
We advance the science of forecasting to improve decision-making on high stakes issues. Co-founded by chief scientist Philip Tetlock.
 1️⃣Experts and superforecasters think a major AI-driven harm event is more likely than not by 2050
1️⃣Experts and superforecasters think a major AI-driven harm event is more likely than not by 2050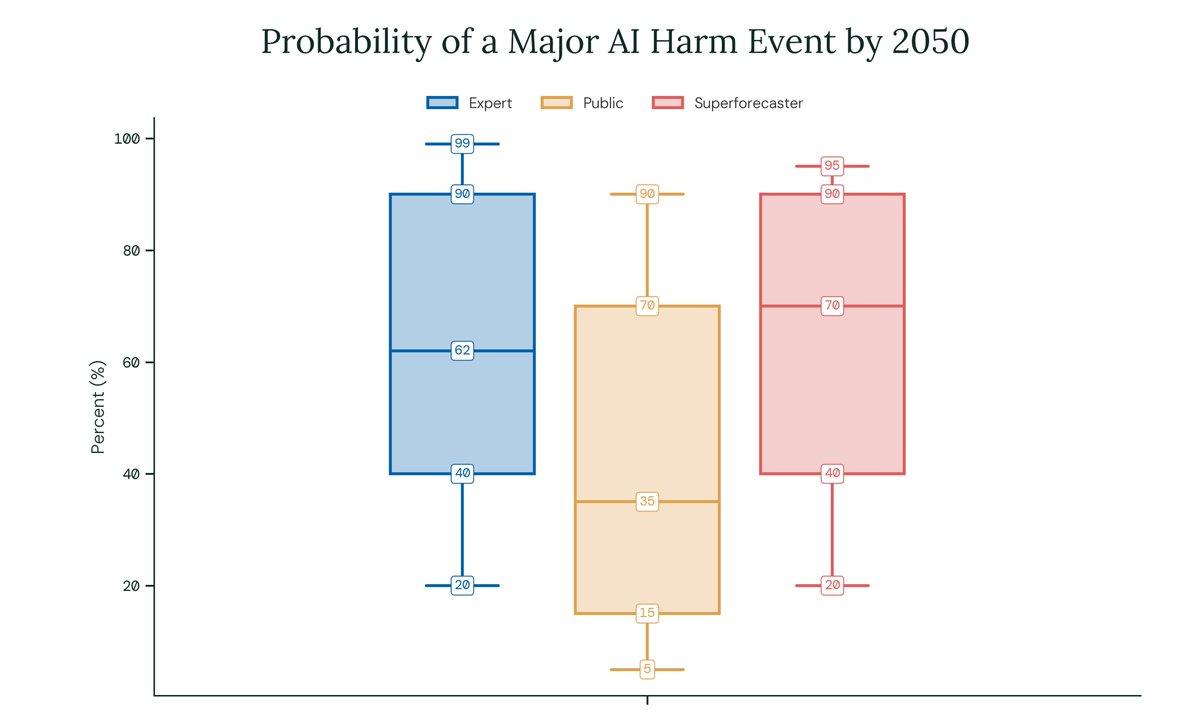
 ✍️ Good forecasts often come with rationales—written explanations of the reasoning behind a number.
✍️ Good forecasts often come with rationales—written explanations of the reasoning behind a number.
