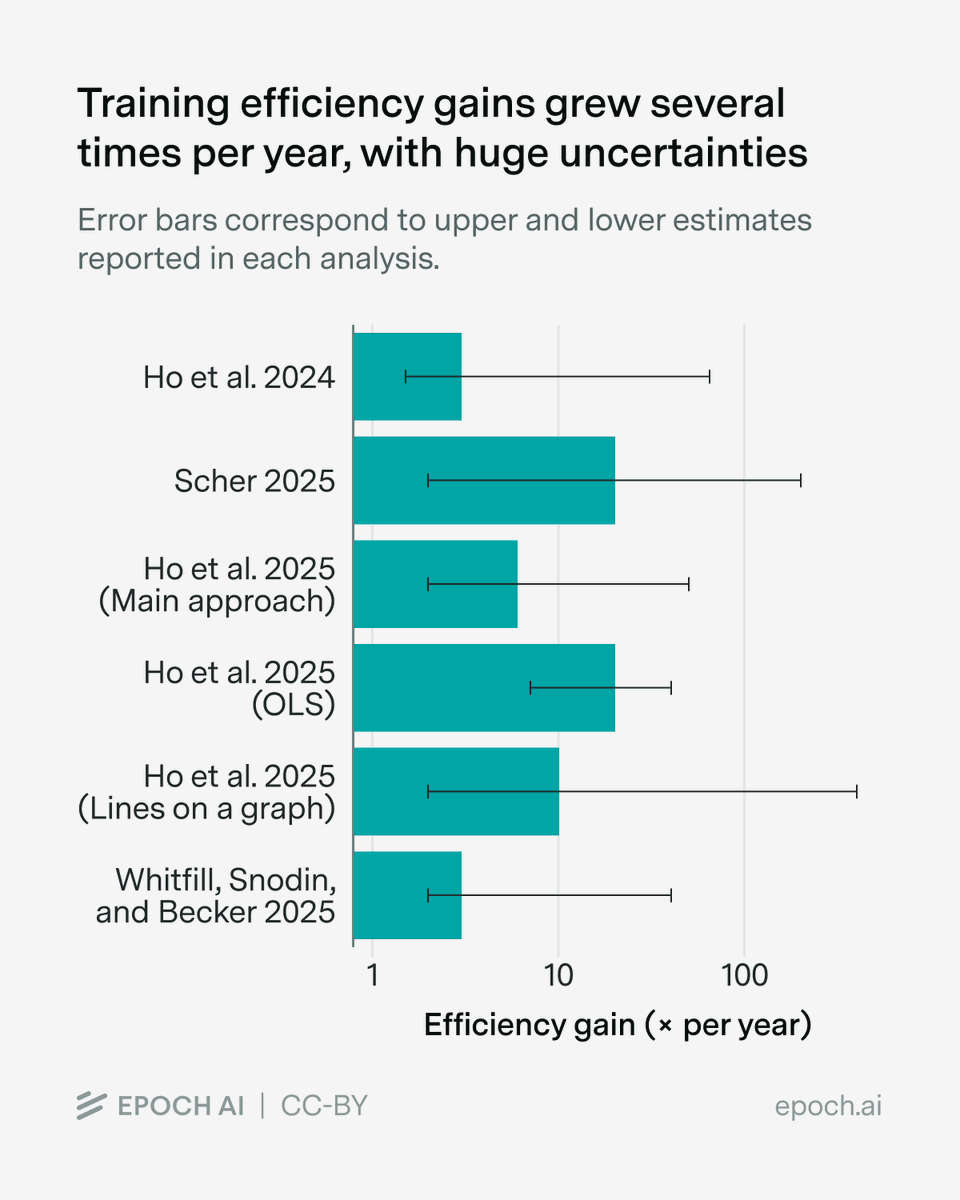Compute may be the most important input to AI. So who owns the world’s AI compute?
Introducing our new AI Chip Owners explorer, showing our analysis of how leading AI chips are distributed among hyperscalers and other major players, broken down by chip type over time.
Introducing our new AI Chip Owners explorer, showing our analysis of how leading AI chips are distributed among hyperscalers and other major players, broken down by chip type over time.
