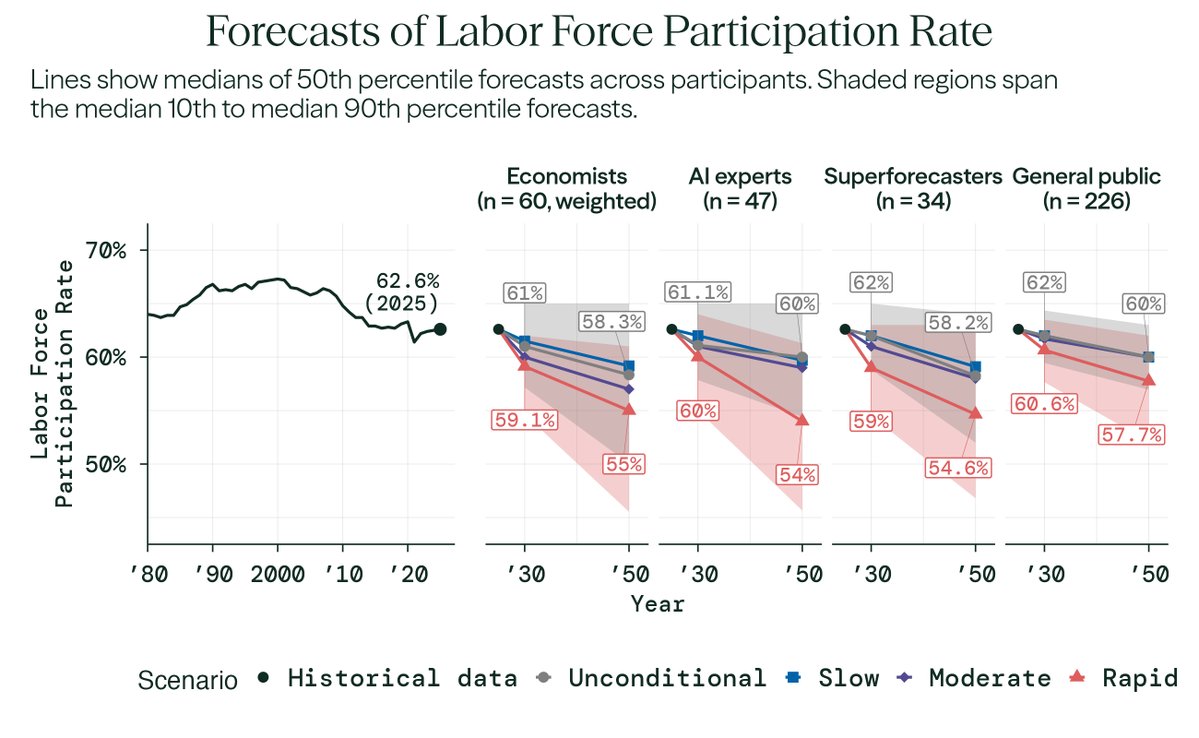
Despite expecting significant AI progress, economists' overall (unconditional) forecasts for the economy stay close to today's trends.
Median economist forecasts:
• Annual GDP growth: 2.5% in 2030 and 2050 (compared to 2.4% in 2025)
• Labor force participation rate: 61% in 2030, 58% in 2050 (compared to 62.6% in 2025)
But, in a ‘rapid’ AI progress world, economists expect larger shifts (see red lines in figures below).
Median economist forecasts:
• Annual GDP growth: 2.5% in 2030 and 2050 (compared to 2.4% in 2025)
• Labor force participation rate: 61% in 2030, 58% in 2050 (compared to 62.6% in 2025)
But, in a ‘rapid’ AI progress world, economists expect larger shifts (see red lines in figures below).


What explains economists giving a high chance of substantial AI progress, yet having an overall belief that economic outcomes won’t shift dramatically?
In their written rationales, economists cited the following reasons:
• slow and uneven diffusion of AI across sectors
• infrastructure bottlenecks (energy, chips, data centers)
• demographic and geopolitical headwinds
• long lags between the discovery of general-purpose technologies and measured productivity gains
The median view is closer to "AI will take a long time to show up in macroeconomic statistics and will offset demographic headwinds" than "AI won't matter at all."