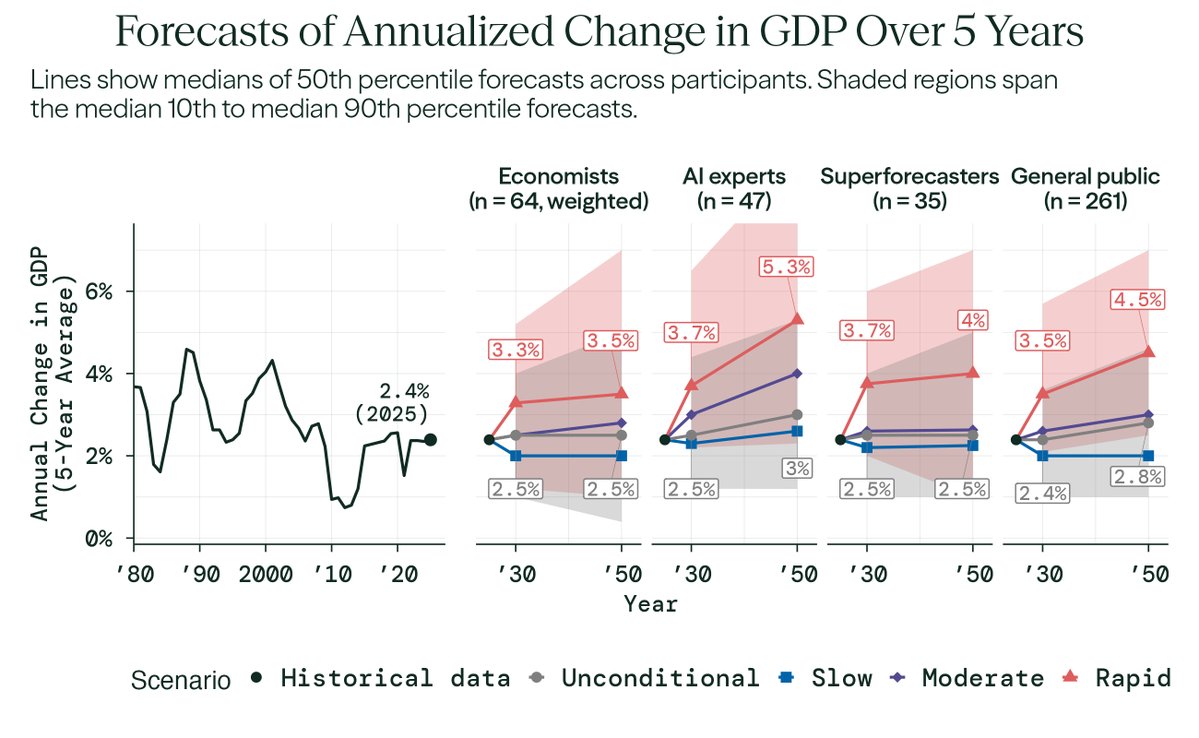 Economists expect substantial AI progress by 2030.
Economists expect substantial AI progress by 2030.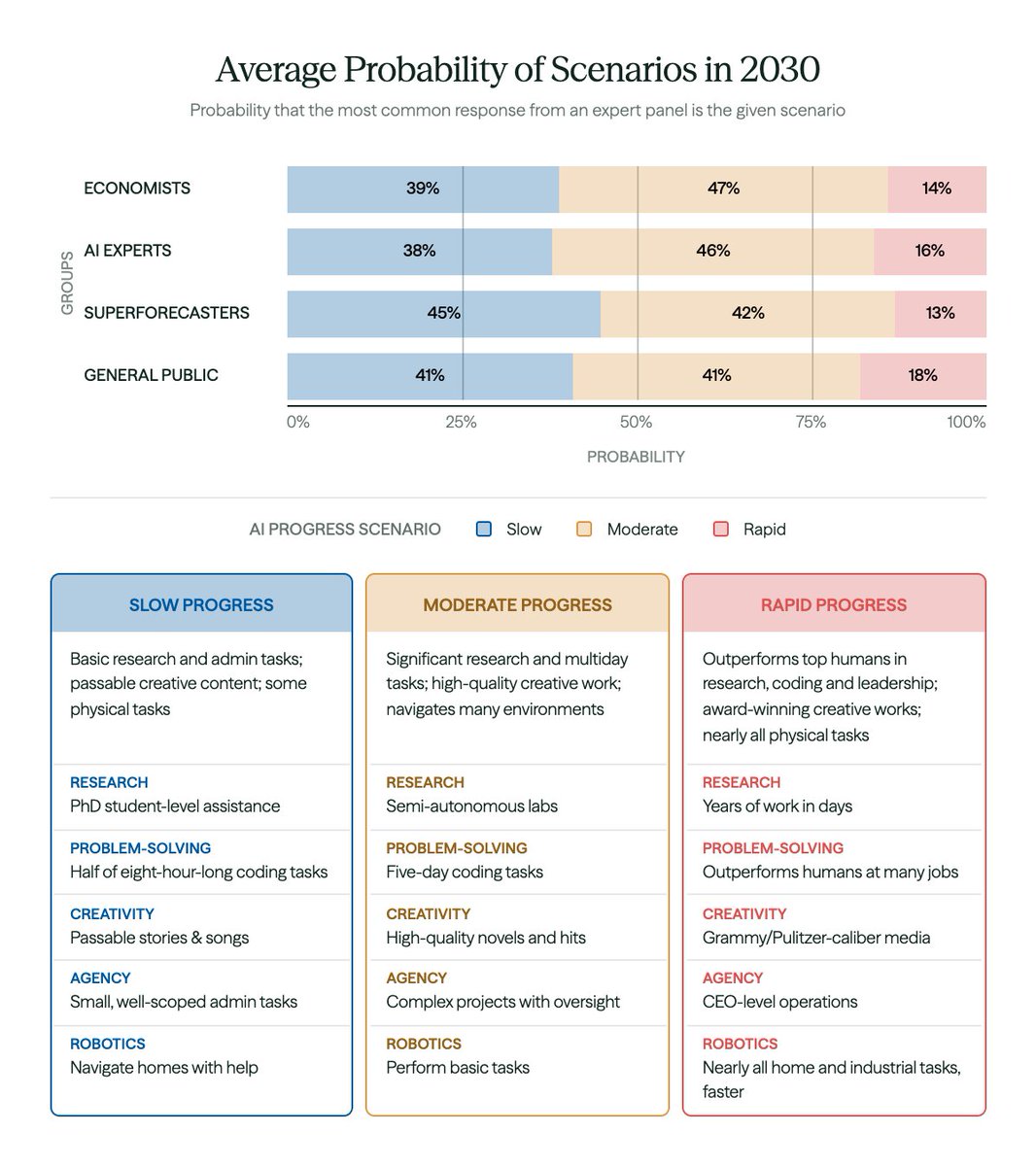
