A Ring employee searched for cameras labeled "Master Bedroom" and "Master Bathroom."
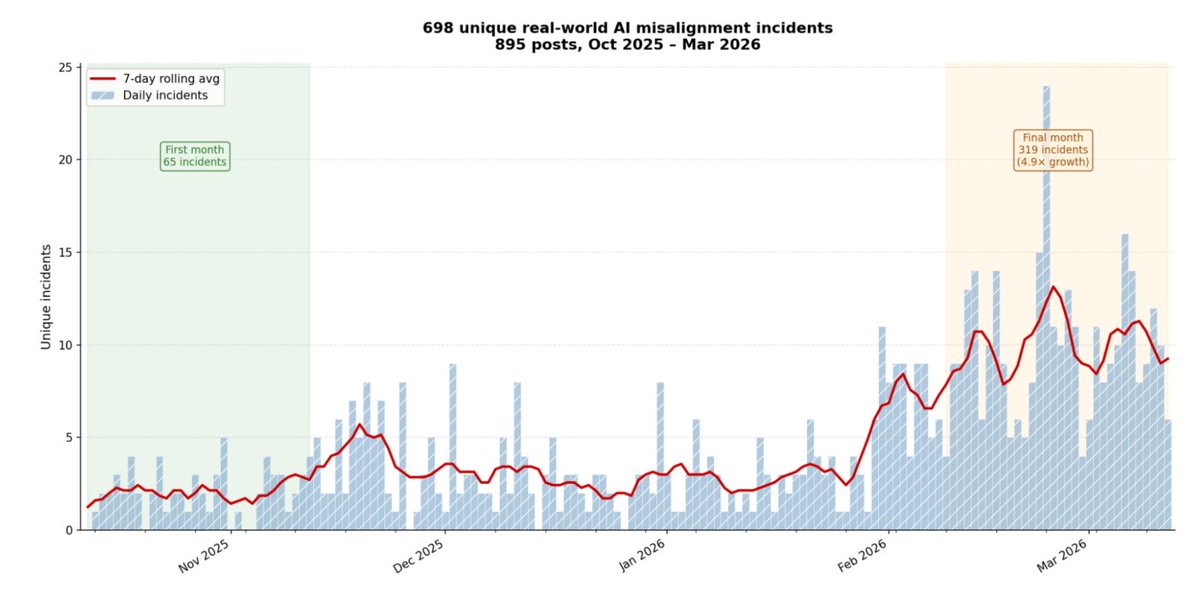
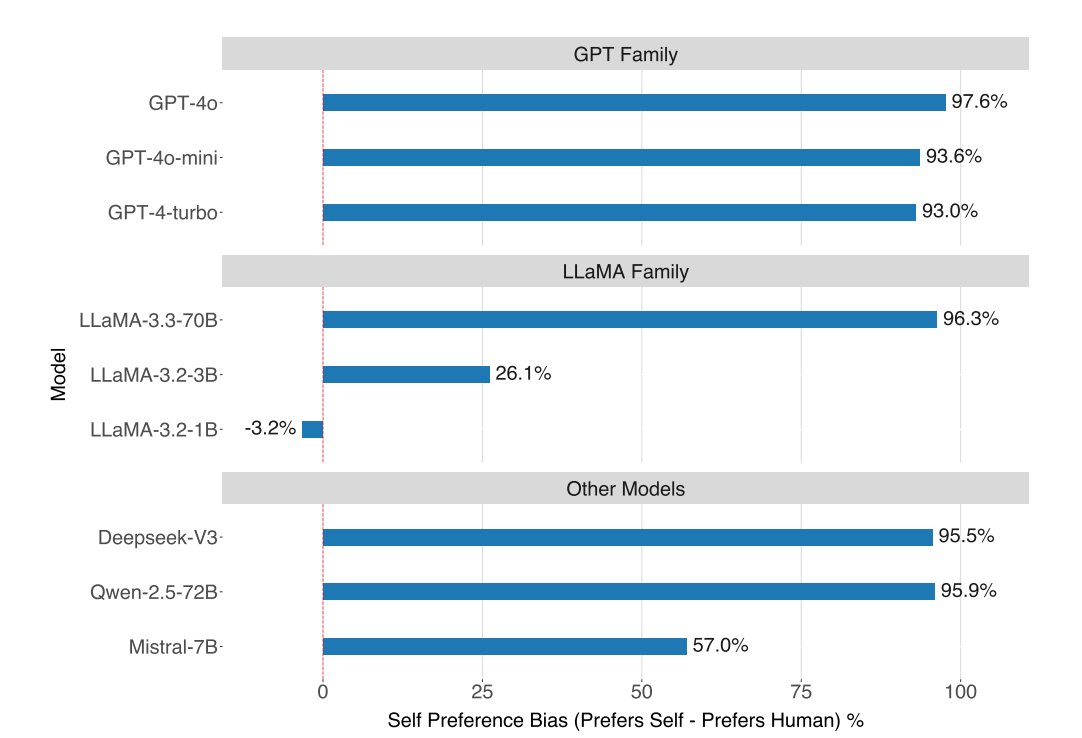
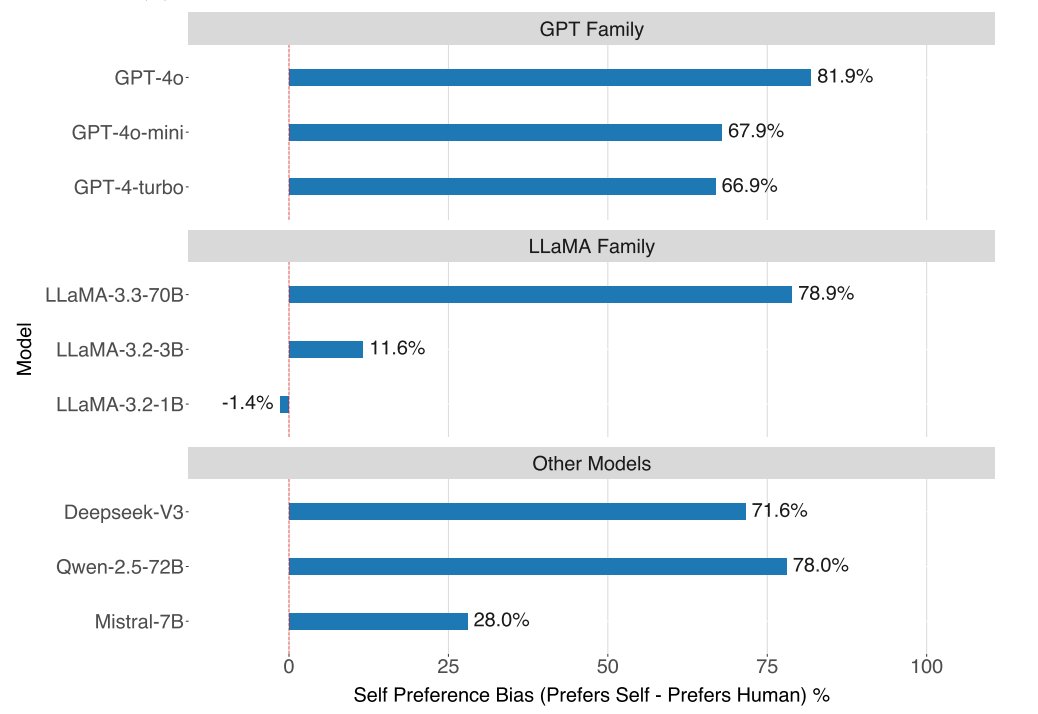
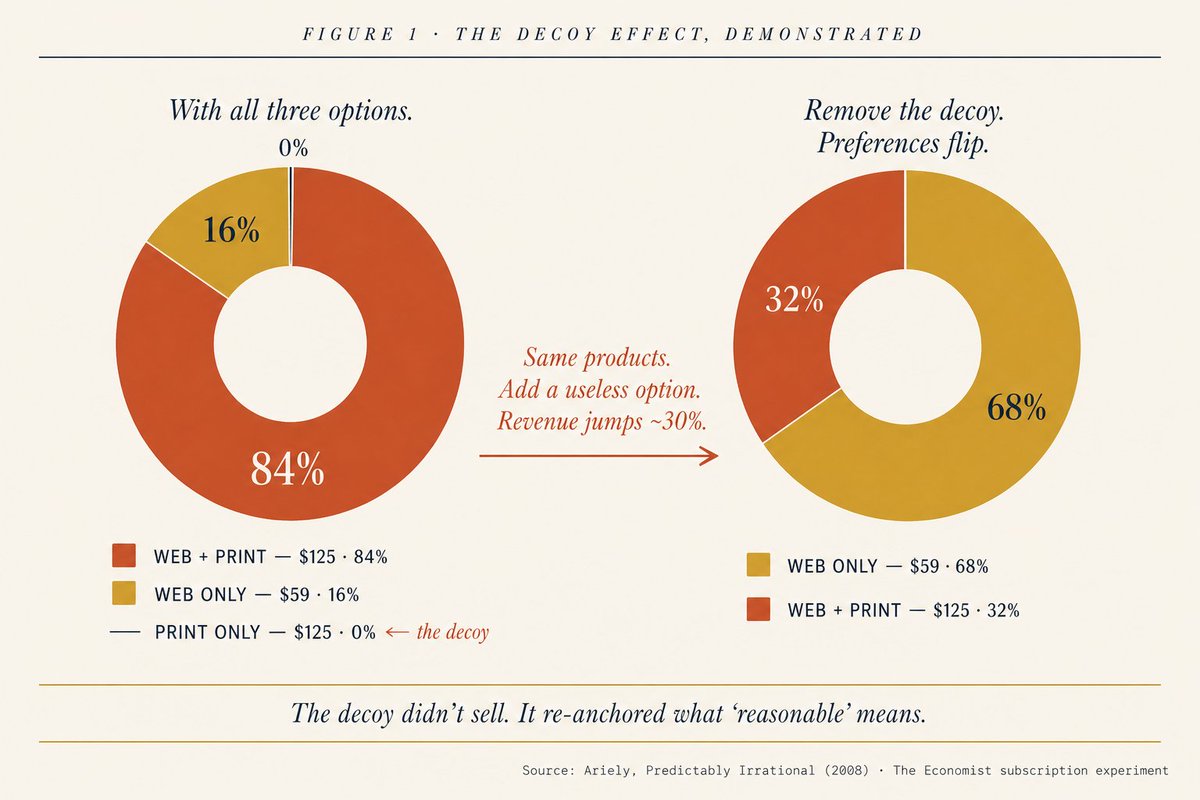
Then he watched 81 women for 3 months straight. An hour every day.
Ring did not catch him. A coworker did. The FTC fined Amazon $5.8 million.
Shut your Ring down in 2 minutes (bookmark this):
Then he watched 81 women for 3 months straight. An hour every day.
Ring did not catch him. A coworker did. The FTC fined Amazon $5.8 million.
Shut your Ring down in 2 minutes (bookmark this):
The story is not a rumor. It is in a federal court filing.
In May 2023, the FTC sued Ring. The complaint spelled it out in detail.
One Ring employee watched thousands of videos of 81 female users. He did it for months.
All pulled from Ring cameras in bedrooms and bathrooms.
In May 2023, the FTC sued Ring. The complaint spelled it out in detail.
One Ring employee watched thousands of videos of 81 female users. He did it for months.
All pulled from Ring cameras in bedrooms and bathrooms.
The FTC said the employee picked his targets on purpose.