In their written rationales, economists cited the following reasons:
• slow and uneven diffusion of AI across sectors
• infrastructure bottlenecks (energy, chips, data centers)
• demographic and geopolitical headwinds
• long lags between the discovery of general-purpose technologies and measured productivity gains
The median view is closer to "AI will take a long time to show up in macroeconomic statistics and will offset demographic headwinds" than "AI won't matter at all."

Economists' median forecast of 2.5% annualized GDP growth by 2030 is still higher than most comparable forecasts used by government agencies and the private sector, which tend to be closer to 2%.
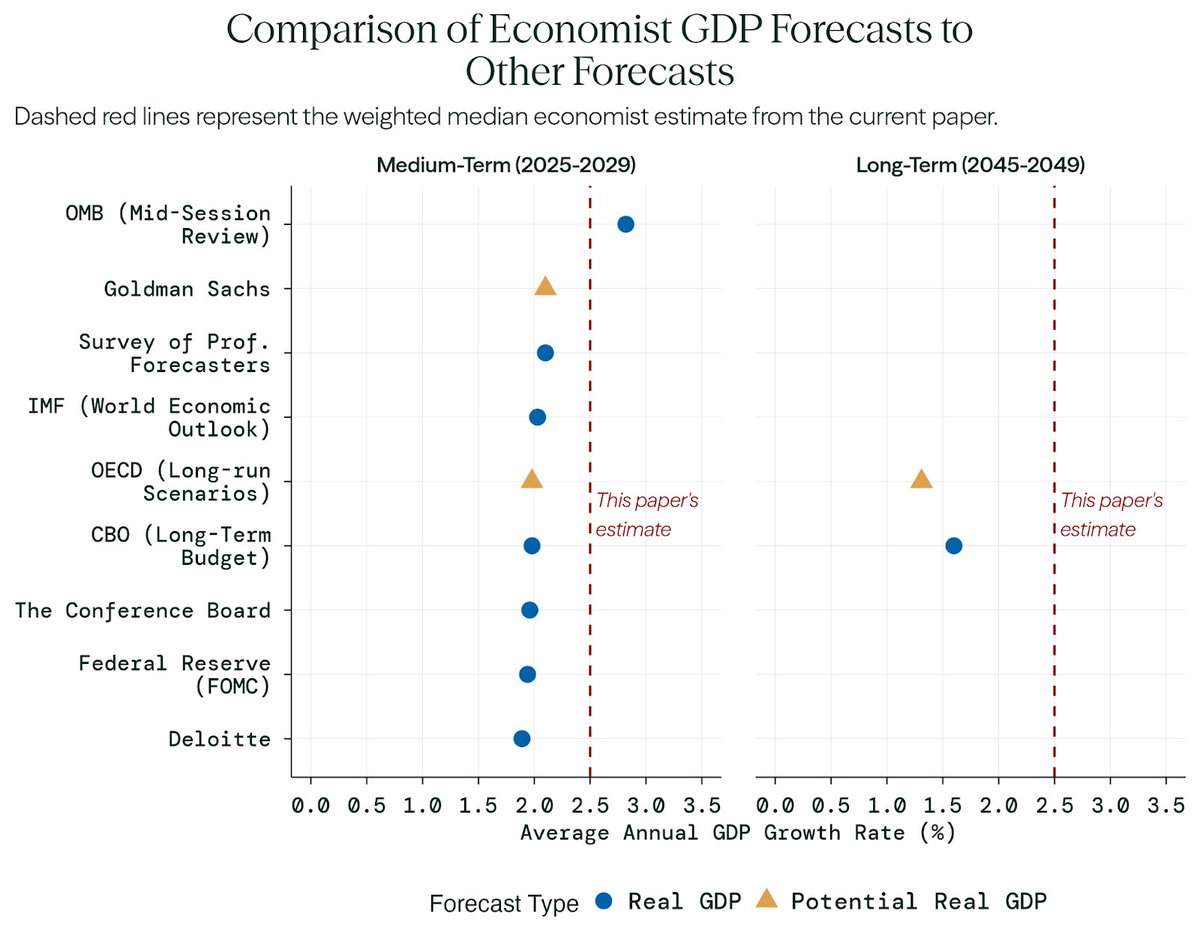
In a rapid AI progress scenario—which economists assigned a 14% probability to—economists expect much larger effects:
• Annual GDP growth: 3.3% in 2030, 3.5% in 2050 (roughly comparable to 1992–2001)
• Total factor productivity growth: 2% in 2030, 2.5% in 2050 (close to post-WWII levels)
• Labor force participation rate: 59% in 2030, 55% in 2050 (lower than in the 1950s)
That’s a richer economy, but also one where many fewer people work.