 📈 AI benchmark progress is advancing faster than experts expect
📈 AI benchmark progress is advancing faster than experts expect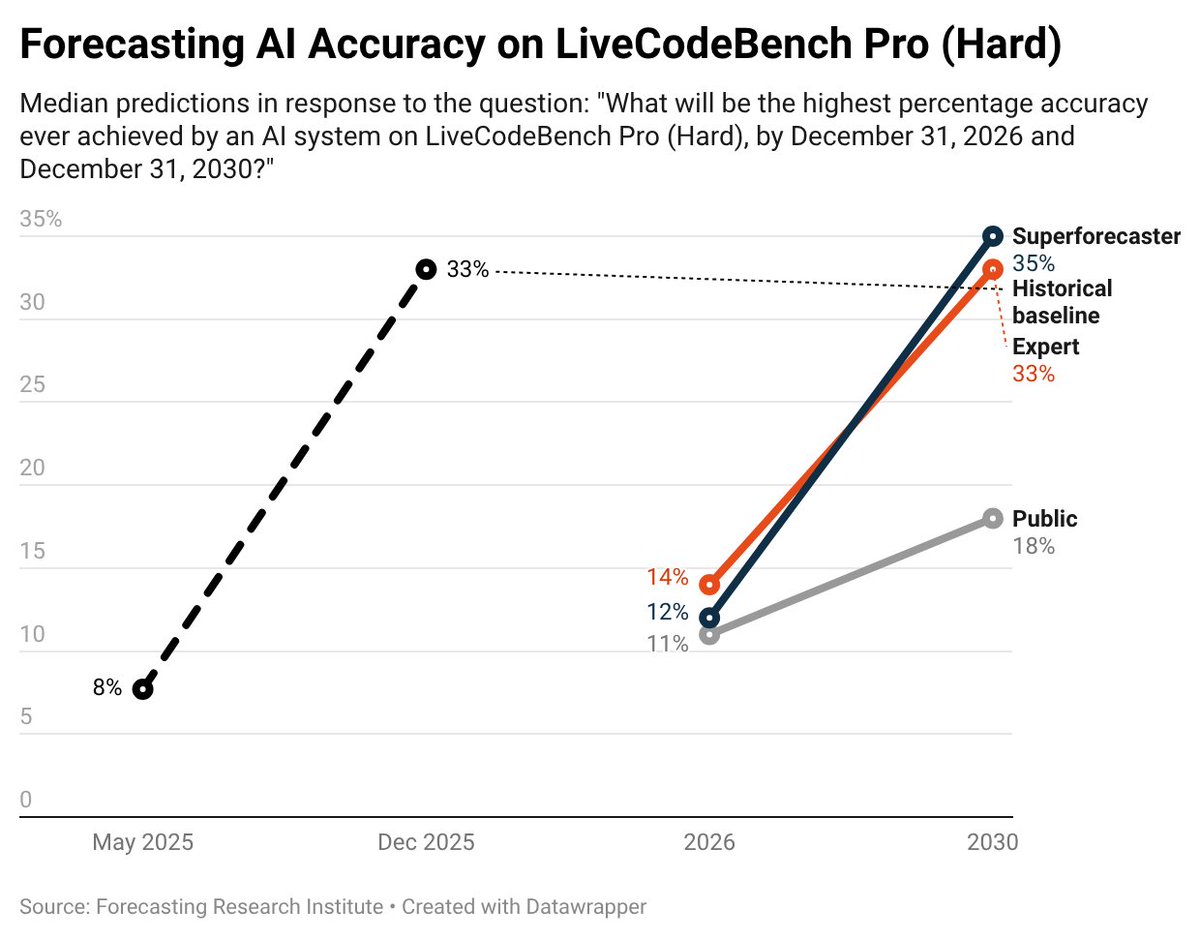
