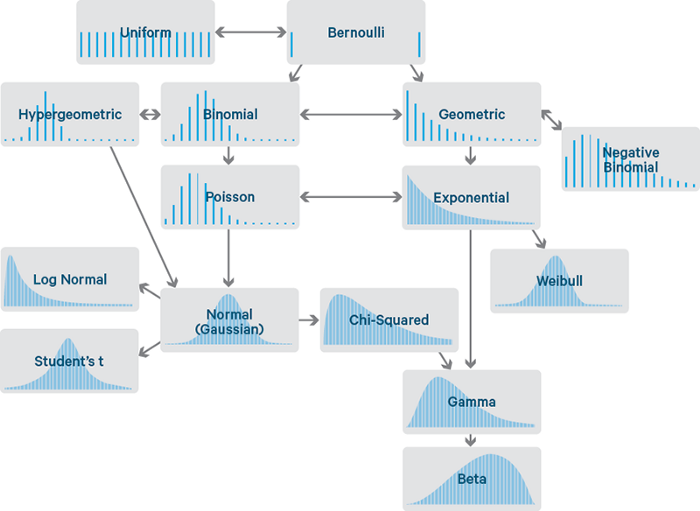
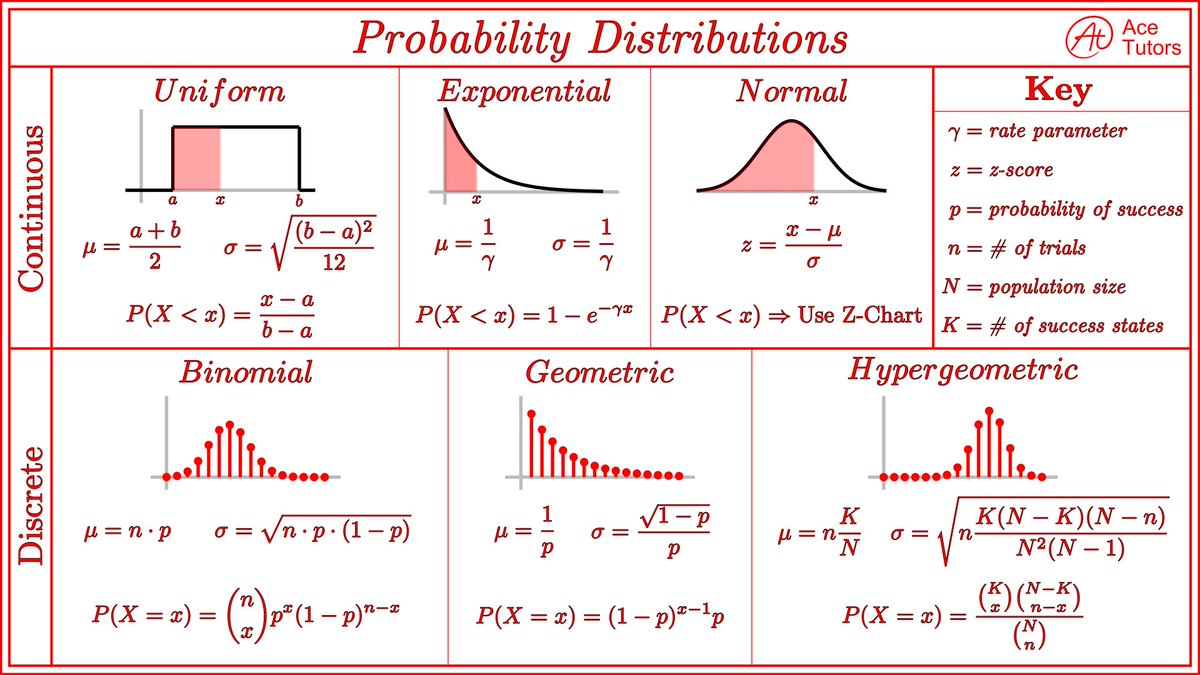
Data science killed itself.
Not because AI showed up. Because too much of the field confused running a model with understanding one.
Not because AI showed up. Because too much of the field confused running a model with understanding one.
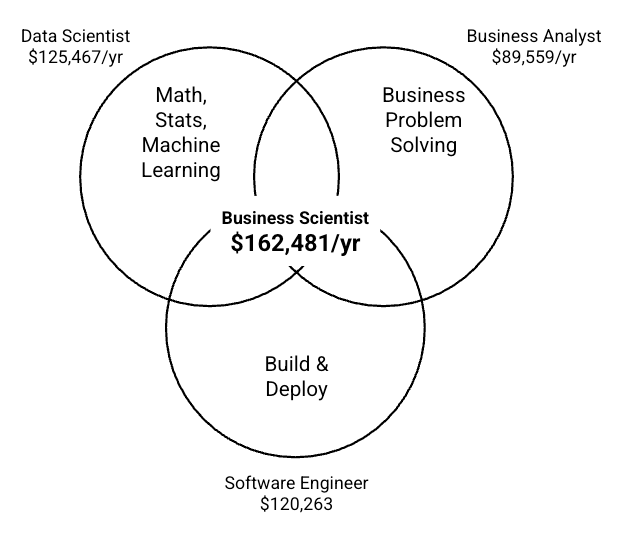
For years, data science rewarded people for producing outputs:
A model score
A dashboard
A notebook
A prediction
A nice chart
And a lot of that work looked impressive.
A model score
A dashboard
A notebook
A prediction
A nice chart
And a lot of that work looked impressive.
But underneath it, there was a problem:
No understanding of the business value (or lack of) it generated.
No understanding of the business value (or lack of) it generated.
That happened enough times that businesses started losing trust.
And once that happens, the market shifted. It stopped rewarding people for producing analysis.
It started rewarding people for producing outcomes.
And once that happens, the market shifted. It stopped rewarding people for producing analysis.
It started rewarding people for producing outcomes.
That is the future. Not the person who can talk about data science. The person who can turn it into action.
That is why I believe the safest and most valuable path now is NOT becoming a better “data scientist” in the traditional sense.
It is becoming a Business Scientist.
That is why I believe the safest and most valuable path now is NOT becoming a better “data scientist” in the traditional sense.
It is becoming a Business Scientist.
In 2026, the Business Scientist is someone who combines:
1. Statistics
2. Machine learning
3. AI
4. Coding
5. Business Value
6. Implementation
To build business solutions that actually get used.
That is much harder to replace.
1. Statistics
2. Machine learning
3. AI
4. Coding
5. Business Value
6. Implementation
To build business solutions that actually get used.
That is much harder to replace.
🚨 Want to learn how to build + ship AI and Data Science projects (that businesses actually want)?
On April 1st, I am hosting a free workshop to help you get started with AI + DS projects in Python.
Register here (500 seats):  learn.business-science.io/join
On April 1st, I am hosting a free workshop to help you get started with AI + DS projects in Python.
Register here (500 seats):  learn.business-science.io/join

• • •
Missing some Tweet in this thread? You can try to
force a refresh