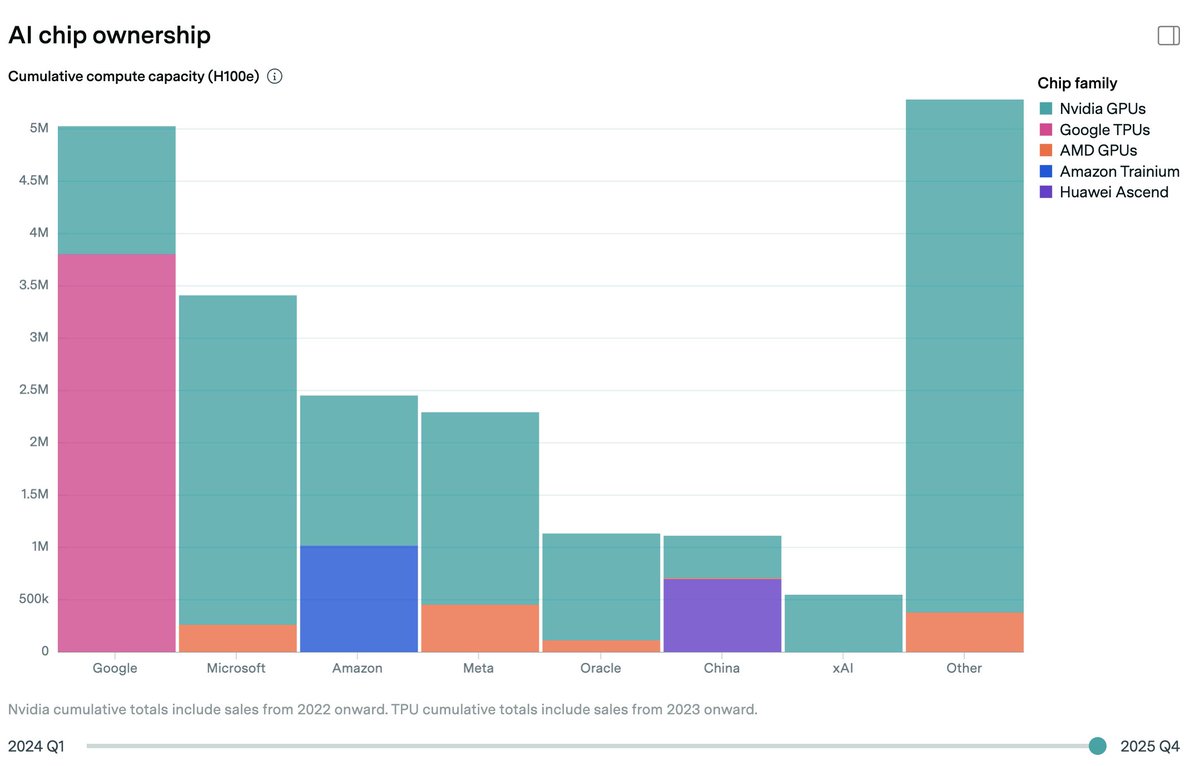
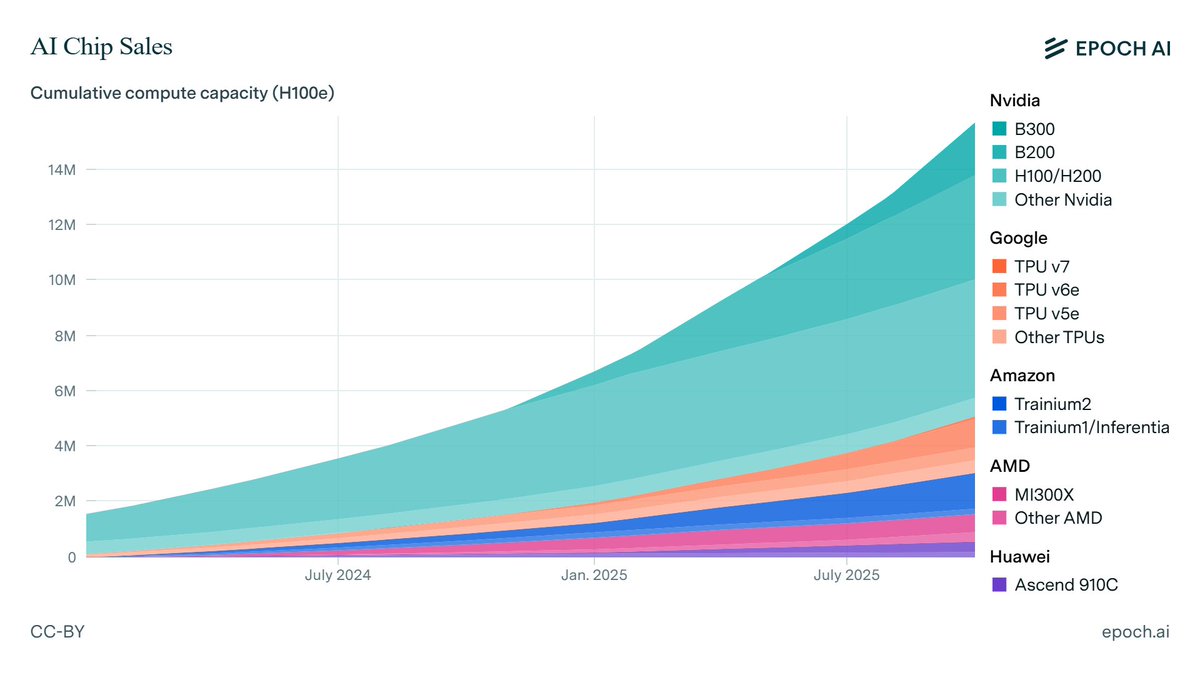
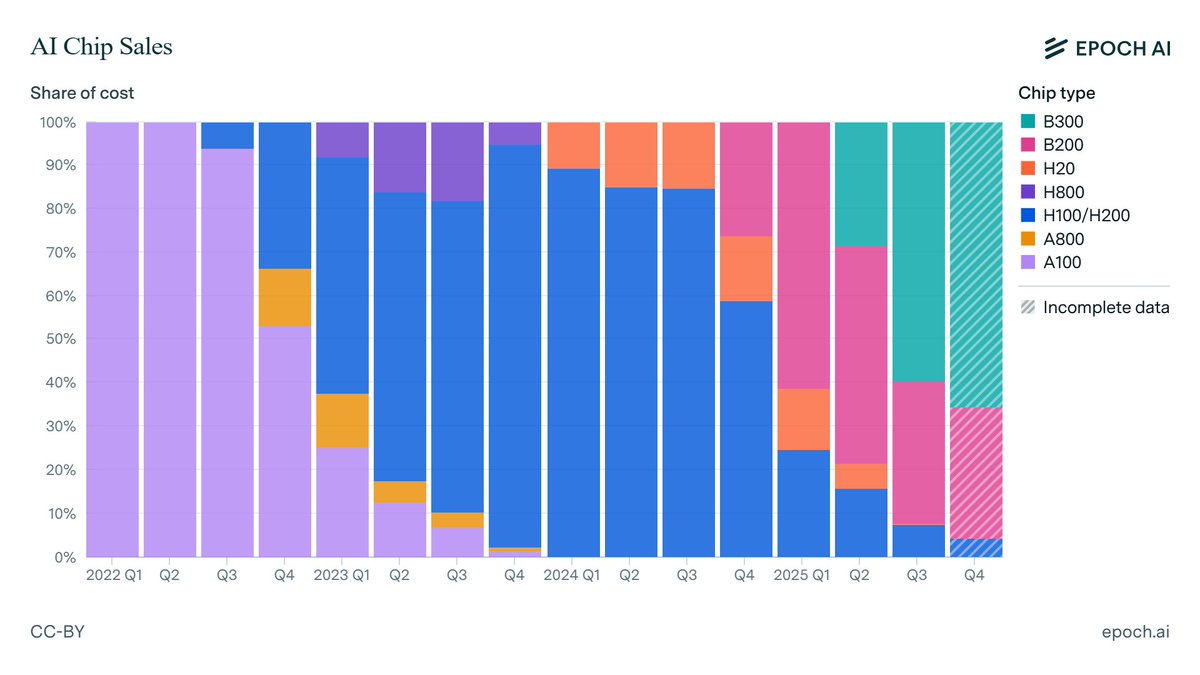
To estimate global compute ownership, we build on our previous estimates of overall AI chip sales. We then use earnings commentary from chipmakers and hyperscalers, as well as media reports and industry researcher estimates, to allocate chips across owners.