• Annual GDP growth: 3.3% in 2030, 3.5% in 2050 (roughly comparable to 1992–2001)
• Total factor productivity growth: 2% in 2030, 2.5% in 2050 (close to post-WWII levels)
• Labor force participation rate: 59% in 2030, 55% in 2050 (lower than in the 1950s)
That’s a richer economy, but also one where many fewer people work.
Impacts on wealth inequality show similar patterns.
In the rapid scenario, economists expect the top 10% of households to hold:
• 75% of U.S. wealth in 2030
• 80% in 2050
In the rapid scenario, economists expect the top 10% of households to hold:
• 75% of U.S. wealth in 2030
• 80% in 2050
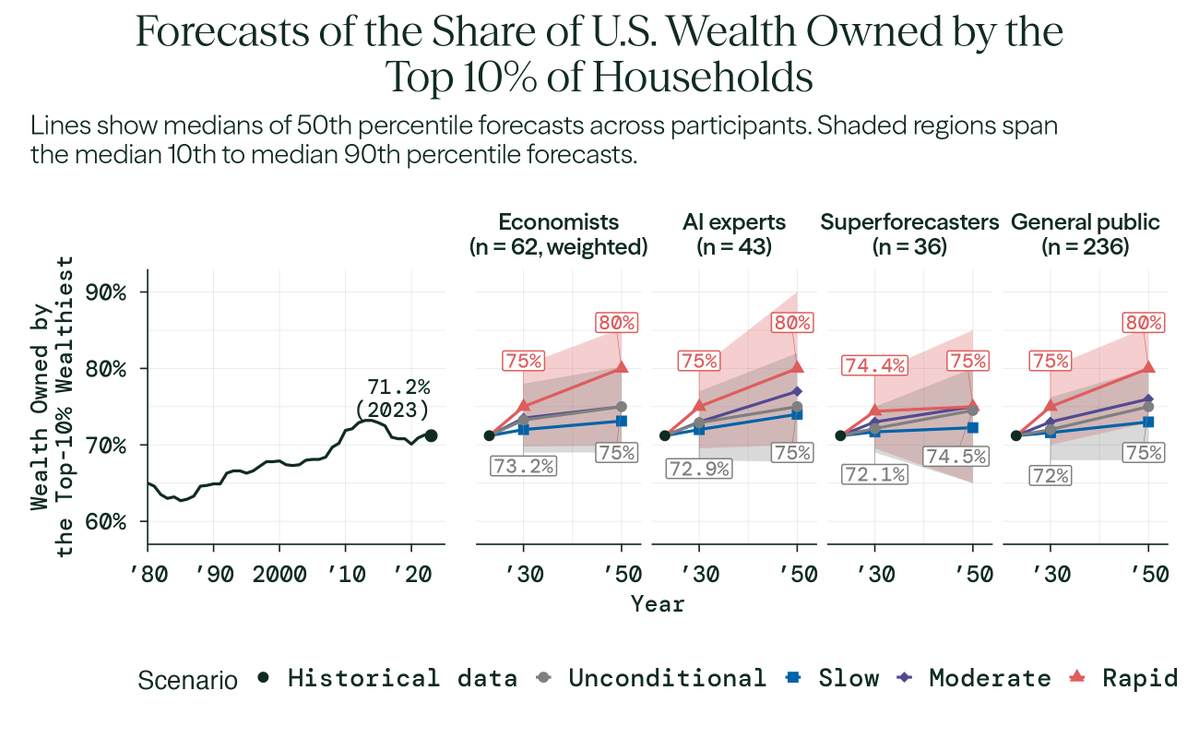
Compounded over decades, small differences in GDP growth can produce large differences in prosperity.
