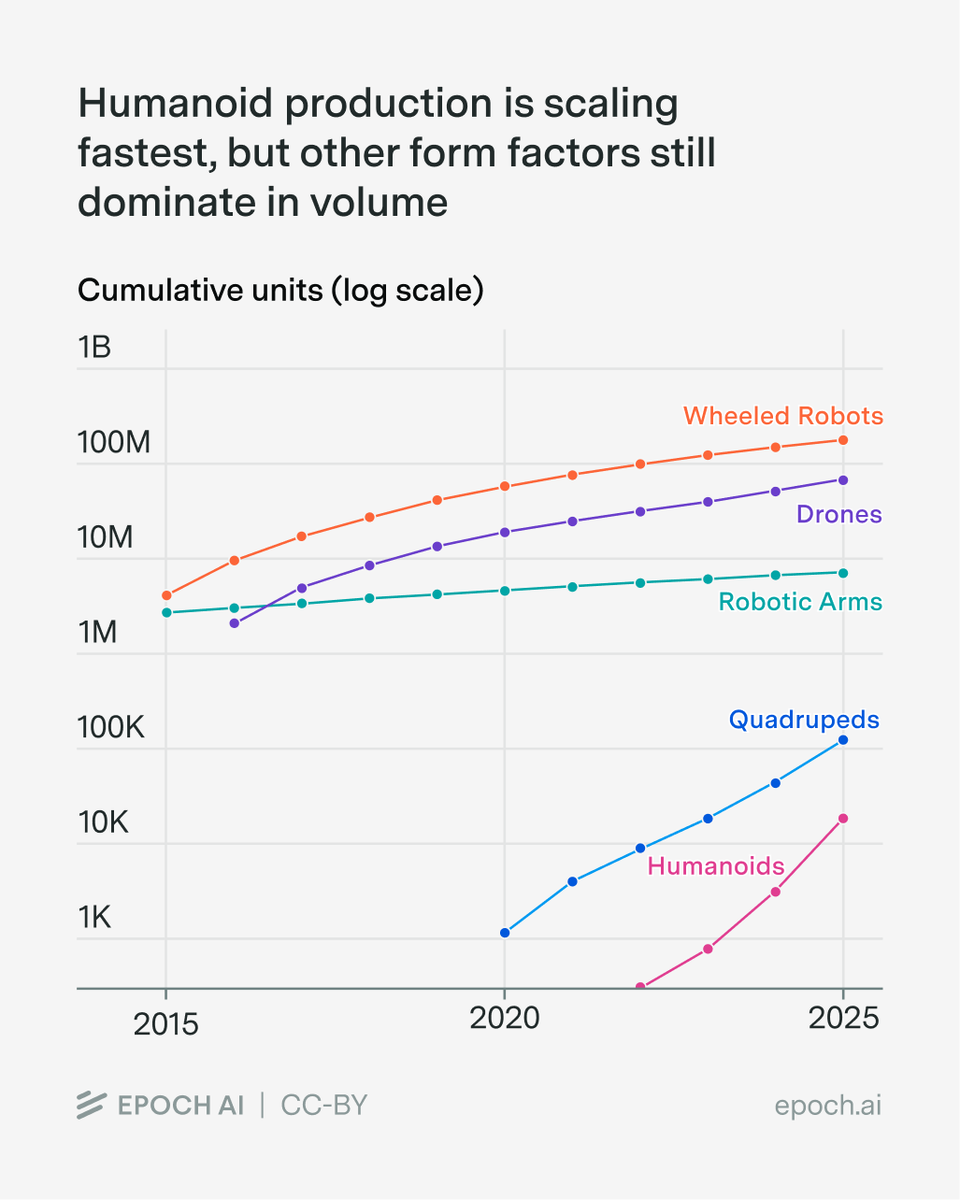
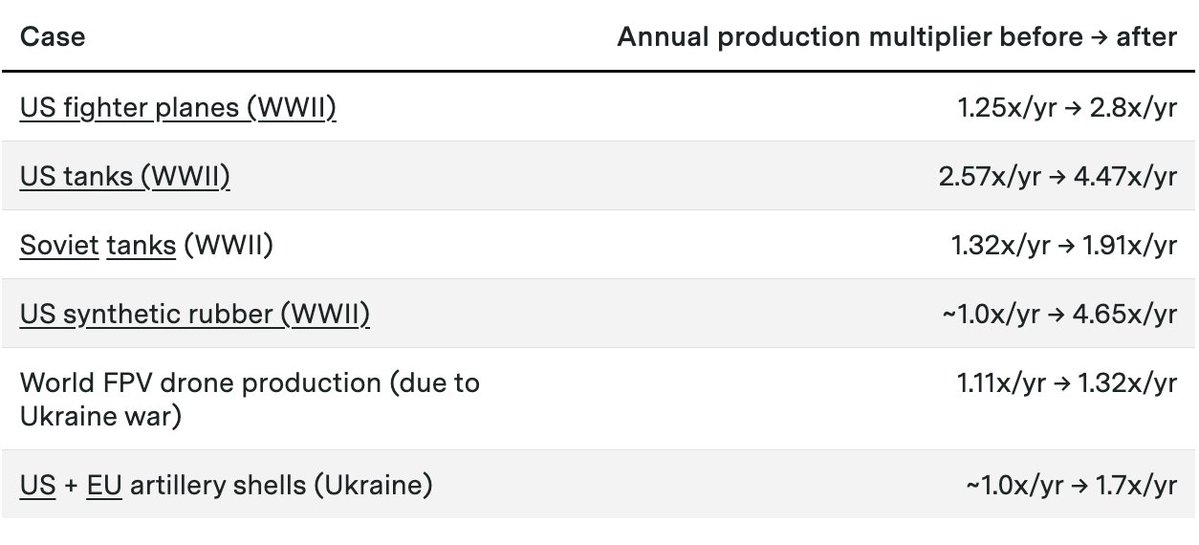
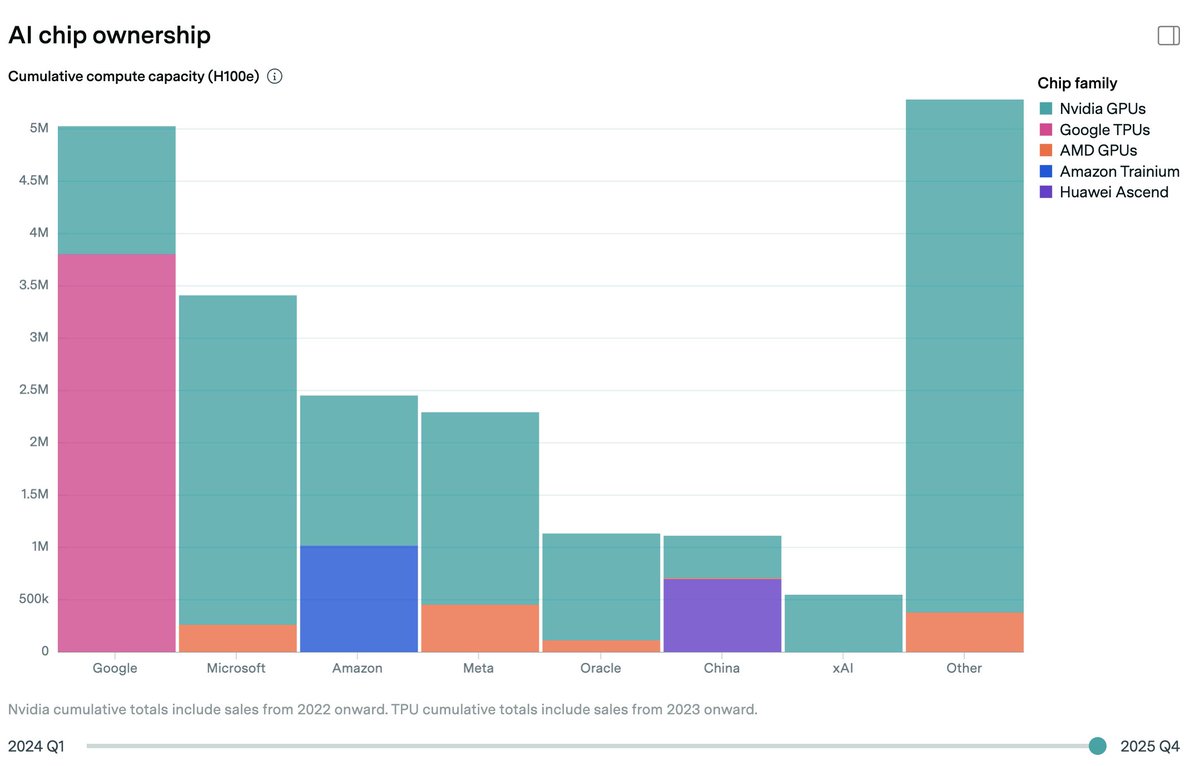