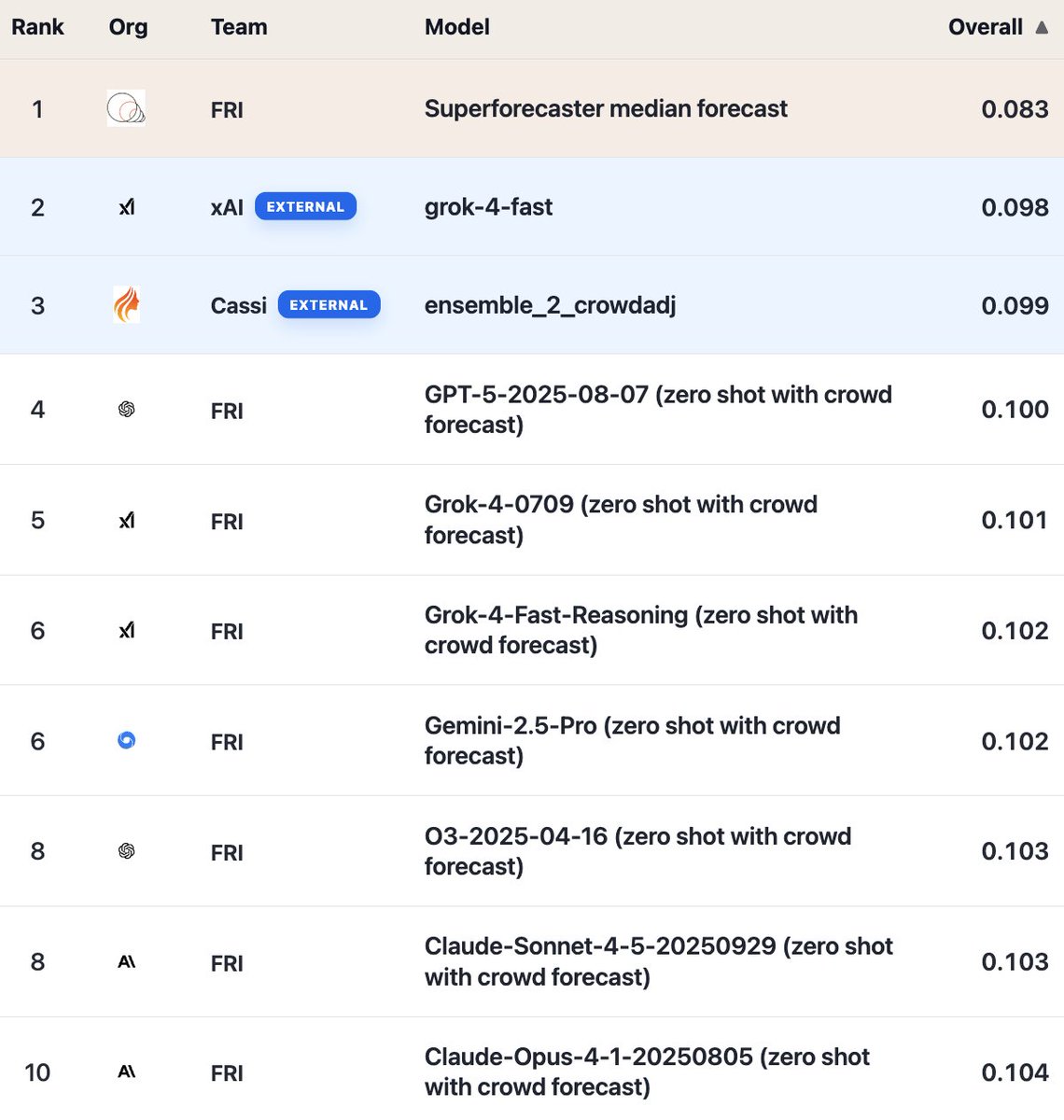 In October, we opened up ForecastBench’s tournament leaderboard to external submissions. Teams are free to use any tools they choose.