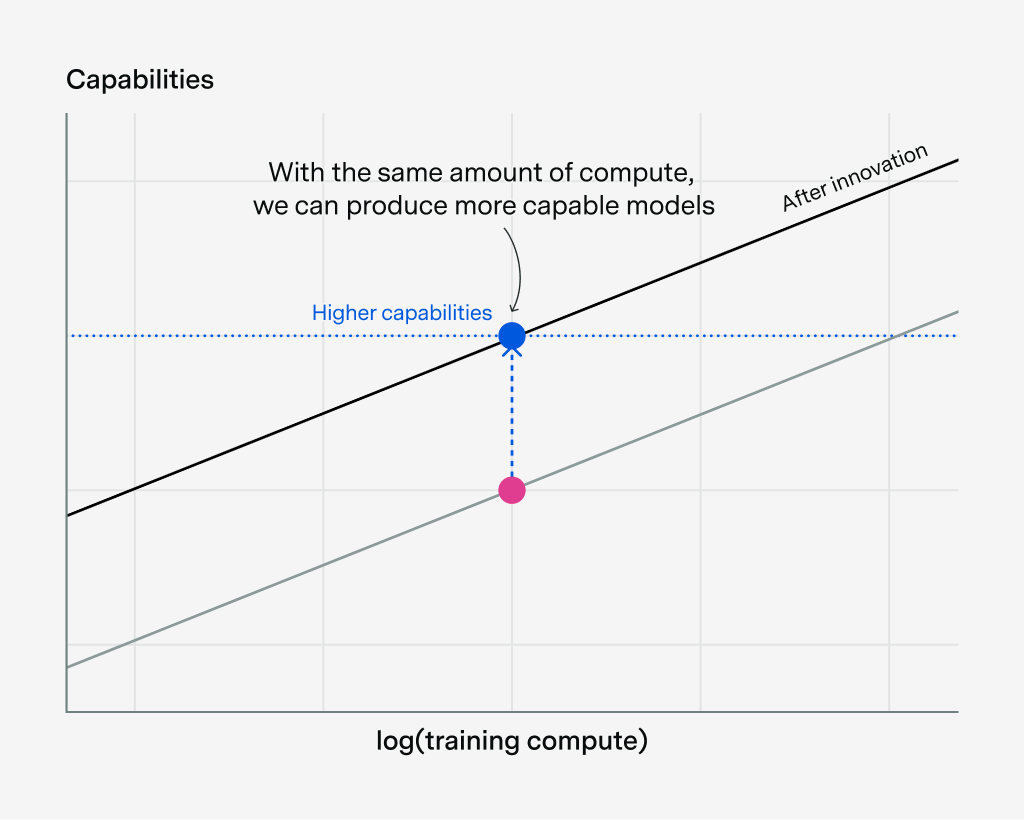
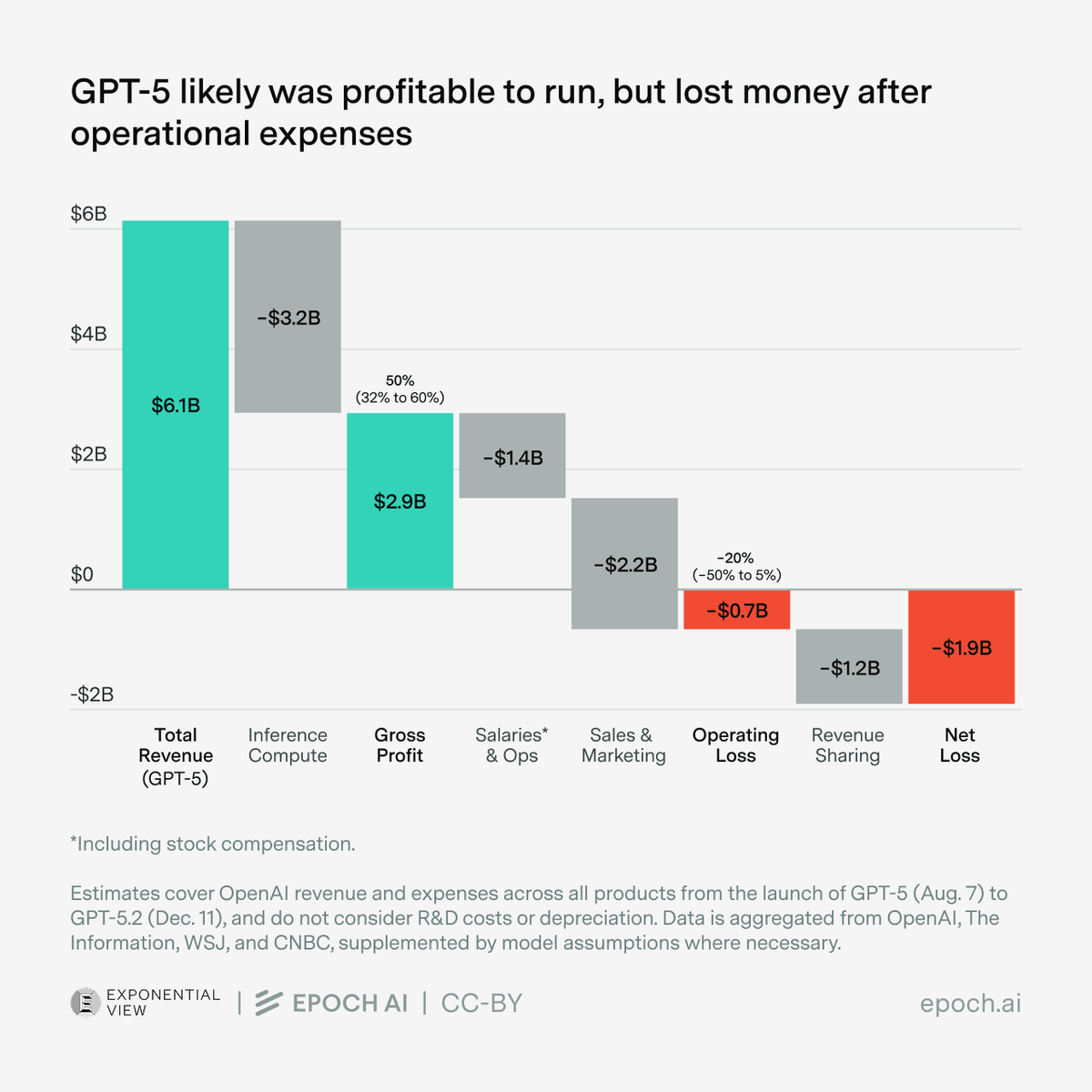
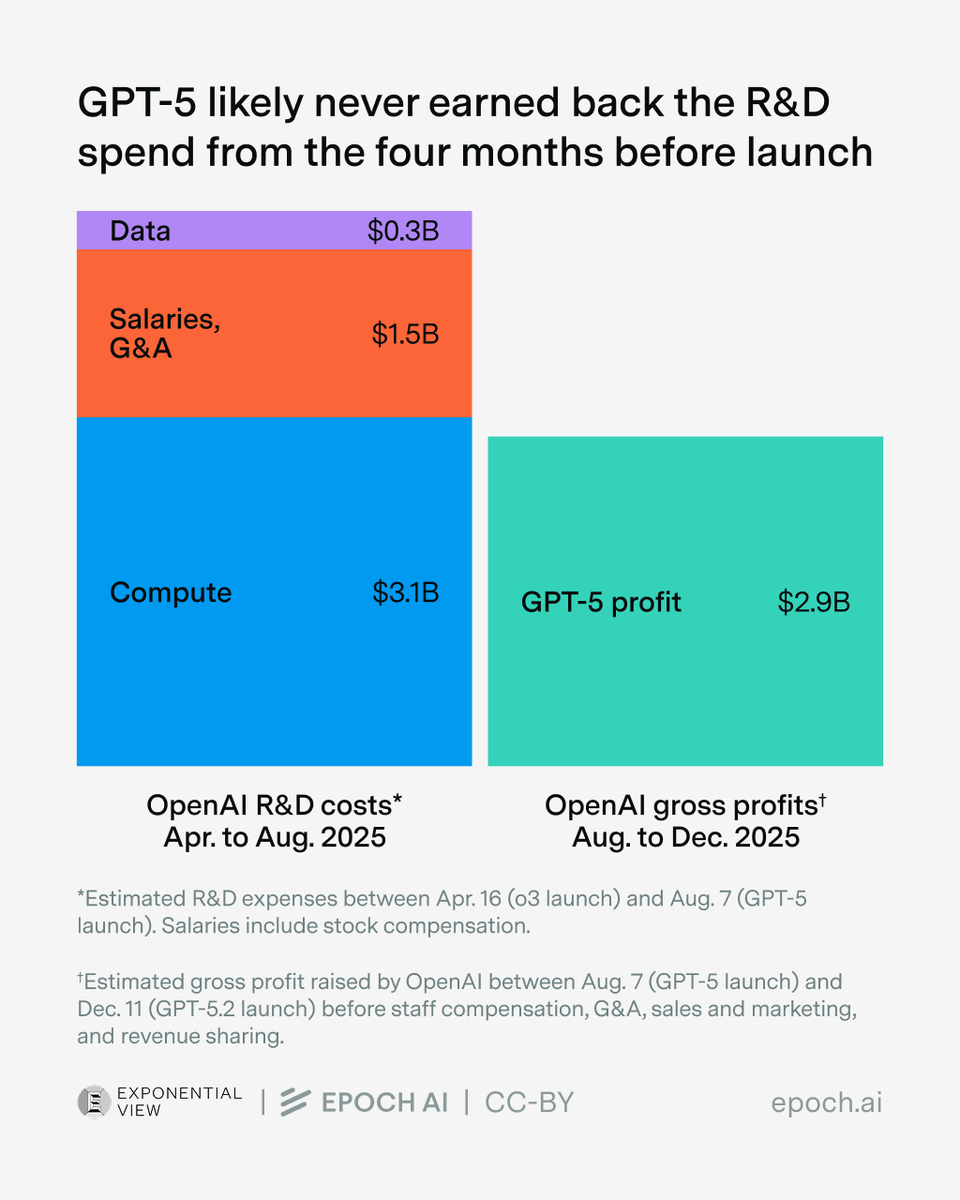
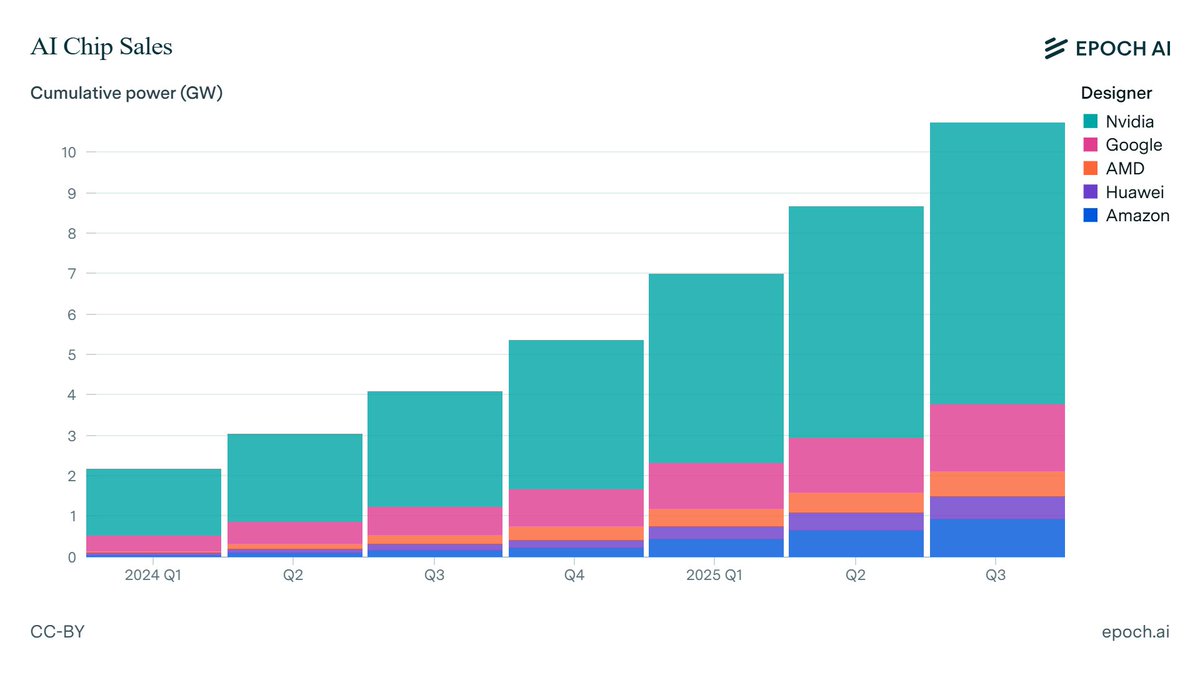
We estimate that over 60% of global AI compute is owned by the top US hyperscalers, led by Google with the equivalent of roughly 5 million Nvidia H100 GPUs!
Unlike the other hyperscalers, which rely primarily on Nvidia, Google’s fleet is dominated by its custom TPU chips.
Unlike the other hyperscalers, which rely primarily on Nvidia, Google’s fleet is dominated by its custom TPU chips.