Economists’ forecast of 3.5% annual growth rate in the rapid scenario would lead to U.S. economic output of $54.7 trillion in 2050 (real GDP), 25% larger than the $43.7 trillion in the unconditional scenario, where economists predict a 2.5% annual growth rate.
This is roughly equivalent to the difference in U.S. GDP (economic output) between 2016 and today.
Economists’ forecast of 3.5% annual growth rate in the rapid scenario would lead to U.S. economic output of $54.7 trillion in 2050 (real GDP), 25% larger than the $43.7 trillion in the unconditional scenario, where economists predict a 2.5% annual growth rate.
This is roughly equivalent to the difference in U.S. GDP (economic output) between 2016 and today.
Most expert disagreement isn't about whether we get powerful AI systems—it's about what powerful AI systems would do to the economy.
For economists' 2030 GDP growth forecasts:
• 78.7% of the total variation in forecasts is driven by the uncertainty that each economist has about what will happen in a given scenario;
• 16.1% of the total variance is driven by disagreement about economic outcomes conditional on a given level of AI progress;
• Only 5.2% of the variance is between scenarios—attributable to disagreement about AI capabilities themselves, as described by our (imperfect) scenarios.
We see similar patterns for all other outcomes, and across expert groups.
For economists' 2030 GDP growth forecasts:
• 78.7% of the total variation in forecasts is driven by the uncertainty that each economist has about what will happen in a given scenario;
• 16.1% of the total variance is driven by disagreement about economic outcomes conditional on a given level of AI progress;
• Only 5.2% of the variance is between scenarios—attributable to disagreement about AI capabilities themselves, as described by our (imperfect) scenarios.
We see similar patterns for all other outcomes, and across expert groups.

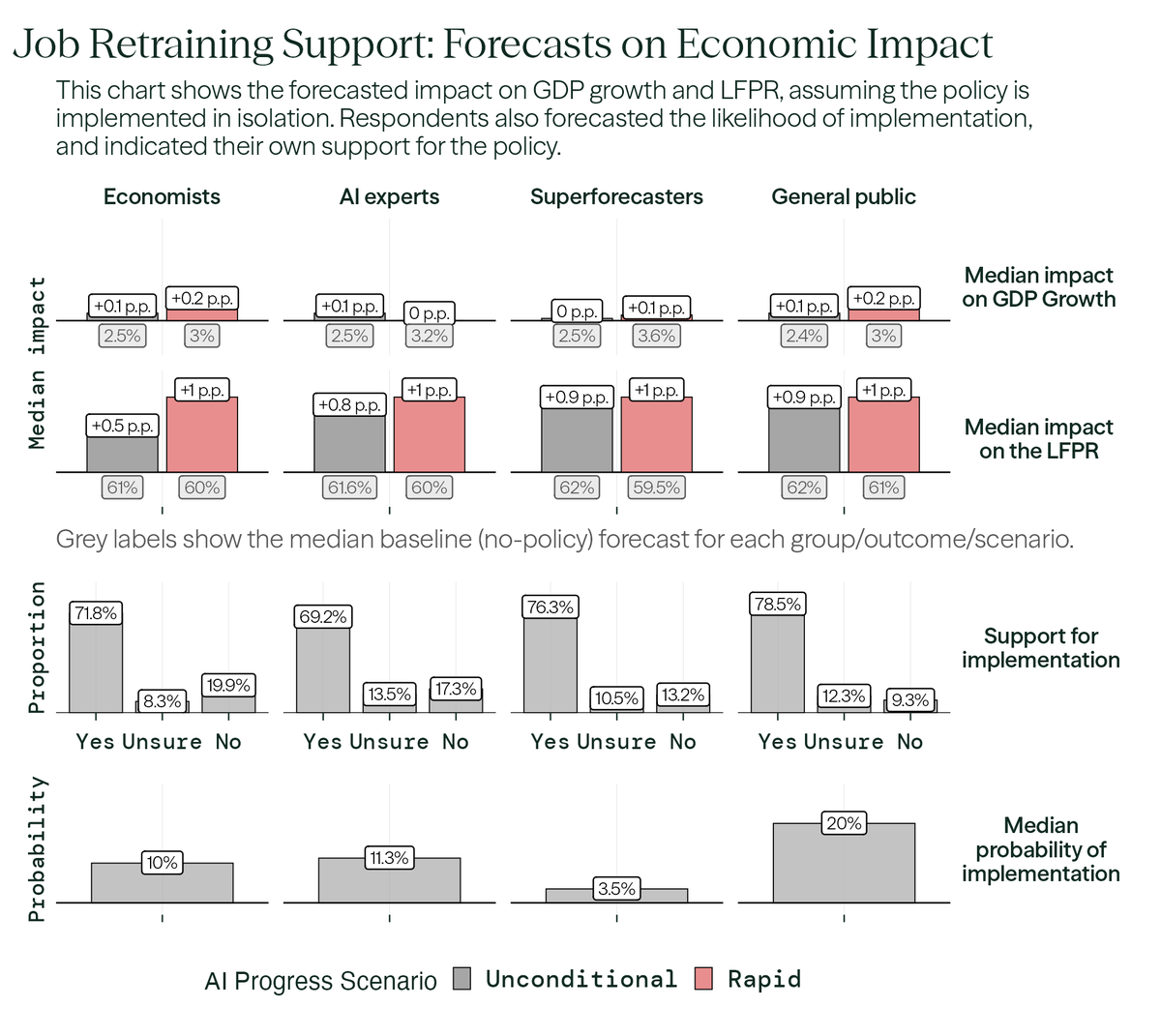
We also asked economists what they thought of six policies that might address the impact of rapid AI progress.
Economists strongly favor targeted measures such as worker retraining, whereas the general public supports both targeted programs and broader interventions, including a job guarantee and universal basic income.