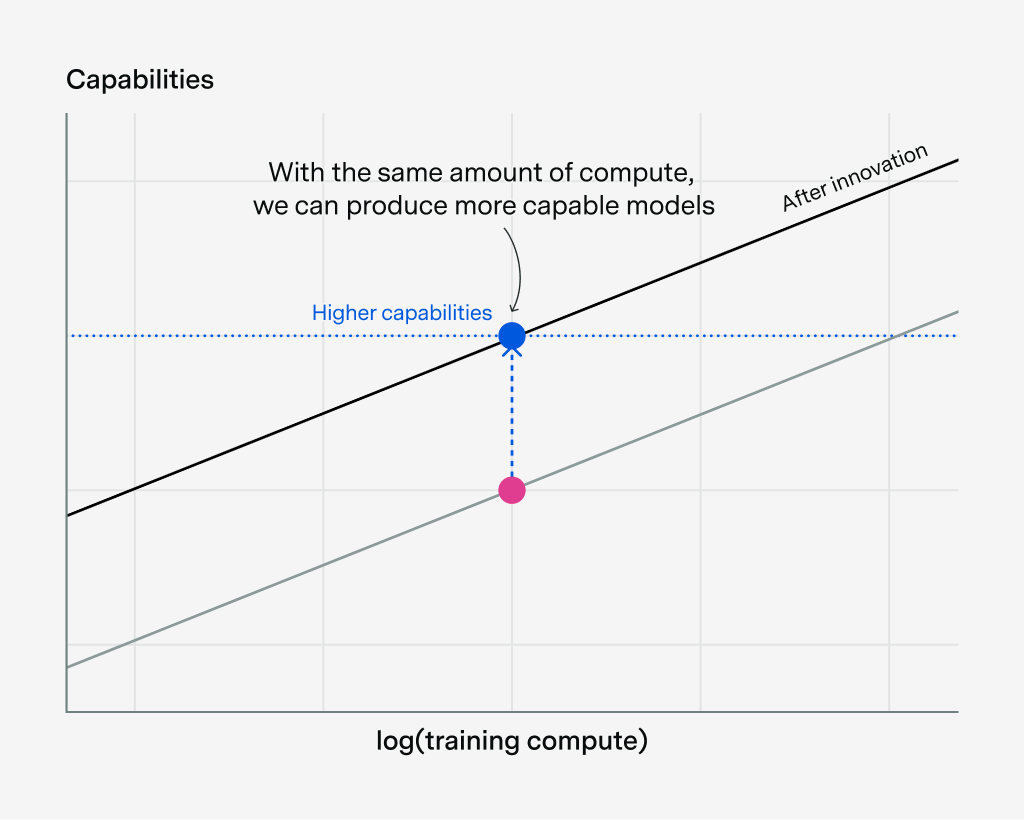
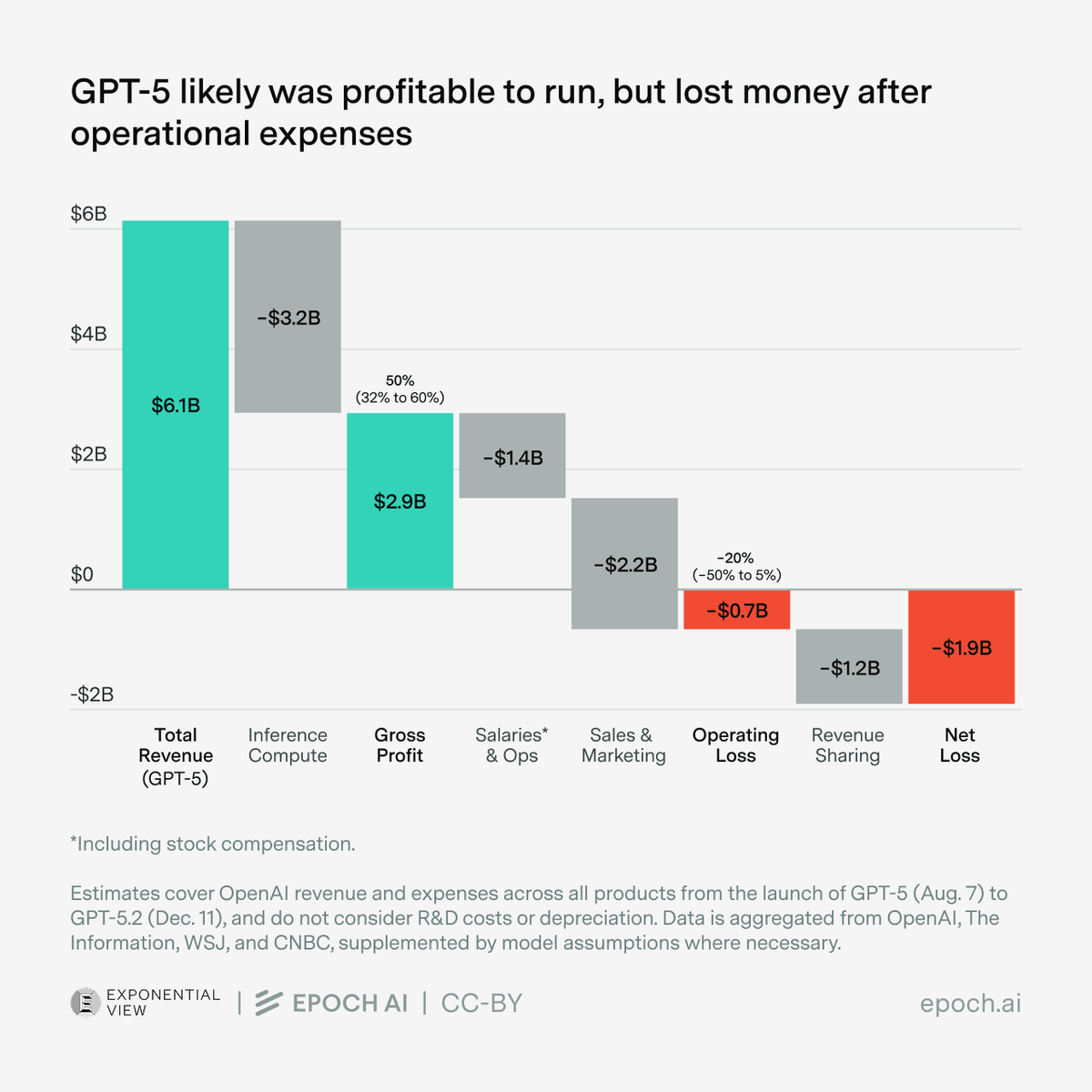
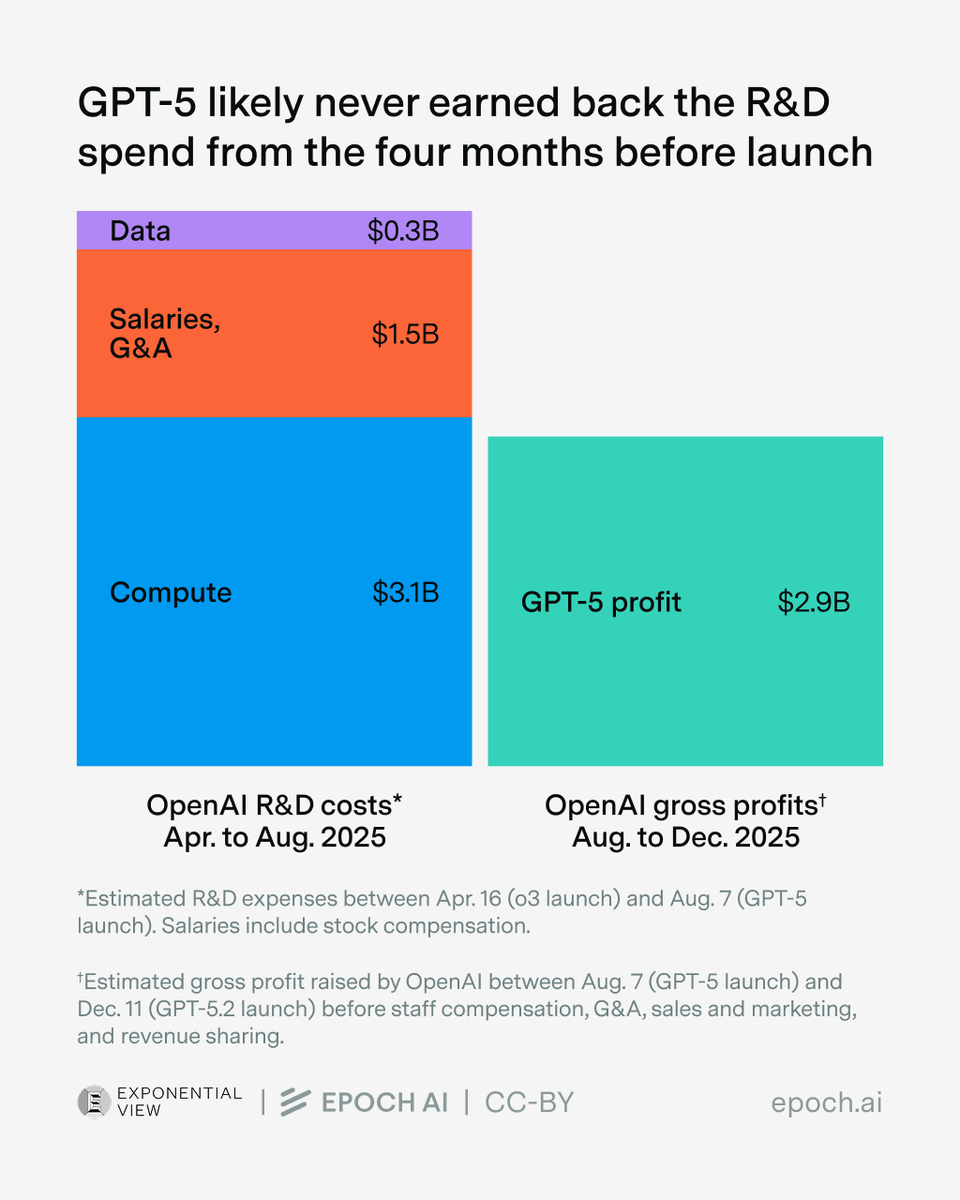
The Iran War and Hormuz shutdown have disrupted oil, gas, and helium exports and threatened data centers and investments in the Gulf states.
@justjoshinyou13 explores how a prolonged Iran war could affect AI, and why it probably won’t completely derail the compute buildout.
@justjoshinyou13 explores how a prolonged Iran war could affect AI, and why it probably won’t completely derail the compute buildout.