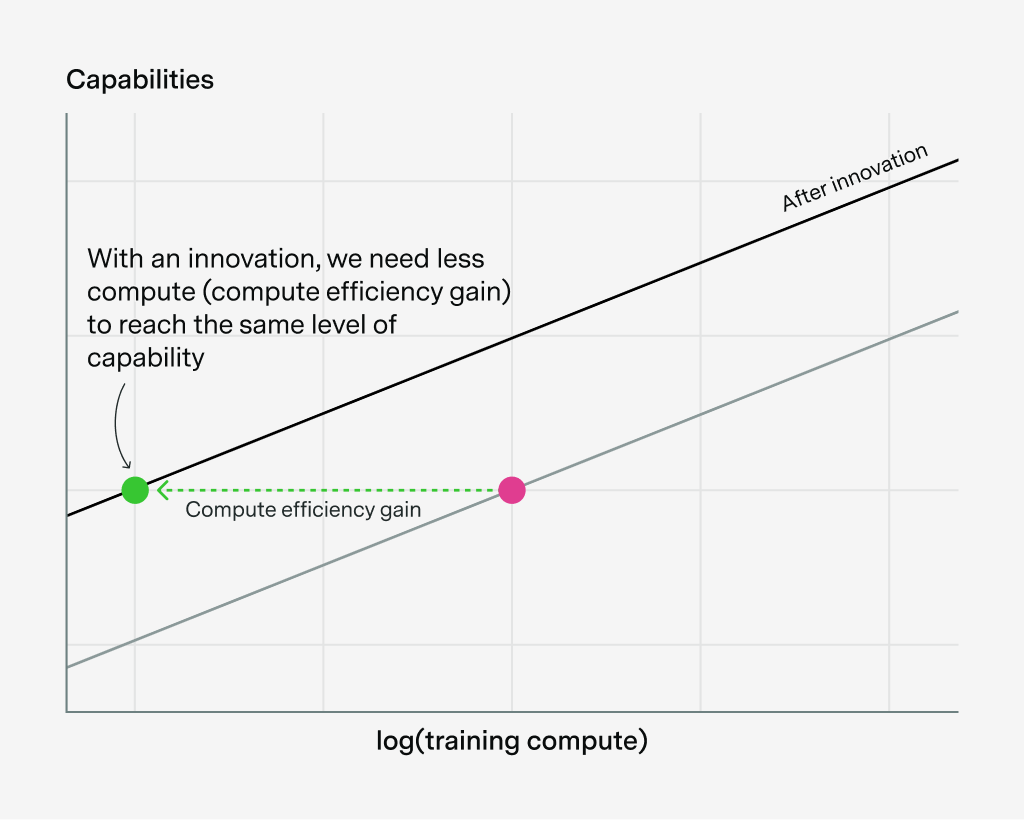
Chinese companies collectively own just over 5% of global AI compute — less than any single top US hyperscaler, and decreasing over time due to export controls.
This excludes smuggled chips, which reporting suggests are significant but unlikely to meaningfully close the gap.
This excludes smuggled chips, which reporting suggests are significant but unlikely to meaningfully close the gap.
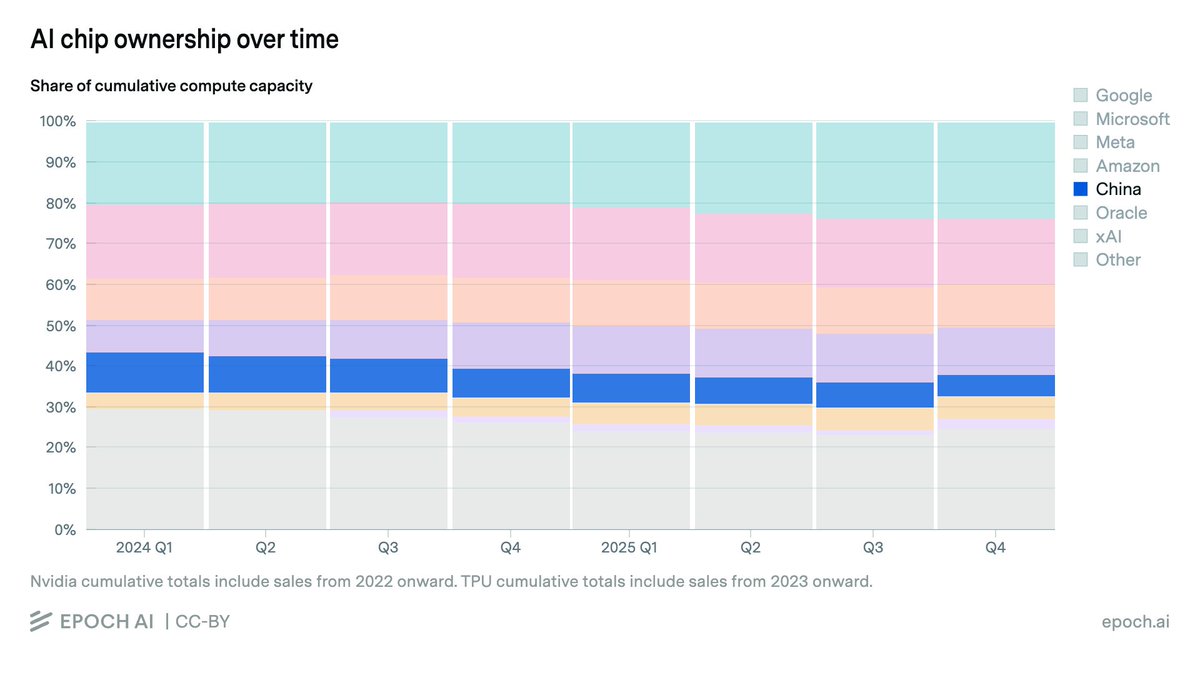