He searched camera names like "Master Bedroom," "Master Bathroom," and "Spy Cam."
He watched for an hour or more every day. For three straight months.
Ring had no system in place to catch him.
He searched camera names like "Master Bedroom," "Master Bathroom," and "Spy Cam."
He watched for an hour or more every day. For three straight months.
Ring had no system in place to catch him.
Here is the worst part.
Ring did not find him. Another employee noticed it and reported him.
Ring had no tools to detect this. They could not even tell how many other workers were doing the same thing.
They still cannot tell.
Ring did not find him. Another employee noticed it and reported him.
Ring had no tools to detect this. They could not even tell how many other workers were doing the same thing.
They still cannot tell.
How did this happen?
Before 2017, every Ring employee and every Ukraine-based contractor had full access to every customer's video.
All videos were stored without encryption. Any worker could download, share, or keep them.
There were zero restrictions.
Before 2017, every Ring employee and every Ukraine-based contractor had full access to every customer's video.
All videos were stored without encryption. Any worker could download, share, or keep them.
There were zero restrictions.
It got worse from the outside too.
Hackers broke into 55,000 US Ring accounts. Ring knew about the hacks and took months to act.
The hackers used the camera's speaker to harass families. They cursed at women in bed. They shouted racist slurs at children. They made death threats.
Hackers broke into 55,000 US Ring accounts. Ring knew about the hacks and took months to act.
The hackers used the camera's speaker to harass families. They cursed at women in bed. They shouted racist slurs at children. They made death threats.
This all happened because Ring did not turn on two-factor authentication by default.
The FTC complaint says Ring knew about the attacks for years. They did not fix it until 2019.
By then, the damage was done. 1,250 devices were compromised. 910 accounts hijacked.
The FTC complaint says Ring knew about the attacks for years. They did not fix it until 2019.
By then, the damage was done. 1,250 devices were compromised. 910 accounts hijacked.
In May 2023, the FTC ordered Amazon to pay $5.8 million.