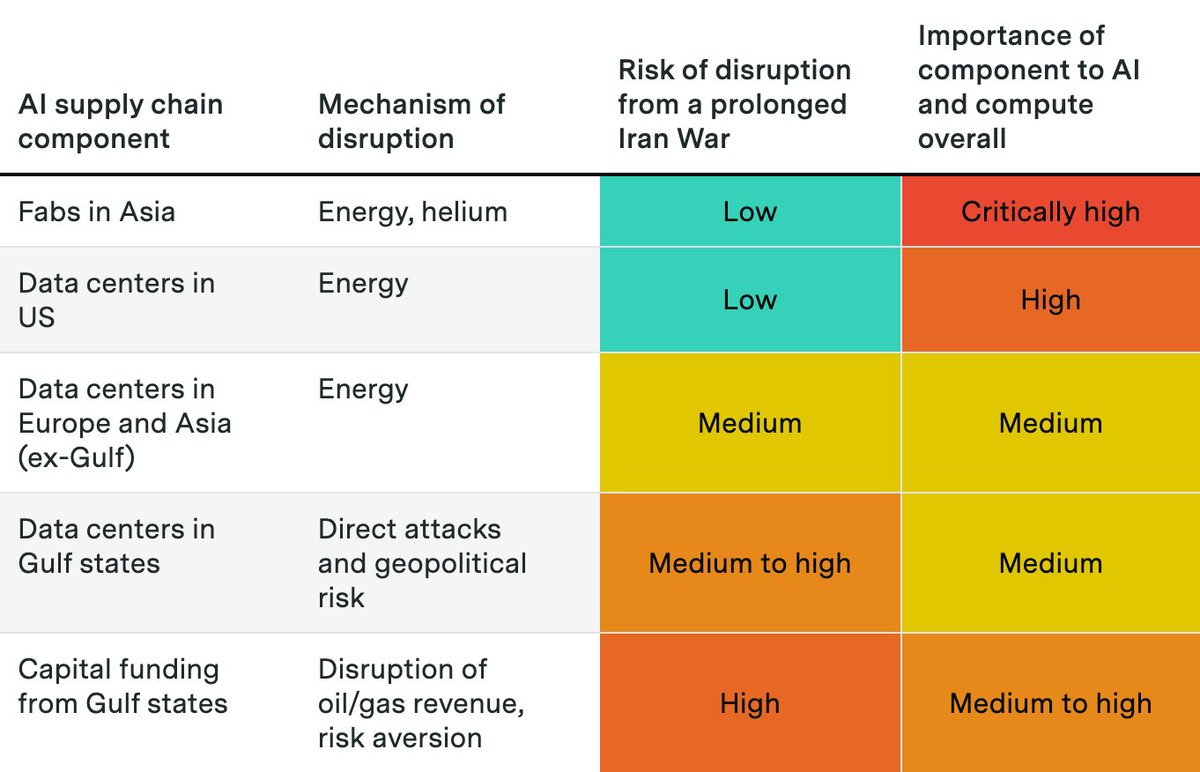
Fabrication of AI chips and memory is concentrated in Taiwan and South Korea. These fabs rely on energy from natural gas as well as helium, both disrupted by the Hormuz closure.
But chip fabs are so profitable that TSMC and others will likely secure the resources they need.
But chip fabs are so profitable that TSMC and others will likely secure the resources they need.
For AI data centers, the Hormuz energy shock is not a serious threat in the US, where natural gas prices have been stable.
In Europe and Asia, higher costs may kill some planned data centers, but existing data centers will keep running unless prices surge to much higher levels.
In Europe and Asia, higher costs may kill some planned data centers, but existing data centers will keep running unless prices surge to much higher levels.
The most serious impacts might occur in the Gulf monarchies. Iran has threatened and directly attacked data centers, which could affect planned projects like Stargate UAE.
Perhaps more importantly, the shock to oil exports could cut off Gulf capital flows to AI, including upcoming IPOs.
Perhaps more importantly, the shock to oil exports could cut off Gulf capital flows to AI, including upcoming IPOs.
This Gradient Update was written by @justjoshinyou13. All Gradient Updates are informal and opinionated analyses that represent the views of individual authors, not Epoch AI as a whole.
Read the full post here:
epoch.ai/gradient-updat…
Read the full post here:
epoch.ai/gradient-updat…
• • •
Missing some Tweet in this thread? You can try to
force a refresh