Notably, Nvidia’s official exports to China were largely paused in early 2025 due to export controls, slowing China’s compute purchases. Huawei has now overtaken Nvidia as the leading source of AI computing power in China, at least in terms of aggregate compute specs on paper.
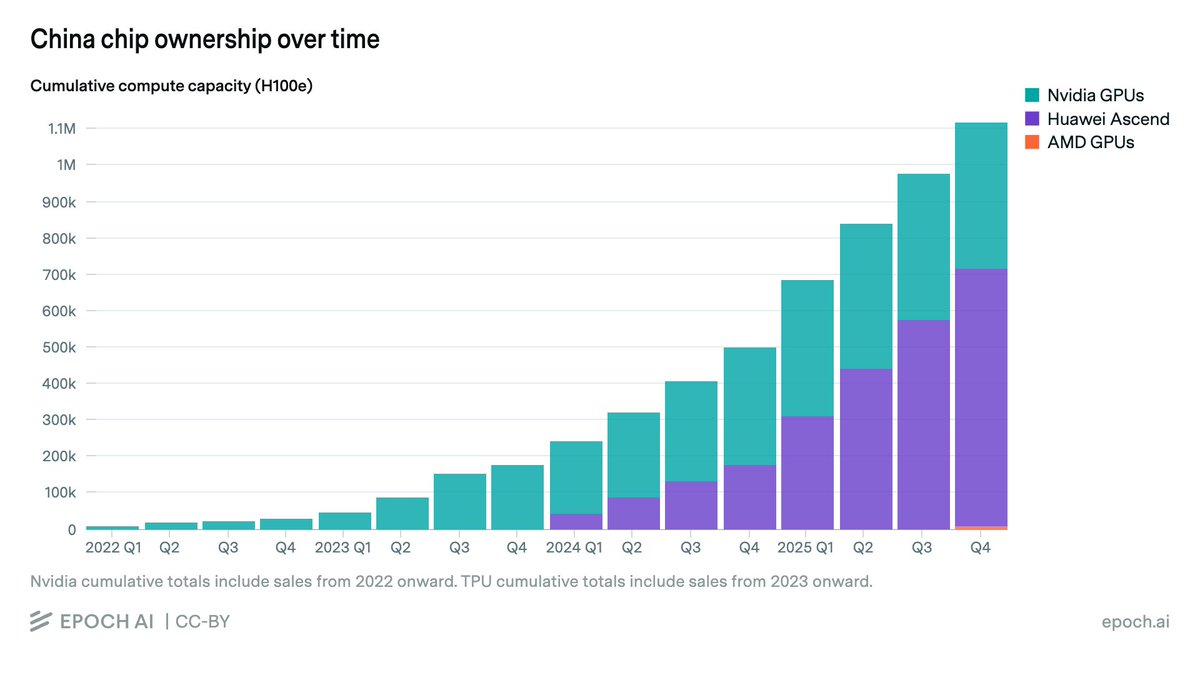
We plan to expand our coverage of AI chip owners and global compute over time. See detailed breakdowns by company, chip family, and model, plus a full methodology, in our AI Chip Owners explorer!
epoch.ai/data/ai-chip-o…
epoch.ai/data/ai-chip-o…
• • •
Missing some Tweet in this thread? You can try to
force a refresh