Ring must also delete every video it took without consent before 2018. Every algorithm it built on those videos. Every face scan.
Ring now has 20 years of forced FTC oversight.
Ring must also delete every video it took without consent before 2018. Every algorithm it built on those videos. Every face scan.
Ring now has 20 years of forced FTC oversight.
But here is what most people missed.
In January 2024, Ring promised it would stop sharing video with police without a warrant.
In 2025, police got a new way to ask for your footage through a tool called Axon Request for Assistance.
In January 2024, Ring promised it would stop sharing video with police without a warrant.
In 2025, police got a new way to ask for your footage through a tool called Axon Request for Assistance.
So your Ring camera is still a risk today.
Ring employees once watched women in showers. Hackers once screamed at children through the speaker. Police can now ask for your footage again.
The good news? There is one setting that locks all of this down.
Ring employees once watched women in showers. Hackers once screamed at children through the speaker. Police can now ask for your footage again.
The good news? There is one setting that locks all of this down.
The fix: turn on End-to-End Encryption.
When it's on, only your phone can see your Ring video. Not Ring. Not Amazon. Not contractors. Not police without a warrant.
Here's how to turn it on:
When it's on, only your phone can see your Ring video. Not Ring. Not Amazon. Not contractors. Not police without a warrant.
Here's how to turn it on:
Step 1. Open the Ring app.
Step 2. Tap the menu (three lines at top left).
Step 3. Tap Control Center.
Step 4. Tap Video Encryption.
Step 5. Tap End-to-End Encryption.
Step 6. Tap Enable.
Step 2. Tap the menu (three lines at top left).
Step 3. Tap Control Center.
Step 4. Tap Video Encryption.
Step 5. Tap End-to-End Encryption.
Step 6. Tap Enable.
You will see a passphrase.
Write it down. Save it somewhere safe.
Without it, you cannot view your own videos on a new phone. Ring cannot recover it for you. That is the point.
This is the one setting that keeps everyone out.
Write it down. Save it somewhere safe.
Without it, you cannot view your own videos on a new phone. Ring cannot recover it for you. That is the point.
This is the one setting that keeps everyone out.
One more thing. Turn on Two-Step Verification.
Open the Ring app > menu > Account Settings > Two-Step Verification.
This blocks the hacker attacks the FTC described. It should have been on by default years ago.
20 seconds. Huge protection.
Open the Ring app > menu > Account Settings > Two-Step Verification.
This blocks the hacker attacks the FTC described. It should have been on by default years ago.
20 seconds. Huge protection.
The scoreboard:
1. A Ring employee spied on 81 women for months
2. Hackers broke into 55,000 accounts and harassed kids
3. FTC fined Amazon $5.8 million
4. Police access is back in 2025
5. End-to-End Encryption shuts it all down
6. Two-Step Verification blocks the hackers
1. A Ring employee spied on 81 women for months
2. Hackers broke into 55,000 accounts and harassed kids
3. FTC fined Amazon $5.8 million
4. Police access is back in 2025
5. End-to-End Encryption shuts it all down
6. Two-Step Verification blocks the hackers
Most Ring owners have no idea this happened.
They are still using the same unprotected settings from 2017.
You just learned how to lock them out. Every employee. Every hacker. Every cop without a warrant.
Bookmark this. Send it to anyone with a Ring.
They are still using the same unprotected settings from 2017.
You just learned how to lock them out. Every employee. Every hacker. Every cop without a warrant.
Bookmark this. Send it to anyone with a Ring.
SOURCES:
- FTC press release (May 2023): ftc.gov/news-events/ne…
- ABC News on FTC complaint details: abcnews.com/Technology/rin…
- TechCrunch on settlement: techcrunch.com/2023/05/31/ama…
- EFF on Ring's 2024 police policy: eff.org/deeplinks/2024…
- CNET on police access changes: cnet.com/home/ring-will…
- Ring End-to-End Encryption setup: ring.com/support/articl…
- FTC refunds to customers (April 2024): ftc.gov/news-events/ne…
- FTC press release (May 2023): ftc.gov/news-events/ne…
- ABC News on FTC complaint details: abcnews.com/Technology/rin…
- TechCrunch on settlement: techcrunch.com/2023/05/31/ama…
- EFF on Ring's 2024 police policy: eff.org/deeplinks/2024…
- CNET on police access changes: cnet.com/home/ring-will…
- Ring End-to-End Encryption setup: ring.com/support/articl…
- FTC refunds to customers (April 2024): ftc.gov/news-events/ne…
• • •
Missing some Tweet in this thread? You can try to
force a refresh