The most favored policy across all respondent groups was retraining support, which economists estimated would lead to a +0.2 p.p. increase in annual GDP growth and a +1 p.p. increase in LFPR in a world with rapid AI progress.
Economists strongly favor targeted measures such as worker retraining, whereas the general public supports both targeted programs and broader interventions, including a job guarantee and universal basic income.
The most favored policy across all respondent groups was retraining support, which economists estimated would lead to a +0.2 p.p. increase in annual GDP growth and a +1 p.p. increase in LFPR in a world with rapid AI progress.

Thank you to all of our coauthors: @EzraKarger, Otto Kuusela, @Jabaluck, @Afinetheorem, @BasilHalperin, @toddrjones, @connacher_, @pawtrammell, @mattsreynolds1, @danmayland, Ria Viswanathan, Ananaya Mittal, Rebecca Ceppas de Castro, Josh Rosenberg, and @PTetlock
For full results, including the impact on sectors and occupations, read our full paper here: forecastingresearch.org/s/forecasting-…
For a summary of the results, see our policy briefing here: forecastingresearch.org/s/forecasting-…
And visit our Substack: forecastingresearch.substack.com/forecasting-th…
For full results, including the impact on sectors and occupations, read our full paper here: forecastingresearch.org/s/forecasting-…
For a summary of the results, see our policy briefing here: forecastingresearch.org/s/forecasting-…
And visit our Substack: forecastingresearch.substack.com/forecasting-th…
We built a tool so that you can compare your own forecasts on AI’s economic impact to economists’ forecasts:
explore.forecastingresearch.org/participate/ee…
We hope this can be a useful tool for informing discourse on the economic impacts of AI. When you submit your forecasts, you will get a shareable image that compares your predictions to economists’ predictions. See example image below.
explore.forecastingresearch.org/participate/ee…
We hope this can be a useful tool for informing discourse on the economic impacts of AI. When you submit your forecasts, you will get a shareable image that compares your predictions to economists’ predictions. See example image below.

• • •
Missing some Tweet in this thread? You can try to
force a refresh