In October, we opened up ForecastBench’s tournament leaderboard to external submissions. Teams are free to use any tools they choose.

 Our LEAP panel is made up of the following experts:
Our LEAP panel is made up of the following experts: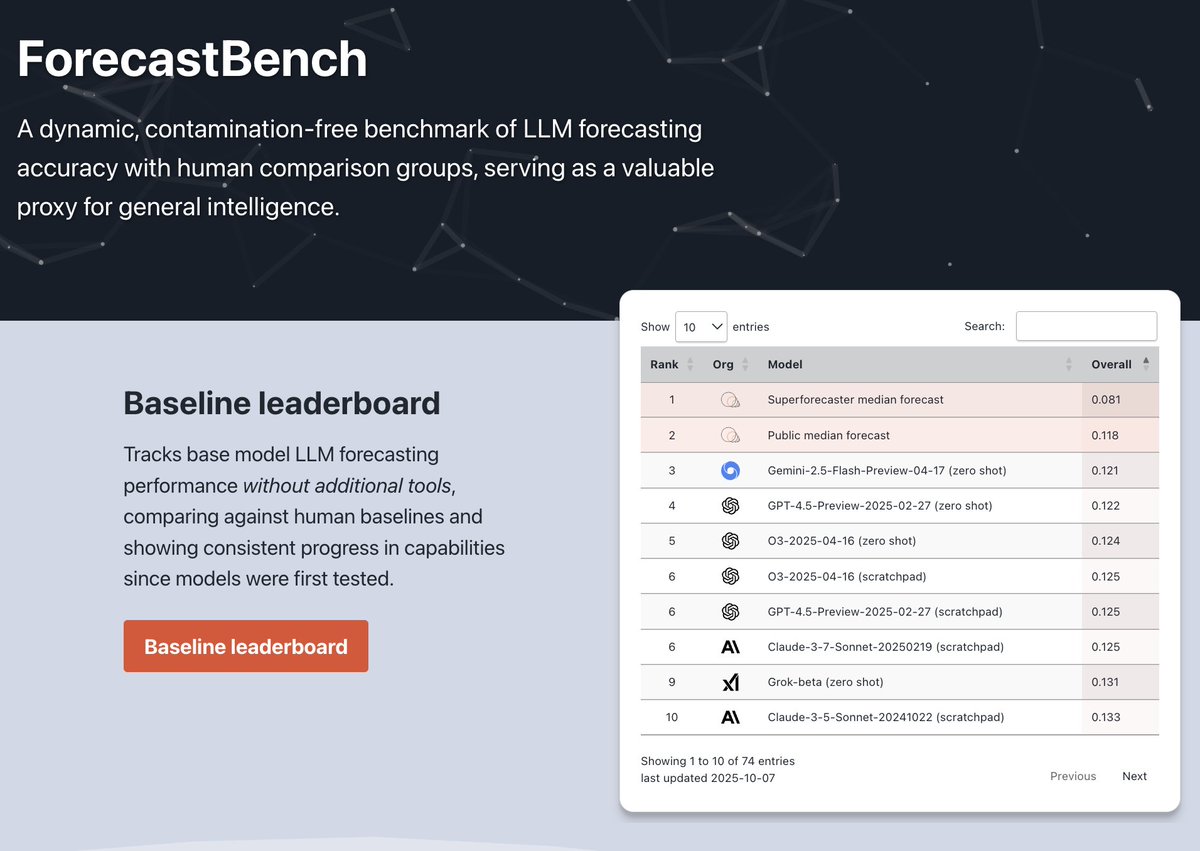 Why LLM forecasting accuracy is a useful benchmark:
Why LLM forecasting accuracy is a useful benchmark: Respondents—especially superforecasters—underestimated AI progress.
Respondents—especially superforecasters—underestimated AI progress.
